 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA PCA-like Autoencoder
Paper and Code
Apr 02, 2019
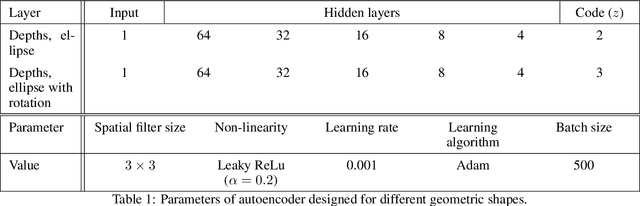


An autoencoder is a neural network which data projects to and from a lower dimensional latent space, where this data is easier to understand and model. The autoencoder consists of two sub-networks, the encoder and the decoder, which carry out these transformations. The neural network is trained such that the output is as close to the input as possible, the data having gone through an information bottleneck : the latent space. This tool bears significant ressemblance to Principal Component Analysis (PCA), with two main differences. Firstly, the autoencoder is a non-linear transformation, contrary to PCA, which makes the autoencoder more flexible and powerful. Secondly, the axes found by a PCA are orthogonal, and are ordered in terms of the amount of variability which the data presents along these axes. This makes the interpretability of the PCA much greater than that of the autoencoder, which does not have these attributes. Ideally, then, we would like an autoencoder whose latent space consists of independent components, ordered by decreasing importance to the data. In this paper, we propose an algorithm to create such a network. We create an iterative algorithm which progressively increases the size of the latent space, learning a new dimension at each step. Secondly, we propose a covariance loss term to add to the standard autoencoder loss function, as well as a normalisation layer just before the latent space, which encourages the latent space components to be statistically independent. We demonstrate the results of this autoencoder on simple geometric shapes, and find that the algorithm indeed finds a meaningful representation in the latent space. This means that subsequent interpolation in the latent space has meaning with respect to the geometric properties of the images.