 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Abundance Maps for Unsupervised Super-Resolution of Hyperspectral Remote Sensing Images
Jan 30, 2026Hyperspectral single image super-resolution (HS-SISR) aims to enhance the spatial resolution of hyperspectral images to fully exploit their spectral information. While considerable progress has been made in this field, most existing methods are supervised and require ground truth data for training-data that is often unavailable in practice. To overcome this limitation, we propose a novel unsupervised training framework for HS-SISR, based on synthetic abundance data. The approach begins by unmixing the hyperspectral image into endmembers and abundances. A neural network is then trained to perform abundance super-resolution using synthetic abundances only. These synthetic abundance maps are generated from a dead leaves model whose characteristics are inherited from the low-resolution image to be super-resolved. This trained network is subsequently used to enhance the spatial resolution of the original image's abundances, and the final super-resolution hyperspectral image is reconstructed by combining them with the endmembers. Experimental results demonstrate both the training value of the synthetic data and the effectiveness of the proposed method.
Super-résolution non supervisée d'images hyperspectrales de télédétection utilisant un entraînement entièrement synthétique
Jan 30, 2026Hyperspectral single image super-resolution (SISR) aims to enhance spatial resolution while preserving the rich spectral information of hyperspectral images. Most existing methods rely on supervised learning with high-resolution ground truth data, which is often unavailable in practice. To overcome this limitation, we propose an unsupervised learning approach based on synthetic abundance data. The hyperspectral image is first decomposed into endmembers and abundance maps through hyperspectral unmixing. A neural network is then trained to super-resolve these maps using data generated with the dead leaves model, which replicates the statistical properties of real abundances. The final super-resolution hyperspectral image is reconstructed by recombining the super-resolved abundance maps with the endmembers. Experimental results demonstrate the effectiveness of our method and the relevance of synthetic data for training.
Unsupervised Super-Resolution of Hyperspectral Remote Sensing Images Using Fully Synthetic Training
Jan 23, 2026Considerable work has been dedicated to hyperspectral single image super-resolution to improve the spatial resolution of hyperspectral images and fully exploit their potential. However, most of these methods are supervised and require some data with ground truth for training, which is often non-available. To overcome this problem, we propose a new unsupervised training strategy for the super-resolution of hyperspectral remote sensing images, based on the use of synthetic abundance data. Its first step decomposes the hyperspectral image into abundances and endmembers by unmixing. Then, an abundance super-resolution neural network is trained using synthetic abundances, which are generated using the dead leaves model in such a way as to faithfully mimic real abundance statistics. Next, the spatial resolution of the considered hyperspectral image abundances is increased using this trained network, and the high resolution hyperspectral image is finally obtained by recombination with the endmembers. Experimental results show the training potential of the synthetic images, and demonstrate the method effectiveness.
VibrantLeaves: A principled parametric image generator for training deep restoration models
Apr 14, 2025



Even though Deep Neural Networks are extremely powerful for image restoration tasks, they have several limitations. They are poorly understood and suffer from strong biases inherited from the training sets. One way to address these shortcomings is to have a better control over the training sets, in particular by using synthetic sets. In this paper, we propose a synthetic image generator relying on a few simple principles. In particular, we focus on geometric modeling, textures, and a simple modeling of image acquisition. These properties, integrated in a classical Dead Leaves model, enable the creation of efficient training sets. Standard image denoising and super-resolution networks can be trained on such datasets, reaching performance almost on par with training on natural image datasets. As a first step towards explainability, we provide a careful analysis of the considered principles, identifying which image properties are necessary to obtain good performances. Besides, such training also yields better robustness to various geometric and radiometric perturbations of the test sets.
