Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Infused Visual Grounding for Art
Paper and Code
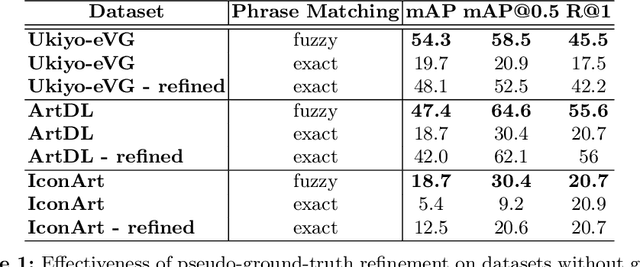

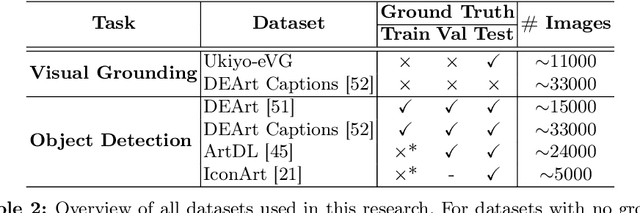
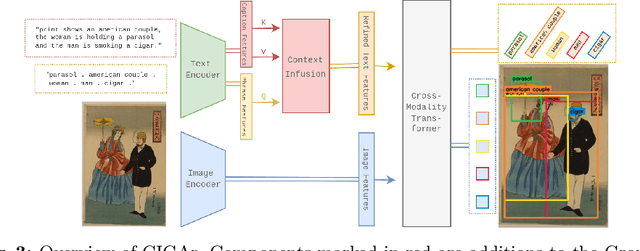
Many artwork collections contain textual attributes that provide rich and contextualised descriptions of artworks. Visual grounding offers the potential for localising subjects within these descriptions on images, however, existing approaches are trained on natural images and generalise poorly to art. In this paper, we present CIGAr (Context-Infused GroundingDINO for Art), a visual grounding approach which utilises the artwork descriptions during training as context, thereby enabling visual grounding on art. In addition, we present a new dataset, Ukiyo-eVG, with manually annotated phrase-grounding annotations, and we set a new state-of-the-art for object detection on two artwork datasets.
View paper on