 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learners for Few-Shot Weakly-Supervised Medical Image Segmentation
May 11, 2023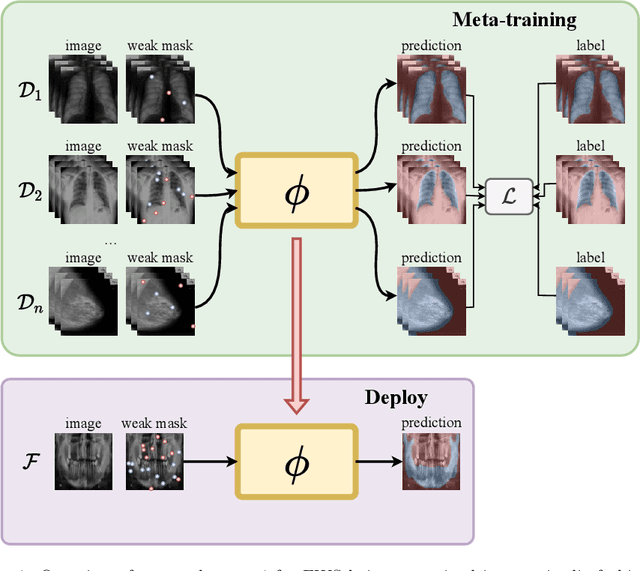



Most uses of Meta-Learning in visual recognition are very often applied to image classification, with a relative lack of works in other tasks {such} as segmentation and detection. We propose a generic Meta-Learning framework for few-shot weakly-supervised segmentation in medical imaging domains. We conduct a comparative analysis of meta-learners from distinct paradigms adapted to few-shot image segmentation in different sparsely annotated radiological tasks. The imaging modalities include 2D chest, mammographic and dental X-rays, as well as 2D slices of volumetric tomography and resonance images. Our experiments consider a total of 9 meta-learners, 4 backbones and multiple target organ segmentation tasks. We explore small-data scenarios in radiology with varying weak annotation styles and densities. Our analysis shows that metric-based meta-learning approaches achieve better segmentation results in tasks with smaller domain shifts in comparison to the meta-training datasets, while some gradient- and fusion-based meta-learners are more generalizable to larger domain shifts.
FuSS: Fusing Superpixels for Improved Segmentation Consistency
Jun 06, 2022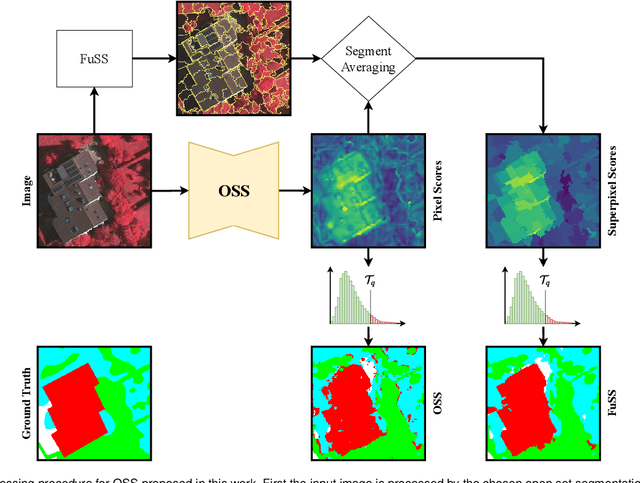


In this work, we propose two different approaches to improve the semantic consistency of Open Set Semantic Segmentation. First, we propose a method called OpenGMM that extends the OpenPCS framework using a Gaussian Mixture of Models to model the distribution of pixels for each class in a multimodal manner. The second approach is a post-processing which uses superpixels to enforce highly homogeneous regions to behave equally, rectifying erroneous classified pixels within these regions, we also proposed a novel superpixel method called FuSS. All tests were performed on ISPRS Vaihingen and Potsdam datasets, and both methods were capable to improve quantitative and qualitative results for both datasets. Besides that, the post-process with FuSS achieved state-of-the-art results for both datasets. The official implementation is available at: \url{https://github.com/iannunes/FuSS}.
