 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAiRound and CV-BrCT: Novel Multi-View Datasets for Scene Classification
Aug 03, 2020



It is undeniable that aerial/satellite images can provide useful information for a large variety of tasks. But, since these images are always looking from above, some applications can benefit from complementary information provided by other perspective views of the scene, such as ground-level images. Despite a large number of public repositories for both georeferenced photographs and aerial images, there is a lack of benchmark datasets that allow the development of approaches that exploit the benefits and complementarity of aerial/ground imagery. In this paper, we present two new publicly available datasets named \thedataset~and CV-BrCT. The first one contains triplets of images from the same geographic coordinate with different perspectives of view extracted from various places around the world. Each triplet is composed of an aerial RGB image, a ground-level perspective image, and a Sentinel-2 sample. The second dataset contains pairs of aerial and street-level images extracted from southeast Brazil. We design an extensive set of experiments concerning multi-view scene classification, using early and late fusion. Such experiments were conducted to show that image classification can be enhanced using multi-view data.
BrazilDAM: A Benchmark dataset for Tailings Dam Detection
Mar 17, 2020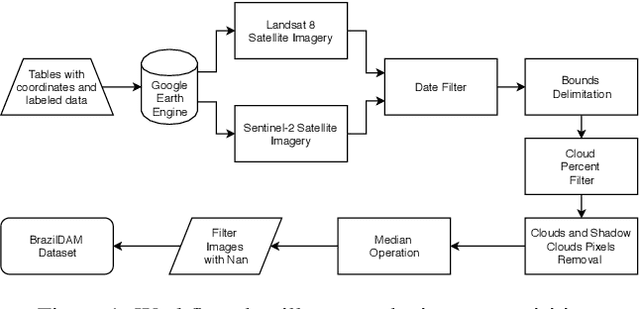
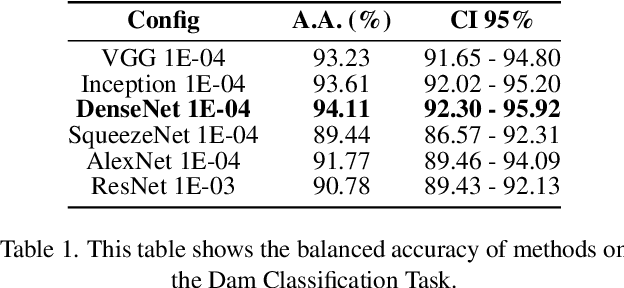
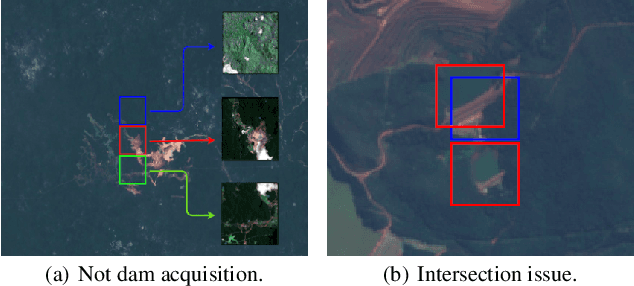
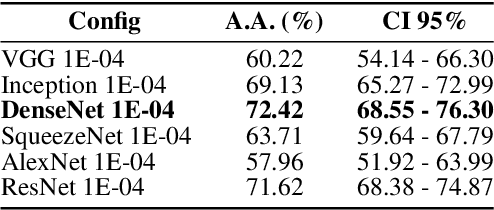
In this work we present BrazilDAM, a novel public dataset based on Sentinel-2 and Landsat-8 satellite images covering all tailings dams cataloged by the Brazilian National Mining Agency (ANM). The dataset was built using georeferenced images from 769 dams, recorded between 2016 and 2019. The time series were processed in order to produce cloud free images. The dams contain mining waste from different ore categories and have highly varying shapes, areas and volumes, making BrazilDAM particularly interesting and challenging to be used in machine learning benchmarks. The original catalog contains, besides the dam coordinates, information about: the main ore, constructive method, risk category, and associated potential damage. To evaluate BrazilDAM's predictive potential we performed classification essays using state-of-the-art deep Convolutional Neural Network (CNNs). In the experiments, we achieved an average classification accuracy of 94.11\% in tailing dam binary classification task. In addition, others four setups of experiments were made using the complementary information from the original catalog, exhaustively exploiting the capacity of the proposed dataset.
