 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Diversity in Counterfactual Explanations: a Review and Discussion
May 10, 2023In the field of Explainable Artificial Intelligence (XAI), counterfactual examples explain to a user the predictions of a trained decision model by indicating the modifications to be made to the instance so as to change its associated prediction. These counterfactual examples are generally defined as solutions to an optimization problem whose cost function combines several criteria that quantify desiderata for a good explanation meeting user needs. A large variety of such appropriate properties can be considered, as the user needs are generally unknown and differ from one user to another; their selection and formalization is difficult. To circumvent this issue, several approaches propose to generate, rather than a single one, a set of diverse counterfactual examples to explain a prediction. This paper proposes a review of the numerous, sometimes conflicting, definitions that have been proposed for this notion of diversity. It discusses their underlying principles as well as the hypotheses on the user needs they rely on and proposes to categorize them along several dimensions (explicit vs implicit, universe in which they are defined, level at which they apply), leading to the identification of further research challenges on this topic.
Integrating Prior Knowledge in Post-hoc Explanations
Apr 25, 2022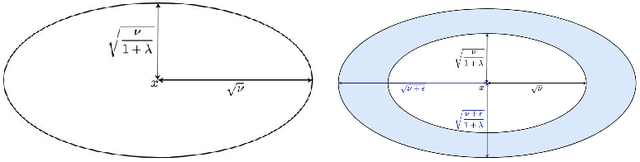
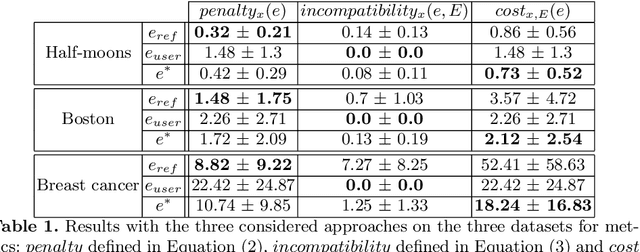
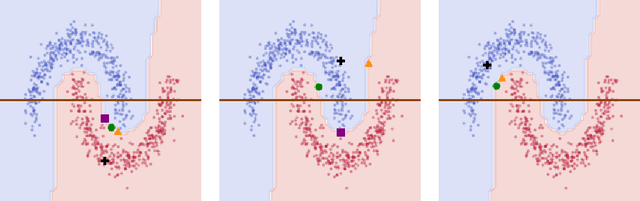
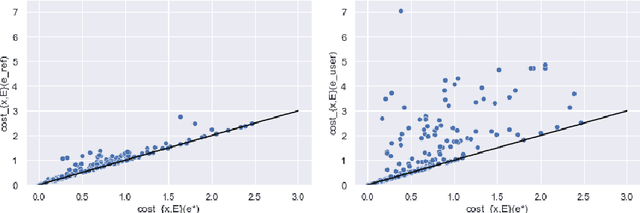
In the field of eXplainable Artificial Intelligence (XAI), post-hoc interpretability methods aim at explaining to a user the predictions of a trained decision model. Integrating prior knowledge into such interpretability methods aims at improving the explanation understandability and allowing for personalised explanations adapted to each user. In this paper, we propose to define a cost function that explicitly integrates prior knowledge into the interpretability objectives: we present a general framework for the optimization problem of post-hoc interpretability methods, and show that user knowledge can thus be integrated to any method by adding a compatibility term in the cost function. We instantiate the proposed formalization in the case of counterfactual explanations and propose a new interpretability method called Knowledge Integration in Counterfactual Explanation (KICE) to optimize it. The paper performs an experimental study on several benchmark data sets to characterize the counterfactual instances generated by KICE, as compared to reference methods.