A Compact and Semantic Latent Space for Disentangled and Controllable Image Editing
Dec 13, 2023



Recent advances in the field of generative models and in particular generative adversarial networks (GANs) have lead to substantial progress for controlled image editing, especially compared with the pre-deep learning era. Despite their powerful ability to apply realistic modifications to an image, these methods often lack properties like disentanglement (the capacity to edit attributes independently). In this paper, we propose an auto-encoder which re-organizes the latent space of StyleGAN, so that each attribute which we wish to edit corresponds to an axis of the new latent space, and furthermore that the latent axes are decorrelated, encouraging disentanglement. We work in a compressed version of the latent space, using Principal Component Analysis, meaning that the parameter complexity of our autoencoder is reduced, leading to short training times ($\sim$ 45 mins). Qualitative and quantitative results demonstrate the editing capabilities of our approach, with greater disentanglement than competing methods, while maintaining fidelity to the original image with respect to identity. Our autoencoder architecture simple and straightforward, facilitating implementation.
An analysis of the transfer learning of convolutional neural networks for artistic images
Nov 05, 2020


Transfer learning from huge natural image datasets, fine-tuning of deep neural networks and the use of the corresponding pre-trained networks have become de facto the core of art analysis applications. Nevertheless, the effects of transfer learning are still poorly understood. In this paper, we first use techniques for visualizing the network internal representations in order to provide clues to the understanding of what the network has learned on artistic images. Then, we provide a quantitative analysis of the changes introduced by the learning process thanks to metrics in both the feature and parameter spaces, as well as metrics computed on the set of maximal activation images. These analyses are performed on several variations of the transfer learning procedure. In particular, we observed that the network could specialize some pre-trained filters to the new image modality and also that higher layers tend to concentrate classes. Finally, we have shown that a double fine-tuning involving a medium-size artistic dataset can improve the classification on smaller datasets, even when the task changes.
Improving Interpretability for Computer-aided Diagnosis tools on Whole Slide Imaging with Multiple Instance Learning and Gradient-based Explanations
Sep 29, 2020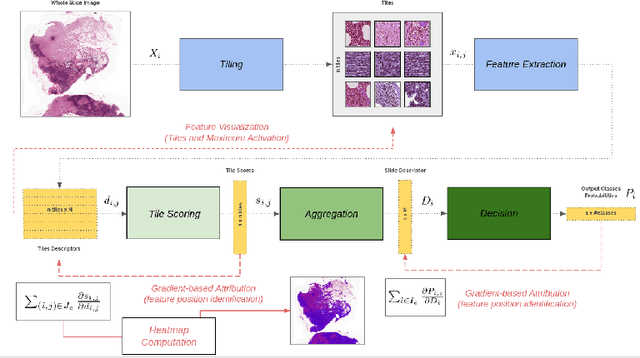

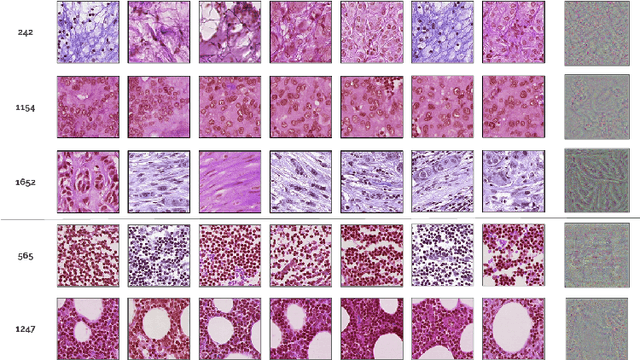
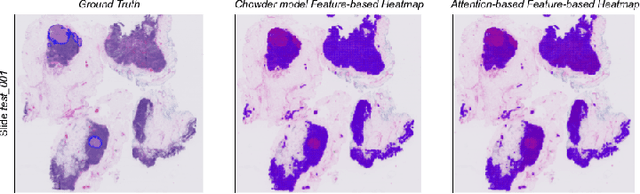
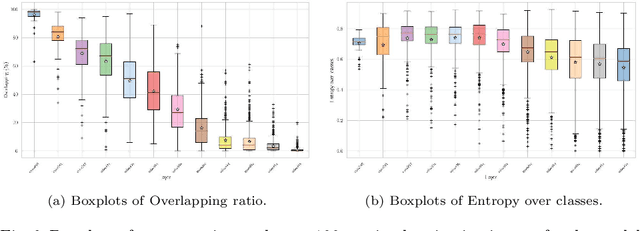
Deep learning methods are widely used for medical applications to assist medical doctors in their daily routines. While performances reach expert's level, interpretability (highlight how and what a trained model learned and why it makes a specific decision) is the next important challenge that deep learning methods need to answer to be fully integrated in the medical field. In this paper, we address the question of interpretability in the context of whole slide images (WSI) classification. We formalize the design of WSI classification architectures and propose a piece-wise interpretability approach, relying on gradient-based methods, feature visualization and multiple instance learning context. We aim at explaining how the decision is made based on tile level scoring, how these tile scores are decided and which features are used and relevant for the task. After training two WSI classification architectures on Camelyon-16 WSI dataset, highlighting discriminative features learned, and validating our approach with pathologists, we propose a novel manner of computing interpretability slide-level heat-maps, based on the extracted features, that improves tile-level classification performances by more than 29% for AUC.
