 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment Reduces Expressed but Not Encoded Gender Bias: A Unified Framework and Study
Mar 25, 2026During training, Large Language Models (LLMs) learn social regularities that can lead to gender bias in downstream applications. Most mitigation efforts focus on reducing bias in generated outputs, typically evaluated on structured benchmarks, which raises two concerns: output-level evaluation does not reveal whether alignment modifies the model's underlying representations, and structured benchmarks may not reflect realistic usage scenarios. We propose a unified framework to jointly analyze intrinsic and extrinsic gender bias in LLMs using identical neutral prompts, enabling direct comparison between gender-related information encoded in internal representations and bias expressed in generated outputs. Contrary to prior work reporting weak or inconsistent correlations, we find a consistent association between latent gender information and expressed bias when measured under the unified protocol. We further examine the effect of alignment through supervised fine-tuning aimed at reducing gender bias. Our results suggest that while the latter indeed reduces expressed bias, measurable gender-related associations are still present in internal representations, and can be reactivated under adversarial prompting. Finally, we consider two realistic settings and show that debiasing effects observed on structured benchmarks do not necessarily generalize, e.g., to the case of story generation.
Did I Faithfully Say What I Thought? Bridging the Gap Between Neural Activity and Self-Explanations in Large Language Models
Jun 12, 2025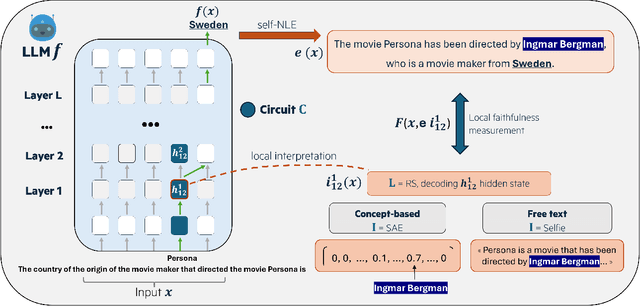
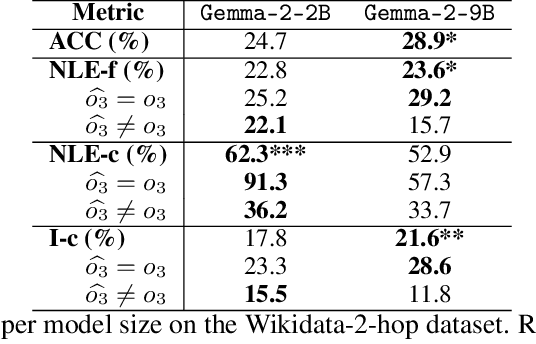
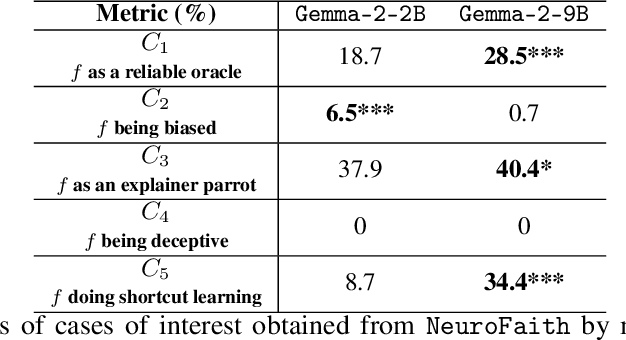

Large Language Models (LLM) have demonstrated the capability of generating free text self Natural Language Explanation (self-NLE) to justify their answers. Despite their logical appearance, self-NLE do not necessarily reflect the LLM actual decision-making process, making such explanations unfaithful. While existing methods for measuring self-NLE faithfulness mostly rely on behavioral tests or computational block identification, none of them examines the neural activity underlying the model's reasoning. This work introduces a novel flexible framework for quantitatively measuring the faithfulness of LLM-generated self-NLE by directly comparing the latter with interpretations of the model's internal hidden states. The proposed framework is versatile and provides deep insights into self-NLE faithfulness by establishing a direct connection between self-NLE and model reasoning. This approach advances the understanding of self-NLE faithfulness and provides building blocks for generating more faithful self-NLE.
An action language-based formalisation of an abstract argumentation framework
Sep 29, 2024
An abstract argumentation framework is a commonly used formalism to provide a static representation of a dialogue. However, the order of enunciation of the arguments in an argumentative dialogue is very important and can affect the outcome of this dialogue. In this paper, we propose a new framework for modelling abstract argumentation graphs, a model that incorporates the order of enunciation of arguments. By taking this order into account, we have the means to deduce a unique outcome for each dialogue, called an extension. We also establish several properties, such as termination and correctness, and discuss two notions of completeness. In particular, we propose a modification of the previous transformation based on a "last enunciated last updated" strategy, which verifies the second form of completeness.