Conditional Reconstruction for Open-set Semantic Segmentation
Mar 02, 2022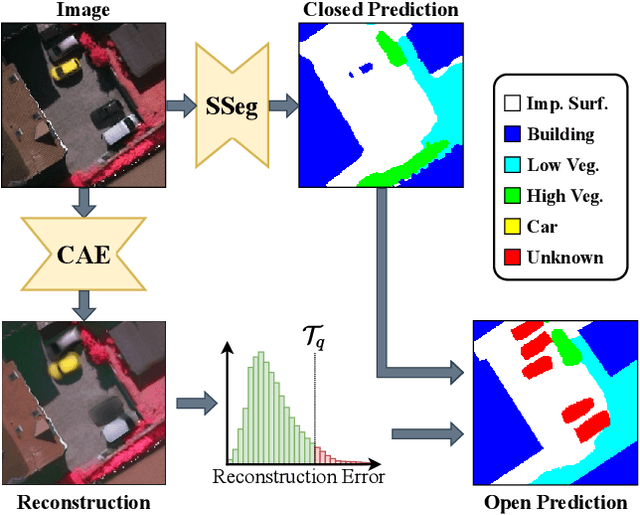
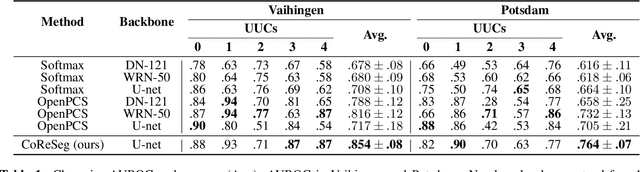
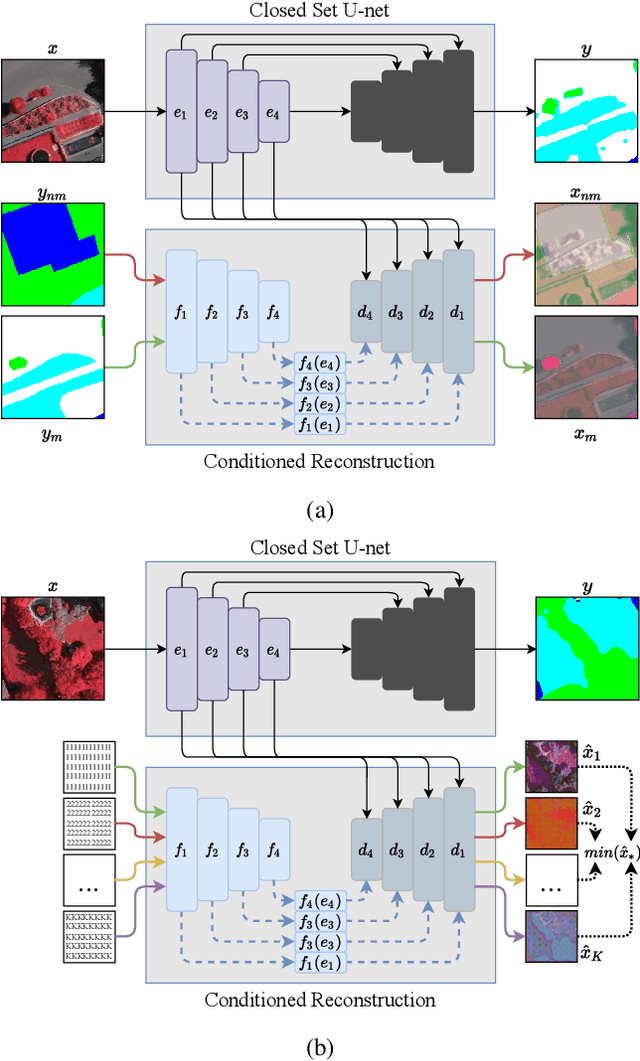
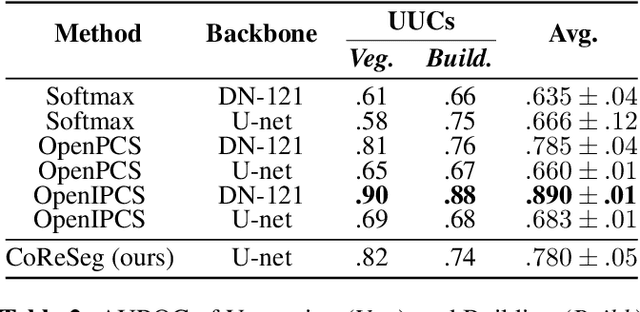
Open set segmentation is a relatively new and unexploredtask, with just a handful of methods proposed to model suchtasks.We propose a novel method called CoReSeg thattackles the issue using class conditional reconstruction ofthe input images according to their pixelwise mask. Ourmethod conditions each input pixel to all known classes,expecting higher errors for pixels of unknown classes. Itwas observed that the proposed method produces better se-mantic consistency in its predictions, resulting in cleanersegmentation maps that better fit object boundaries. CoRe-Seg outperforms state-of-the-art methods on the Vaihin-gen and Potsdam ISPRS datasets, while also being com-petitive on the Houston 2018 IEEE GRSS Data Fusiondataset. Official implementation for CoReSeg is availableat:https://github.com/iannunes/CoReSeg.
