 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Annotations for Object Detection in Art through Stable Diffusion
Dec 09, 2024



Object detection in art is a valuable tool for the digital humanities, as it allows for faster identification of objects in artistic and historical images compared to humans. However, annotating such images poses significant challenges due to the need for specialized domain expertise. We present NADA (no annotations for detection in art), a pipeline that leverages diffusion models' art-related knowledge for object detection in paintings without the need for full bounding box supervision. Our method, which supports both weakly-supervised and zero-shot scenarios and does not require any fine-tuning of its pretrained components, consists of a class proposer based on large vision-language models and a class-conditioned detector based on Stable Diffusion. NADA is evaluated on two artwork datasets, ArtDL 2.0 and IconArt, outperforming prior work in weakly-supervised detection, while being the first work for zero-shot object detection in art. Code is available at https://github.com/patrick-john-ramos/nada
Context-Infused Visual Grounding for Art
Oct 16, 2024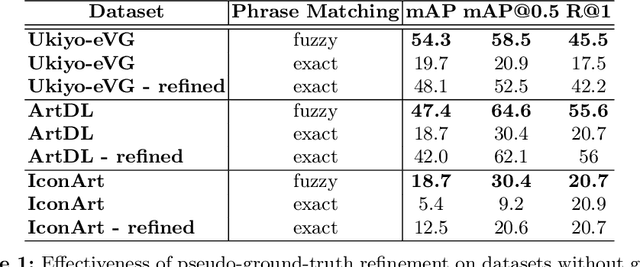

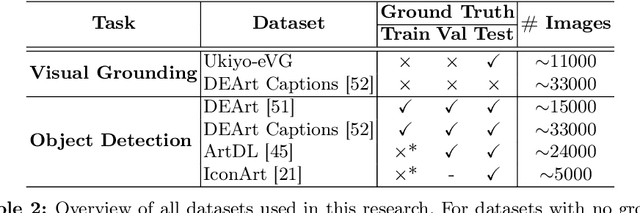
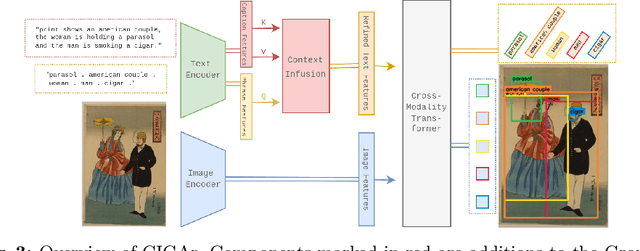
Many artwork collections contain textual attributes that provide rich and contextualised descriptions of artworks. Visual grounding offers the potential for localising subjects within these descriptions on images, however, existing approaches are trained on natural images and generalise poorly to art. In this paper, we present CIGAr (Context-Infused GroundingDINO for Art), a visual grounding approach which utilises the artwork descriptions during training as context, thereby enabling visual grounding on art. In addition, we present a new dataset, Ukiyo-eVG, with manually annotated phrase-grounding annotations, and we set a new state-of-the-art for object detection on two artwork datasets.
Stylistic Multi-Task Analysis of Ukiyo-e Woodblock Prints
Oct 16, 2024



In this work we present a large-scale dataset of \textit{Ukiyo-e} woodblock prints. Unlike previous works and datasets in the artistic domain that primarily focus on western art, this paper explores this pre-modern Japanese art form with the aim of broadening the scope for stylistic analysis and to provide a benchmark to evaluate a variety of art focused Computer Vision approaches. Our dataset consists of over $175.000$ prints with corresponding metadata (\eg artist, era, and creation date) from the 17th century to present day. By approaching stylistic analysis as a Multi-Task problem we aim to more efficiently utilize the available metadata, and learn more general representations of style. We show results for well-known baselines and state-of-the-art multi-task learning frameworks to enable future comparison, and to encourage stylistic analysis on this artistic domain.