Multiple instance learning on deep features for weakly supervised object detection with extreme domain shifts
Sep 12, 2020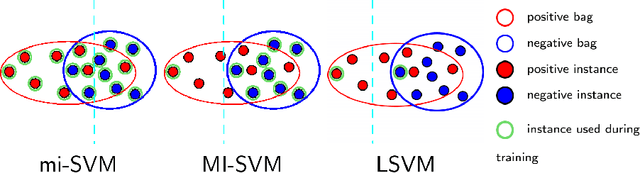
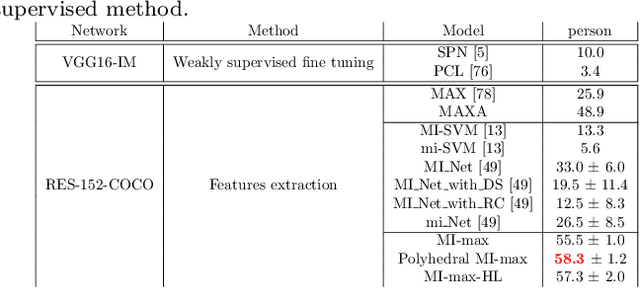
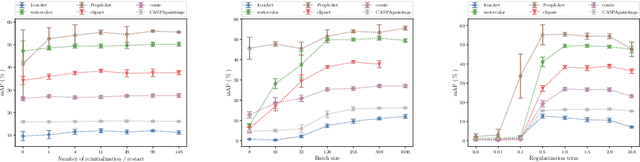
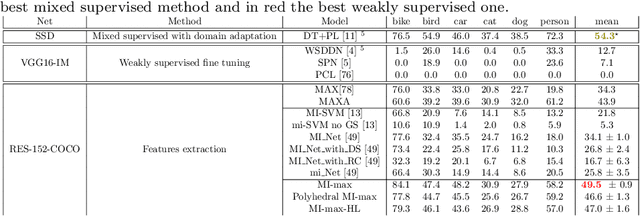
Weakly supervised object detection (WSOD) using only image-level annotations has attracted a growing attention over the past few years. Whereas such task is typically addressed with a domain-specific solution focused on natural images, we show that a simple multiple instance approach applied on pre-trained deep features yields excellent performances on non-photographic datasets, possibly including new classes. The approach does not include any fine-tuning or cross-domain learning and is therefore efficient and possibly applicable to arbitrary datasets and classes. We investigate several flavors of the proposed approach, some including multi-layers perceptron and polyhedral classifiers. Despite its simplicity, our method shows competitive results on a range of publicly available datasets, including paintings (People-Art, IconArt), watercolors, cliparts and comics and allows to quickly learn unseen visual categories.