Weakly Supervised Few-Shot Segmentation Via Meta-Learning
Sep 03, 2021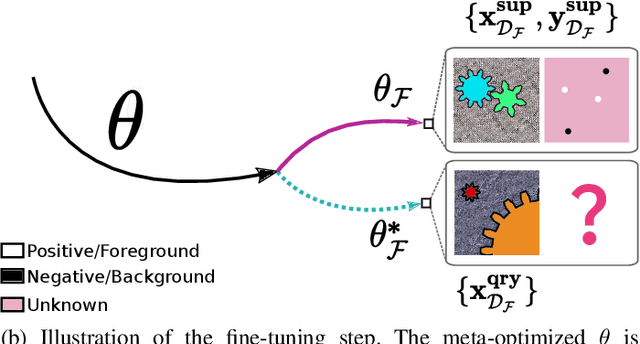
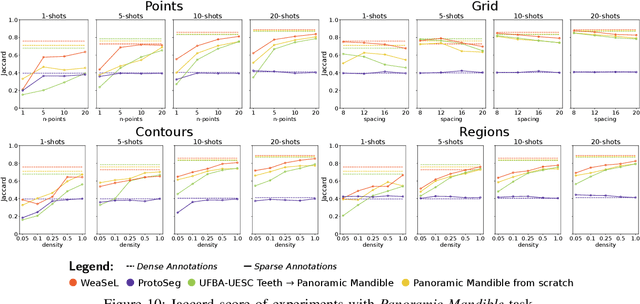
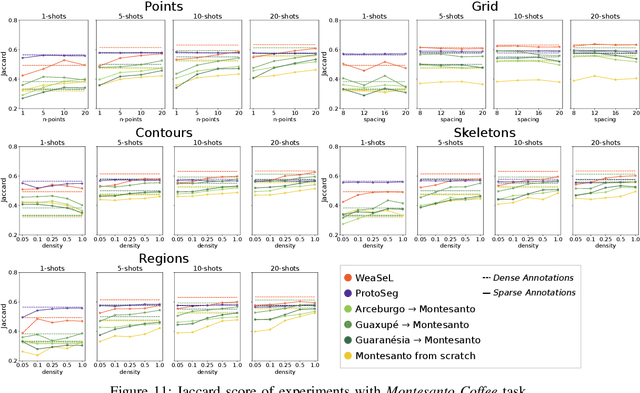
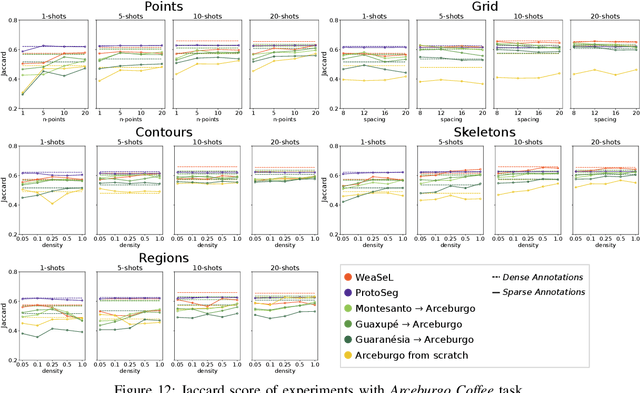
Semantic segmentation is a classic computer vision task with multiple applications, which includes medical and remote sensing image analysis. Despite recent advances with deep-based approaches, labeling samples (pixels) for training models is laborious and, in some cases, unfeasible. In this paper, we present two novel meta learning methods, named WeaSeL and ProtoSeg, for the few-shot semantic segmentation task with sparse annotations. We conducted extensive evaluation of the proposed methods in different applications (12 datasets) in medical imaging and agricultural remote sensing, which are very distinct fields of knowledge and usually subject to data scarcity. The results demonstrated the potential of our method, achieving suitable results for segmenting both coffee/orange crops and anatomical parts of the human body in comparison with full dense annotation.
