 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Order Logic with Fuzzy Semantics for Describing and Recognizing Nerves in Medical Images
Apr 30, 2025This article deals with the description and recognition of fiber bundles, in particular nerves, in medical images, based on the anatomical description of the fiber trajectories. To this end, we propose a logical formalization of this anatomical knowledge. The intrinsically imprecise description of nerves, as found in anatomical textbooks, leads us to propose fuzzy semantics combined with first-order logic. We define a language representing spatial entities, relations between these entities and quantifiers. A formula in this language is then a formalization of the natural language description. The semantics are given by fuzzy representations in a concrete domain and satisfaction degrees of relations. Based on this formalization, a spatial reasoning algorithm is proposed for segmentation and recognition of nerves from anatomical and diffusion magnetic resonance images, which is illustrated on pelvic nerves in pediatric imaging, enabling surgeons to plan surgery.
An action language-based formalisation of an abstract argumentation framework
Sep 29, 2024
An abstract argumentation framework is a commonly used formalism to provide a static representation of a dialogue. However, the order of enunciation of the arguments in an argumentative dialogue is very important and can affect the outcome of this dialogue. In this paper, we propose a new framework for modelling abstract argumentation graphs, a model that incorporates the order of enunciation of arguments. By taking this order into account, we have the means to deduce a unique outcome for each dialogue, called an extension. We also establish several properties, such as termination and correctness, and discuss two notions of completeness. In particular, we propose a modification of the previous transformation based on a "last enunciated last updated" strategy, which verifies the second form of completeness.
Exploiting temporal information to detect conversational groups in videos and predict the next speaker
Aug 29, 2024



Studies in human human interaction have introduced the concept of F formation to describe the spatial arrangement of participants during social interactions. This paper has two objectives. It aims at detecting F formations in video sequences and predicting the next speaker in a group conversation. The proposed approach exploits time information and human multimodal signals in video sequences. In particular, we rely on measuring the engagement level of people as a feature of group belonging. Our approach makes use of a recursive neural network, the Long Short Term Memory (LSTM), to predict who will take the speaker's turn in a conversation group. Experiments on the MatchNMingle dataset led to 85% true positives in group detection and 98% accuracy in predicting the next speaker.
* Accepted to Pattern Recognition Letter, 8 pages, 10 figures
Non-Redundant Combination of Hand-Crafted and Deep Learning Radiomics: Application to the Early Detection of Pancreatic Cancer
Aug 22, 2023



We address the problem of learning Deep Learning Radiomics (DLR) that are not redundant with Hand-Crafted Radiomics (HCR). To do so, we extract DLR features using a VAE while enforcing their independence with HCR features by minimizing their mutual information. The resulting DLR features can be combined with hand-crafted ones and leveraged by a classifier to predict early markers of cancer. We illustrate our method on four early markers of pancreatic cancer and validate it on a large independent test set. Our results highlight the value of combining non-redundant DLR and HCR features, as evidenced by an improvement in the Area Under the Curve compared to baseline methods that do not address redundancy or solely rely on HCR features.
Decoupled conditional contrastive learning with variable metadata for prostate lesion detection
Aug 18, 2023



Early diagnosis of prostate cancer is crucial for efficient treatment. Multi-parametric Magnetic Resonance Images (mp-MRI) are widely used for lesion detection. The Prostate Imaging Reporting and Data System (PI-RADS) has standardized interpretation of prostate MRI by defining a score for lesion malignancy. PI-RADS data is readily available from radiology reports but is subject to high inter-reports variability. We propose a new contrastive loss function that leverages weak metadata with multiple annotators per sample and takes advantage of inter-reports variability by defining metadata confidence. By combining metadata of varying confidence with unannotated data into a single conditional contrastive loss function, we report a 3% AUC increase on lesion detection on the public PI-CAI challenge dataset. Code is available at: https://github.com/camilleruppli/decoupled_ccl
Weakly-supervised positional contrastive learning: application to cirrhosis classification
Jul 12, 2023Large medical imaging datasets can be cheaply and quickly annotated with low-confidence, weak labels (e.g., radiological scores). Access to high-confidence labels, such as histology-based diagnoses, is rare and costly. Pretraining strategies, like contrastive learning (CL) methods, can leverage unlabeled or weakly-annotated datasets. These methods typically require large batch sizes, which poses a difficulty in the case of large 3D images at full resolution, due to limited GPU memory. Nevertheless, volumetric positional information about the spatial context of each 2D slice can be very important for some medical applications. In this work, we propose an efficient weakly-supervised positional (WSP) contrastive learning strategy where we integrate both the spatial context of each 2D slice and a weak label via a generic kernel-based loss function. We illustrate our method on cirrhosis prediction using a large volume of weakly-labeled images, namely radiological low-confidence annotations, and small strongly-labeled (i.e., high-confidence) datasets. The proposed model improves the classification AUC by 5% with respect to a baseline model on our internal dataset, and by 26% on the public LIHC dataset from the Cancer Genome Atlas. The code is available at: https://github.com/Guerbet-AI/wsp-contrastive.
Meta-Learners for Few-Shot Weakly-Supervised Medical Image Segmentation
May 11, 2023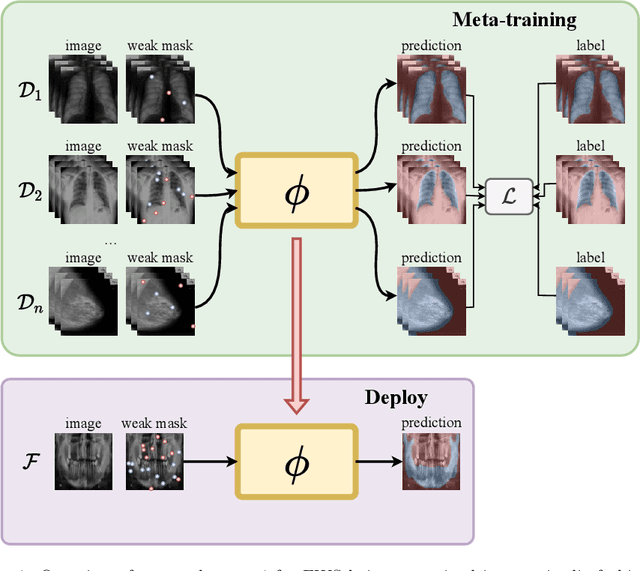