Conditional Domain Adaptation GANs for Biomedical Image Segmentation
Jan 16, 2019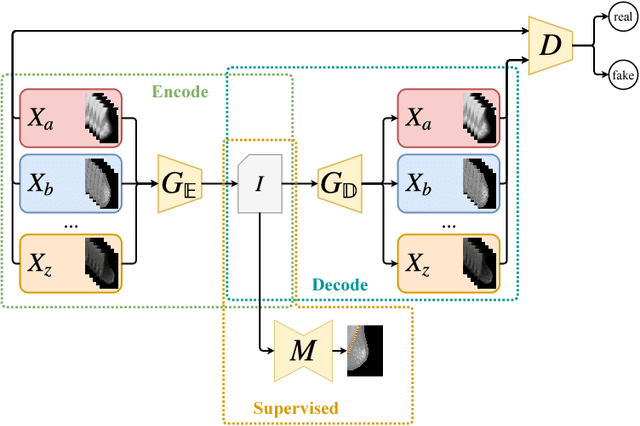


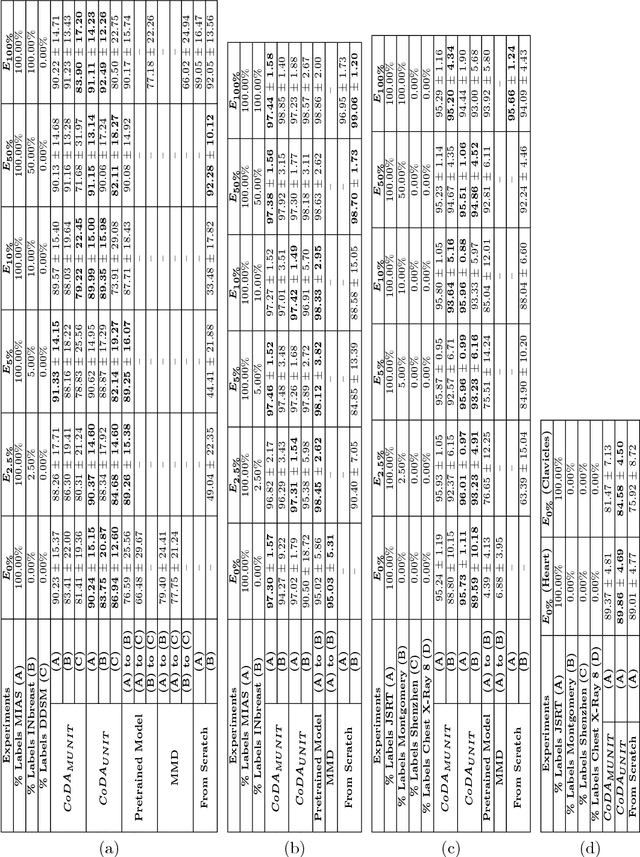
Due to visual differences in biomedical image datasets acquired using distinct digitization techniques, Transfer Learning is an important step for improving the generalization capabilities of Neural Networks in this area. Despite succeeding in classification tasks, most Domain Adaptation strategies face serious limitations in segmentation. Therefore, improving on previous Image Translation networks, we propose a Domain Adaptation method for biomedical image segmentation based on adversarial networks that can learn from both unlabeled and labeled data. Our experimental procedure compares our method using several domains, datasets, segmentation tasks and baselines, performing quantitative and qualitative comparisons of the proposed method with baselines. The proposed method shows consistently better results than the baselines in scarce label scenarios, often achieving Jaccard values greater than 0.9 and adequate segmentation quality in most tasks and datasets.