Learning to Segment Medical Images from Few-Shot Sparse Labels
Aug 22, 2021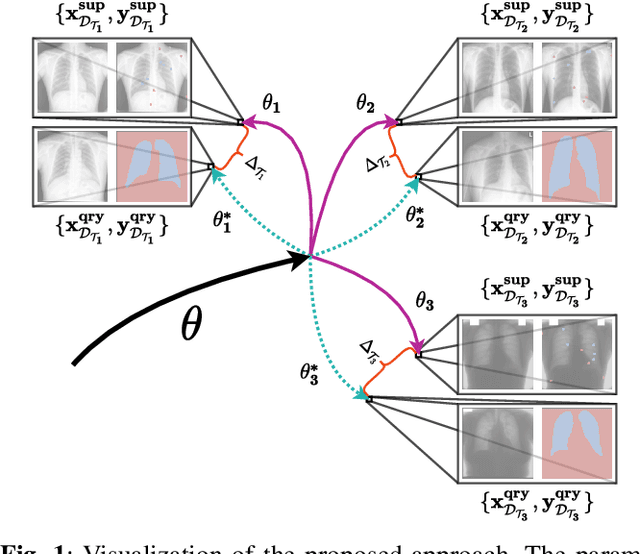
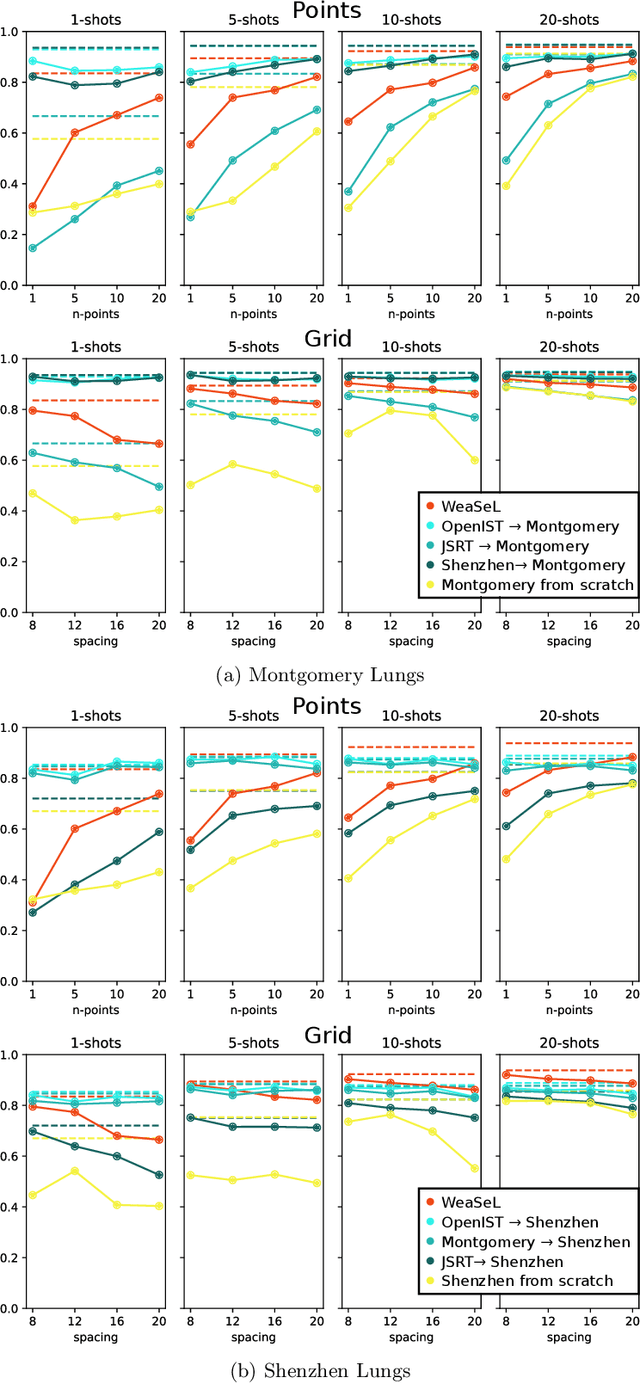

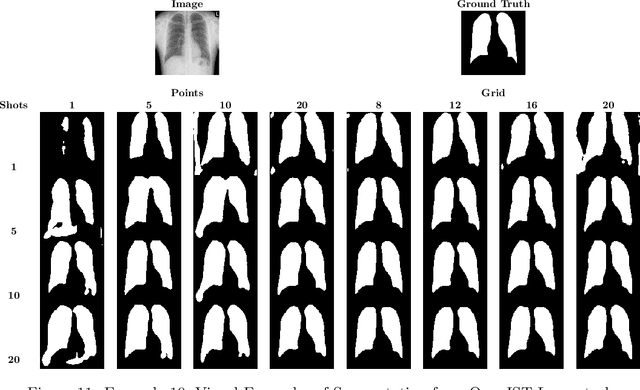
In this paper, we propose a novel approach for few-shot semantic segmentation with sparse labeled images. We investigate the effectiveness of our method, which is based on the Model-Agnostic Meta-Learning (MAML) algorithm, in the medical scenario, where the use of sparse labeling and few-shot can alleviate the cost of producing new annotated datasets. Our method uses sparse labels in the meta-training and dense labels in the meta-test, thus making the model learn to predict dense labels from sparse ones. We conducted experiments with four Chest X-Ray datasets to evaluate two types of annotations (grid and points). The results show that our method is the most suitable when the target domain highly differs from source domains, achieving Jaccard scores comparable to dense labels, using less than 2% of the pixels of an image with labels in few-shot scenarios.
Opening Deep Neural Networks with Generative Models