Most uses of Meta-Learning in visual recognition are very often applied to image classification, with a relative lack of works in other tasks {such} as segmentation and detection. We propose a generic Meta-Learning framework for few-shot weakly-supervised segmentation in medical imaging domains. We conduct a comparative analysis of meta-learners from distinct paradigms adapted to few-shot image segmentation in different sparsely annotated radiological tasks. The imaging modalities include 2D chest, mammographic and dental X-rays, as well as 2D slices of volumetric tomography and resonance images. Our experiments consider a total of 9 meta-learners, 4 backbones and multiple target organ segmentation tasks. We explore small-data scenarios in radiology with varying weak annotation styles and densities. Our analysis shows that metric-based meta-learning approaches achieve better segmentation results in tasks with smaller domain shifts in comparison to the meta-training datasets, while some gradient- and fusion-based meta-learners are more generalizable to larger domain shifts.
Morpho-logic from a Topos Perspective: Application to symbolic AI
Mar 08, 2023Modal logics have proved useful for many reasoning tasks in symbolic artificial intelligence (AI), such as belief revision, spatial reasoning, among others. On the other hand, mathematical morphology (MM) is a theory for non-linear analysis of structures, that was widely developed and applied in image analysis. Its mathematical bases rely on algebra, complete lattices, topology. Strong links have been established between MM and mathematical logics, mostly modal logics. In this paper, we propose to further develop and generalize this link between mathematical morphology and modal logic from a topos perspective, i.e. categorial structures generalizing space, and connecting logics, sets and topology. Furthermore, we rely on the internal language and logic of topos. We define structuring elements, dilations and erosions as morphisms. Then we introduce the notion of structuring neighborhoods, and show that the dilations and erosions based on them lead to a constructive modal logic, for which a sound and complete proof system is proposed. We then show that the modal logic thus defined (called morpho-logic here), is well adapted to define concrete and efficient operators for revision, merging, and abduction of new knowledge, or even spatial reasoning.
Learning to diagnose cirrhosis from radiological and histological labels with joint self and weakly-supervised pretraining strategies
Feb 16, 2023Identifying cirrhosis is key to correctly assess the health of the liver. However, the gold standard diagnosis of the cirrhosis needs a medical intervention to obtain the histological confirmation, e.g. the METAVIR score, as the radiological presentation can be equivocal. In this work, we propose to leverage transfer learning from large datasets annotated by radiologists, which we consider as a weak annotation, to predict the histological score available on a small annex dataset. To this end, we propose to compare different pretraining methods, namely weakly-supervised and self-supervised ones, to improve the prediction of the cirrhosis. Finally, we introduce a loss function combining both supervised and self-supervised frameworks for pretraining. This method outperforms the baseline classification of the METAVIR score, reaching an AUC of 0.84 and a balanced accuracy of 0.75, compared to 0.77 and 0.72 for a baseline classifier.
Model-based inexact graph matching on top of CNNs for semantic scene understanding
Jan 18, 2023



Deep learning based pipelines for semantic segmentation often ignore structural information available on annotated images used for training. We propose a novel post-processing module enforcing structural knowledge about the objects of interest to improve segmentation results provided by deep learning. This module corresponds to a "many-to-one-or-none" inexact graph matching approach, and is formulated as a quadratic assignment problem. Our approach is compared to a CNN-based segmentation (for various CNN backbones) on two public datasets, one for face segmentation from 2D RGB images (FASSEG), and the other for brain segmentation from 3D MRIs (IBSR). Evaluations are performed using two types of structural information (distances and directional relations, , this choice being a hyper-parameter of our generic framework). On FASSEG data, results show that our module improves accuracy of the CNN by about 6.3% (the Hausdorff distance decreases from 22.11 to 20.71). On IBSR data, the improvement is of 51% (the Hausdorff distance decreases from 11.01 to 5.4). In addition, our approach is shown to be resilient to small training datasets that often limit the performance of deep learning methods: the improvement increases as the size of the training dataset decreases.