Why do explanations fail? A typology and discussion on failures in XAI
May 22, 2024

As Machine Learning (ML) models achieve unprecedented levels of performance, the XAI domain aims at making these models understandable by presenting end-users with intelligible explanations. Yet, some existing XAI approaches fail to meet expectations: several issues have been reported in the literature, generally pointing out either technical limitations or misinterpretations by users. In this paper, we argue that the resulting harms arise from a complex overlap of multiple failures in XAI, which existing ad-hoc studies fail to capture. This work therefore advocates for a holistic perspective, presenting a systematic investigation of limitations of current XAI methods and their impact on the interpretation of explanations. By distinguishing between system-specific and user-specific failures, we propose a typological framework that helps revealing the nuanced complexities of explanation failures. Leveraging this typology, we also discuss some research directions to help AI practitioners better understand the limitations of XAI systems and enhance the quality of ML explanations.
Mitigating Text Toxicity with Counterfactual Generation
May 16, 2024



Toxicity mitigation consists in rephrasing text in order to remove offensive or harmful meaning. Neural natural language processing (NLP) models have been widely used to target and mitigate textual toxicity. However, existing methods fail to detoxify text while preserving the initial non-toxic meaning at the same time. In this work, we propose to apply counterfactual generation methods from the eXplainable AI (XAI) field to target and mitigate textual toxicity. In particular, we perform text detoxification by applying local feature importance and counterfactual generation methods to a toxicity classifier distinguishing between toxic and non-toxic texts. We carry out text detoxification through counterfactual generation on three datasets and compare our approach to three competitors. Automatic and human evaluations show that recently developed NLP counterfactual generators can mitigate toxicity accurately while better preserving the meaning of the initial text as compared to classical detoxification methods. Finally, we take a step back from using automated detoxification tools, and discuss how to manage the polysemous nature of toxicity and the risk of malicious use of detoxification tools. This work is the first to bridge the gap between counterfactual generation and text detoxification and paves the way towards more practical application of XAI methods.
Self-AMPLIFY: Improving Small Language Models with Self Post Hoc Explanations
Feb 19, 2024Incorporating natural language rationales in the prompt and In-Context Learning (ICL) has led to a significant improvement of Large Language Models (LLMs) performance. However, rationales currently require human-annotation or the use of auxiliary proxy models to target promising samples or generate high-quality rationales. In this work, we propose Self-AMPLIFY to generate automatically rationales from post hoc explanation methods applied to Small Language Models (SLMs) to improve their own performance. Self-AMPLIFY is a 3-step method that targets samples, generates rationales and builds a final prompt to leverage ICL. Self-AMPLIFY performance is evaluated on two SLMs and two datasets requiring reasoning abilities: these experiments show that Self-AMPLIFY achieves good results against competitors. Self-AMPLIFY is the first method to apply post hoc explanation methods to SLM to generate rationales to improve their own performance in a fully automated manner.
Dynamic Interpretability for Model Comparison via Decision Rules
Sep 29, 2023Explainable AI (XAI) methods have mostly been built to investigate and shed light on single machine learning models and are not designed to capture and explain differences between multiple models effectively. This paper addresses the challenge of understanding and explaining differences between machine learning models, which is crucial for model selection, monitoring and lifecycle management in real-world applications. We propose DeltaXplainer, a model-agnostic method for generating rule-based explanations describing the differences between two binary classifiers. To assess the effectiveness of DeltaXplainer, we conduct experiments on synthetic and real-world datasets, covering various model comparison scenarios involving different types of concept drift.
Achieving Diversity in Counterfactual Explanations: a Review and Discussion
May 10, 2023In the field of Explainable Artificial Intelligence (XAI), counterfactual examples explain to a user the predictions of a trained decision model by indicating the modifications to be made to the instance so as to change its associated prediction. These counterfactual examples are generally defined as solutions to an optimization problem whose cost function combines several criteria that quantify desiderata for a good explanation meeting user needs. A large variety of such appropriate properties can be considered, as the user needs are generally unknown and differ from one user to another; their selection and formalization is difficult. To circumvent this issue, several approaches propose to generate, rather than a single one, a set of diverse counterfactual examples to explain a prediction. This paper proposes a review of the numerous, sometimes conflicting, definitions that have been proposed for this notion of diversity. It discusses their underlying principles as well as the hypotheses on the user needs they rely on and proposes to categorize them along several dimensions (explicit vs implicit, universe in which they are defined, level at which they apply), leading to the identification of further research challenges on this topic.