May 20, 2021


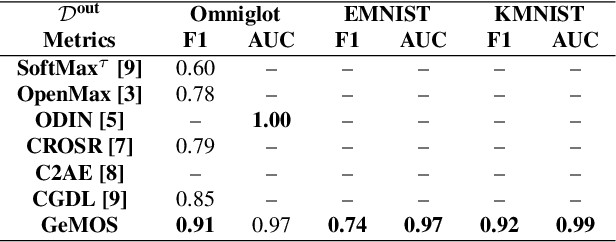
Image classification methods are usually trained to perform predictions taking into account a predefined group of known classes. Real-world problems, however, may not allow for a full knowledge of the input and label spaces, making failures in recognition a hazard to deep visual learning. Open set recognition methods are characterized by the ability to correctly identifying inputs of known and unknown classes. In this context, we propose GeMOS: simple and plug-and-play open set recognition modules that can be attached to pretrained Deep Neural Networks for visual recognition. The GeMOS framework pairs pre-trained Convolutional Neural Networks with generative models for open set recognition to extract open set scores for each sample, allowing for failure recognition in object recognition tasks. We conduct a thorough evaluation of the proposed method in comparison with state-of-the-art open set algorithms, finding that GeMOS either outperforms or is statistically indistinguishable from more complex and costly models.
