 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnySat: An Earth Observation Model for Any Resolutions, Scales, and Modalities
Dec 18, 2024



Geospatial models must adapt to the diversity of Earth observation data in terms of resolutions, scales, and modalities. However, existing approaches expect fixed input configurations, which limits their practical applicability. We propose AnySat, a multimodal model based on joint embedding predictive architecture (JEPA) and resolution-adaptive spatial encoders, allowing us to train a single model on highly heterogeneous data in a self-supervised manner. To demonstrate the advantages of this unified approach, we compile GeoPlex, a collection of $5$ multimodal datasets with varying characteristics and $11$ distinct sensors. We then train a single powerful model on these diverse datasets simultaneously. Once fine-tuned, we achieve better or near state-of-the-art results on the datasets of GeoPlex and $4$ additional ones for $5$ environment monitoring tasks: land cover mapping, tree species identification, crop type classification, change detection, and flood segmentation. The code and models are available at https://github.com/gastruc/AnySat.
OmniSat: Self-Supervised Modality Fusion for Earth Observation
Apr 12, 2024



The field of Earth Observations (EO) offers a wealth of data from diverse sensors, presenting a great opportunity for advancing self-supervised multimodal learning. However, current multimodal EO datasets and models focus on a single data type, either mono-date images or time series, which limits their expressivity. We introduce OmniSat, a novel architecture that exploits the spatial alignment between multiple EO modalities to learn expressive multimodal representations without labels. To demonstrate the advantages of combining modalities of different natures, we augment two existing datasets with new modalities. As demonstrated on three downstream tasks: forestry, land cover classification, and crop mapping. OmniSat can learn rich representations in an unsupervised manner, leading to improved performance in the semi- and fully-supervised settings, even when only one modality is available for inference. The code and dataset are available at github.com/gastruc/OmniSat.
BuyTheDips: PathLoss for improved topology-preserving deep learning-based image segmentation
Jul 23, 2022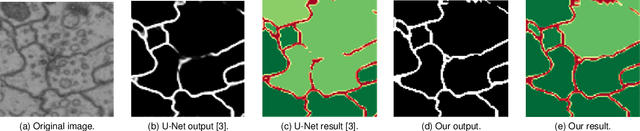
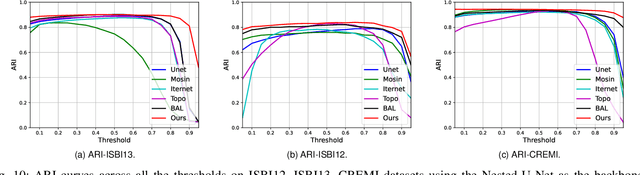
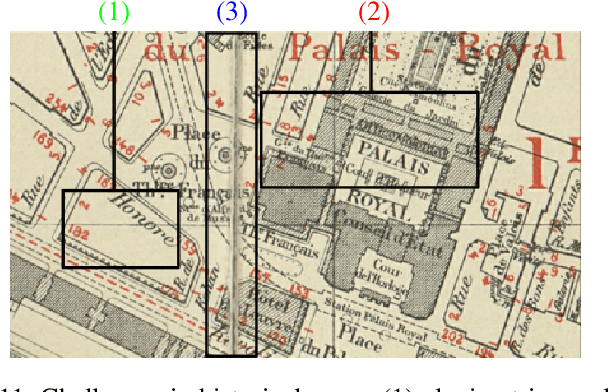
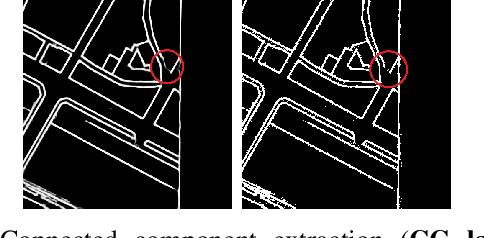
Capturing the global topology of an image is essential for proposing an accurate segmentation of its domain. However, most of existing segmentation methods do not preserve the initial topology of the given input, which is detrimental for numerous downstream object-based tasks. This is all the more true for deep learning models which most work at local scales. In this paper, we propose a new topology-preserving deep image segmentation method which relies on a new leakage loss: the Pathloss. Our method is an extension of the BALoss [1], in which we want to improve the leakage detection for better recovering the closeness property of the image segmentation. This loss allows us to correctly localize and fix the critical points (a leakage in the boundaries) that could occur in the predictions, and is based on a shortest-path search algorithm. This way, loss minimization enforces connectivity only where it is necessary and finally provides a good localization of the boundaries of the objects in the image. Moreover, according to our research, our Pathloss learns to preserve stronger elongated structure compared to methods without using topology-preserving loss. Training with our topological loss function, our method outperforms state-of-the-art topology-aware methods on two representative datasets of different natures: Electron Microscopy and Historical Map.