A Comparative Study on Unsupervised Domain Adaptation Approaches for Coffee Crop Mapping
Jun 06, 2018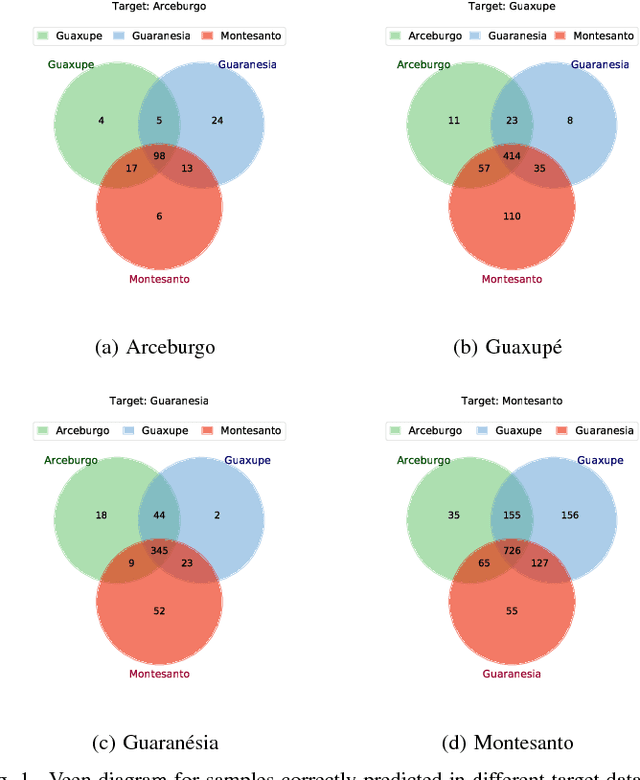
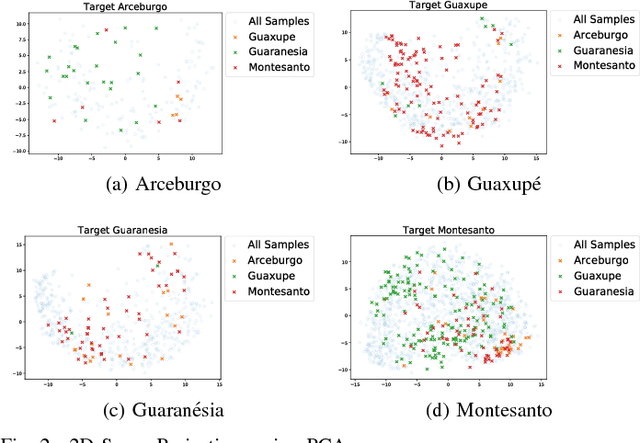
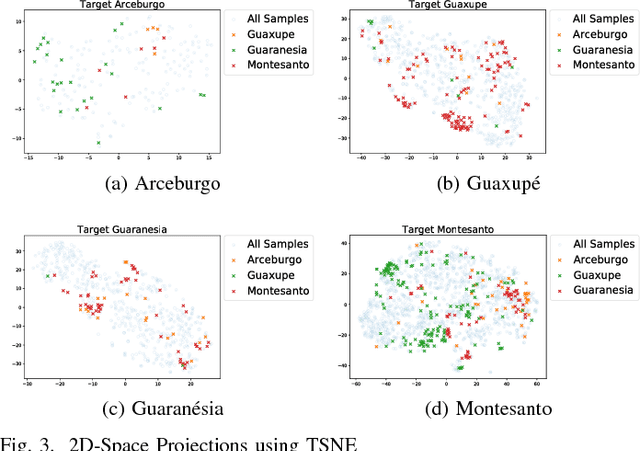
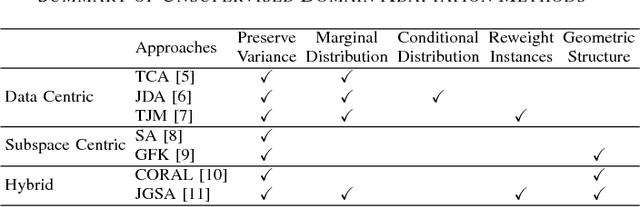
In this work, we investigate the application of existing unsupervised domain adaptation (UDA) approaches to the task of transferring knowledge between crop regions having different coffee patterns. Given a geographical region with fully mapped coffee plantations, we observe that this knowledge can be used to train a classifier and to map a new county with no need of samples indicated in the target region. Experimental results show that transferring knowledge via some UDA strategies performs better than just applying a classifier trained in a region to predict coffee crops in a new one. However, UDA methods may lead to negative transfer, which may indicate that domains are too different that transferring knowledge is not appropriate. We also verify that normalization affect significantly some UDA methods; we observe a meaningful complementary contribution between coffee crops data; and a visual behavior suggests an existent of a cluster of samples that are more likely to be drawn from a specific data.