AiRound and CV-BrCT: Novel Multi-View Datasets for Scene Classification
Aug 03, 2020



It is undeniable that aerial/satellite images can provide useful information for a large variety of tasks. But, since these images are always looking from above, some applications can benefit from complementary information provided by other perspective views of the scene, such as ground-level images. Despite a large number of public repositories for both georeferenced photographs and aerial images, there is a lack of benchmark datasets that allow the development of approaches that exploit the benefits and complementarity of aerial/ground imagery. In this paper, we present two new publicly available datasets named \thedataset~and CV-BrCT. The first one contains triplets of images from the same geographic coordinate with different perspectives of view extracted from various places around the world. Each triplet is composed of an aerial RGB image, a ground-level perspective image, and a Sentinel-2 sample. The second dataset contains pairs of aerial and street-level images extracted from southeast Brazil. We design an extensive set of experiments concerning multi-view scene classification, using early and late fusion. Such experiments were conducted to show that image classification can be enhanced using multi-view data.
Fully Convolutional Open Set Segmentation
Jun 25, 2020
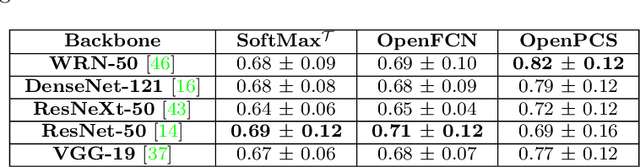


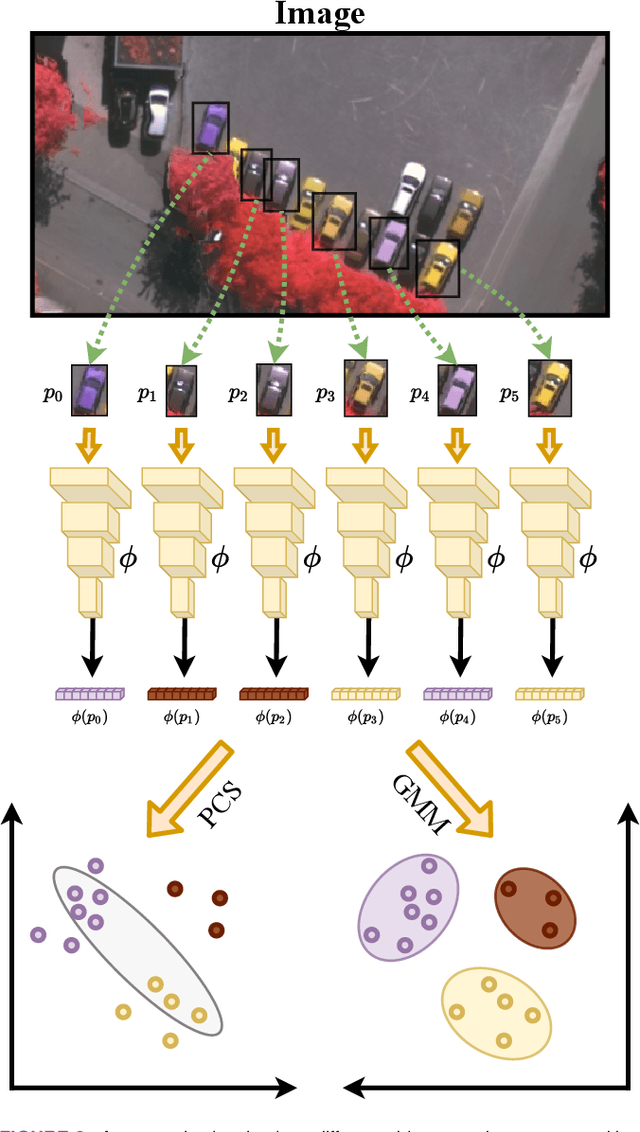
In semantic segmentation knowing about all existing classes is essential to yield effective results with the majority of existing approaches. However, these methods trained in a Closed Set of classes fail when new classes are found in the test phase. It means that they are not suitable for Open Set scenarios, which are very common in real-world computer vision and remote sensing applications. In this paper, we discuss the limitations of Closed Set segmentation and propose two fully convolutional approaches to effectively address Open Set semantic segmentation: OpenFCN and OpenPCS. OpenFCN is based on the well-known OpenMax algorithm, configuring a new application of this approach in segmentation settings. OpenPCS is a fully novel approach based on feature-space from DNN activations that serve as features for computing PCA and multi-variate gaussian likelihood in a lower dimensional space. Experiments were conducted on the well-known Vaihingen and Potsdam segmentation datasets. OpenFCN showed little-to-no improvement when compared to the simpler and much more time efficient SoftMax thresholding, while being between some orders of magnitude slower. OpenPCS achieved promising results in almost all experiments by overcoming both OpenFCN and SoftMax thresholding. OpenPCS is also a reasonable compromise between the runtime performances of the extremely fast SoftMax thresholding and the extremely slow OpenFCN, being close able to run close to real-time. Experiments also indicate that OpenPCS is effective, robust and suitable for Open Set segmentation, being able to improve the recognition of unknown class pixels without reducing the accuracy on the known class pixels.