TIGTEC : Token Importance Guided TExt Counterfactuals
Apr 24, 2023
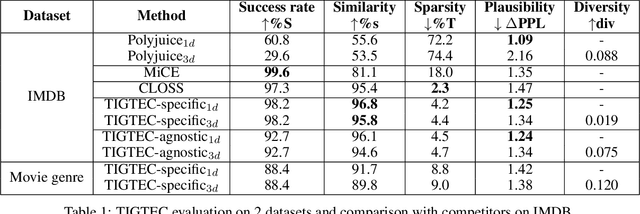
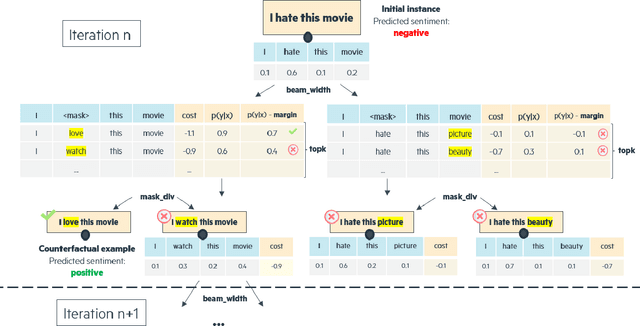
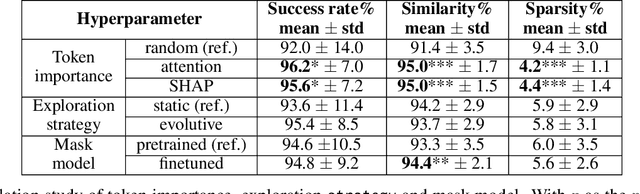
Counterfactual examples explain a prediction by highlighting changes of instance that flip the outcome of a classifier. This paper proposes TIGTEC, an efficient and modular method for generating sparse, plausible and diverse counterfactual explanations for textual data. TIGTEC is a text editing heuristic that targets and modifies words with high contribution using local feature importance. A new attention-based local feature importance is proposed. Counterfactual candidates are generated and assessed with a cost function integrating semantic distance, while the solution space is efficiently explored in a beam search fashion. The conducted experiments show the relevance of TIGTEC in terms of success rate, sparsity, diversity and plausibility. This method can be used in both model-specific or model-agnostic way, which makes it very convenient for generating counterfactual explanations.
Integrating Prior Knowledge in Post-hoc Explanations
Apr 25, 2022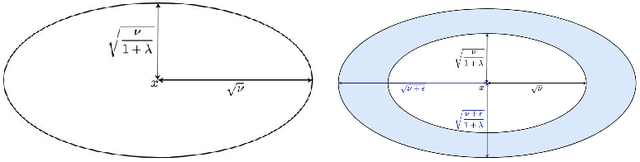
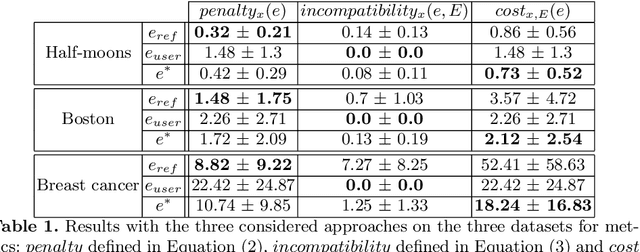
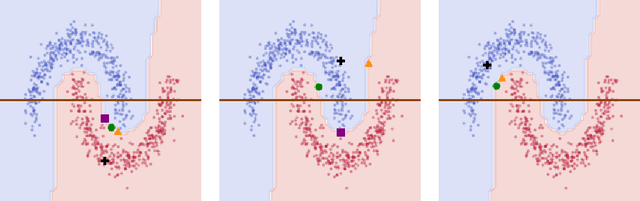
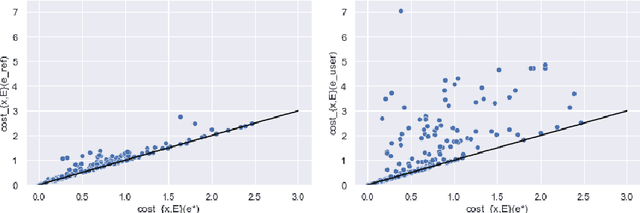
In the field of eXplainable Artificial Intelligence (XAI), post-hoc interpretability methods aim at explaining to a user the predictions of a trained decision model. Integrating prior knowledge into such interpretability methods aims at improving the explanation understandability and allowing for personalised explanations adapted to each user. In this paper, we propose to define a cost function that explicitly integrates prior knowledge into the interpretability objectives: we present a general framework for the optimization problem of post-hoc interpretability methods, and show that user knowledge can thus be integrated to any method by adding a compatibility term in the cost function. We instantiate the proposed formalization in the case of counterfactual explanations and propose a new interpretability method called Knowledge Integration in Counterfactual Explanation (KICE) to optimize it. The paper performs an experimental study on several benchmark data sets to characterize the counterfactual instances generated by KICE, as compared to reference methods.