High resolution neural texture synthesis with long range constraints
Aug 04, 2020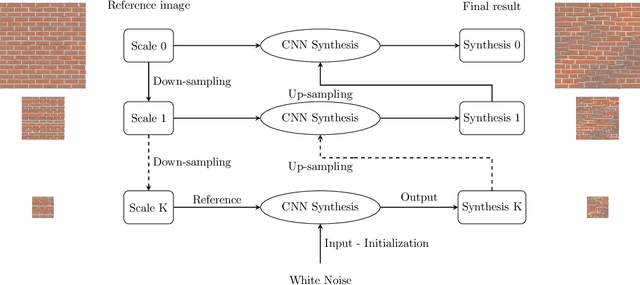


The field of texture synthesis has witnessed important progresses over the last years, most notably through the use of Convolutional Neural Networks. However, neural synthesis methods still struggle to reproduce large scale structures, especially with high resolution textures. To address this issue, we first introduce a simple multi-resolution framework that efficiently accounts for long-range dependency. Then, we show that additional statistical constraints further improve the reproduction of textures with strong regularity. This can be achieved by constraining both the Gram matrices of a neural network and the power spectrum of the image. Alternatively one may constrain only the autocorrelation of the features of the network and drop the Gram matrices constraints. In an experimental part, the proposed methods are then extensively tested and compared to alternative approaches, both in an unsupervised way and through a user study. Experiments show the interest of the multi-scale scheme for high resolution textures and the interest of combining it with additional constraints for regular textures.
PCAAE: Principal Component Analysis Autoencoder for organising the latent space of generative networks
Jun 14, 2020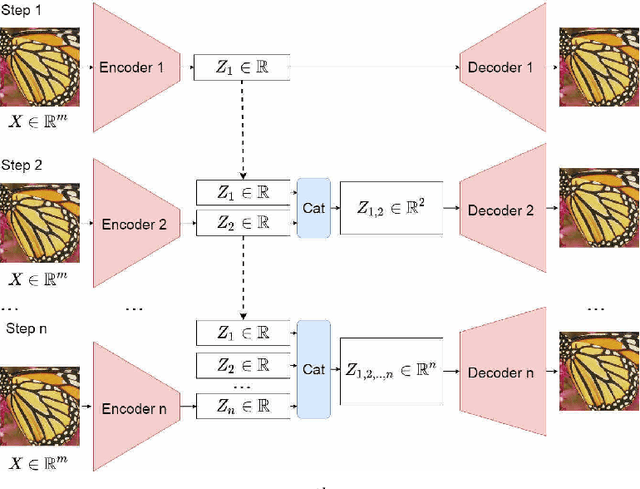

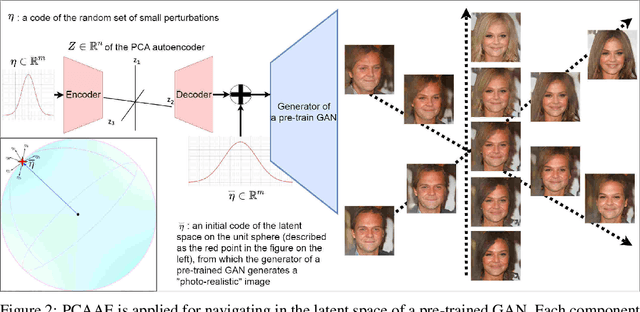
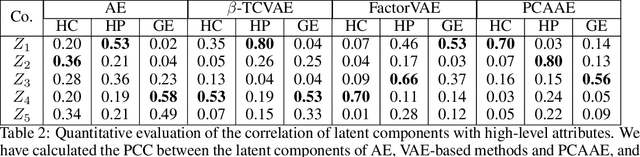
Autoencoders and generative models produce some of the most spectacular deep learning results to date. However, understanding and controlling the latent space of these models presents a considerable challenge. Drawing inspiration from principal component analysis and autoencoder, we propose the Principal Component Analysis Autoencoder (PCAAE). This is a novel autoencoder whose latent space verifies two properties. Firstly, the dimensions are organised in decreasing importance with respect to the data at hand. Secondly, the components of the latent space are statistically independent. We achieve this by progressively increasing the latent space during training, and with a covariance loss applied to the latent codes. The resulting autoencoder produces a latent space which separates the intrinsic attributes of the data into different components of the latent space, in a completely unsupervised manner. We also describe an extension of our approach to the case of powerful, pre-trained GANs. We show results on both synthetic examples of shapes and on a state-of-the-art GAN. For example, we are able to separate the color shade scale of hair and skin, pose of faces and the gender in the CelebA, without accessing any labels. We compare the PCAAE with other state-of-the-art approaches, in particular with respect to the ability to disentangle attributes in the latent space. We hope that this approach will contribute to better understanding of the intrinsic latent spaces of powerful deep generative models.