Conditional Domain Adaptation GANs for Biomedical Image Segmentation
Jan 16, 2019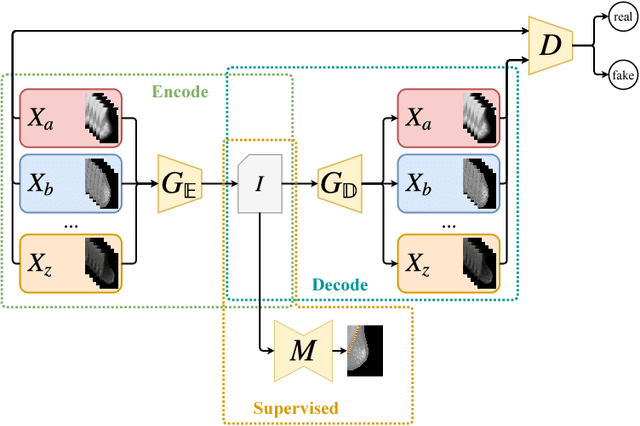


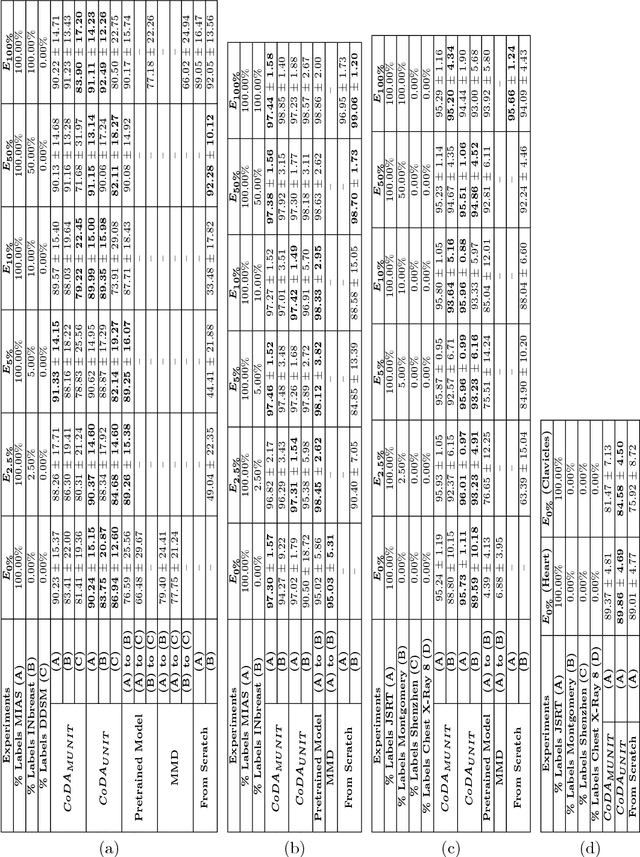
Due to visual differences in biomedical image datasets acquired using distinct digitization techniques, Transfer Learning is an important step for improving the generalization capabilities of Neural Networks in this area. Despite succeeding in classification tasks, most Domain Adaptation strategies face serious limitations in segmentation. Therefore, improving on previous Image Translation networks, we propose a Domain Adaptation method for biomedical image segmentation based on adversarial networks that can learn from both unlabeled and labeled data. Our experimental procedure compares our method using several domains, datasets, segmentation tasks and baselines, performing quantitative and qualitative comparisons of the proposed method with baselines. The proposed method shows consistently better results than the baselines in scarce label scenarios, often achieving Jaccard values greater than 0.9 and adequate segmentation quality in most tasks and datasets.