 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAKE: Steering Activations for Knowledge Editing
Mar 03, 2025As Large Langue Models have been shown to memorize real-world facts, the need to update this knowledge in a controlled and efficient manner arises. Designed with these constraints in mind, Knowledge Editing (KE) approaches propose to alter specific facts in pretrained models. However, they have been shown to suffer from several limitations, including their lack of contextual robustness and their failure to generalize to logical implications related to the fact. To overcome these issues, we propose SAKE, a steering activation method that models a fact to be edited as a distribution rather than a single prompt. Leveraging Optimal Transport, SAKE alters the LLM behavior over a whole fact-related distribution, defined as paraphrases and logical implications. Several numerical experiments demonstrate the effectiveness of this method: SAKE is thus able to perform more robust edits than its existing counterparts.
Controlled Model Debiasing through Minimal and Interpretable Updates
Feb 28, 2025Traditional approaches to learning fair machine learning models often require rebuilding models from scratch, generally without accounting for potentially existing previous models. In a context where models need to be retrained frequently, this can lead to inconsistent model updates, as well as redundant and costly validation testing. To address this limitation, we introduce the notion of controlled model debiasing, a novel supervised learning task relying on two desiderata: that the differences between new fair model and the existing one should be (i) interpretable and (ii) minimal. After providing theoretical guarantees to this new problem, we introduce a novel algorithm for algorithmic fairness, COMMOD, that is both model-agnostic and does not require the sensitive attribute at test time. In addition, our algorithm is explicitly designed to enforce minimal and interpretable changes between biased and debiased predictions -a property that, while highly desirable in high-stakes applications, is rarely prioritized as an explicit objective in fairness literature. Our approach combines a concept-based architecture and adversarial learning and we demonstrate through empirical results that it achieves comparable performance to state-of-the-art debiasing methods while performing minimal and interpretable prediction changes.
Regret-Optimized Portfolio Enhancement through Deep Reinforcement Learning and Future Looking Rewards
Feb 04, 2025This paper introduces a novel agent-based approach for enhancing existing portfolio strategies using Proximal Policy Optimization (PPO). Rather than focusing solely on traditional portfolio construction, our approach aims to improve an already high-performing strategy through dynamic rebalancing driven by PPO and Oracle agents. Our target is to enhance the traditional 60/40 benchmark (60% stocks, 40% bonds) by employing the Regret-based Sharpe reward function. To address the impact of transaction fee frictions and prevent signal loss, we develop a transaction cost scheduler. We introduce a future-looking reward function and employ synthetic data training through a circular block bootstrap method to facilitate the learning of generalizable allocation strategies. We focus on two key evaluation measures: return and maximum drawdown. Given the high stochasticity of financial markets, we train 20 independent agents each period and evaluate their average performance against the benchmark. Our method not only enhances the performance of the existing portfolio strategy through strategic rebalancing but also demonstrates strong results compared to other baselines.
Post-processing fairness with minimal changes
Aug 27, 2024In this paper, we introduce a novel post-processing algorithm that is both model-agnostic and does not require the sensitive attribute at test time. In addition, our algorithm is explicitly designed to enforce minimal changes between biased and debiased predictions; a property that, while highly desirable, is rarely prioritized as an explicit objective in fairness literature. Our approach leverages a multiplicative factor applied to the logit value of probability scores produced by a black-box classifier. We demonstrate the efficacy of our method through empirical evaluations, comparing its performance against other four debiasing algorithms on two widely used datasets in fairness research.
Why do explanations fail? A typology and discussion on failures in XAI
May 22, 2024

As Machine Learning (ML) models achieve unprecedented levels of performance, the XAI domain aims at making these models understandable by presenting end-users with intelligible explanations. Yet, some existing XAI approaches fail to meet expectations: several issues have been reported in the literature, generally pointing out either technical limitations or misinterpretations by users. In this paper, we argue that the resulting harms arise from a complex overlap of multiple failures in XAI, which existing ad-hoc studies fail to capture. This work therefore advocates for a holistic perspective, presenting a systematic investigation of limitations of current XAI methods and their impact on the interpretation of explanations. By distinguishing between system-specific and user-specific failures, we propose a typological framework that helps revealing the nuanced complexities of explanation failures. Leveraging this typology, we also discuss some research directions to help AI practitioners better understand the limitations of XAI systems and enhance the quality of ML explanations.
OptiGrad: A Fair and more Efficient Price Elasticity Optimization via a Gradient Based Learning
Apr 16, 2024This paper presents a novel approach to optimizing profit margins in non-life insurance markets through a gradient descent-based method, targeting three key objectives: 1) maximizing profit margins, 2) ensuring conversion rates, and 3) enforcing fairness criteria such as demographic parity (DP). Traditional pricing optimization, which heavily lean on linear and semi definite programming, encounter challenges in balancing profitability and fairness. These challenges become especially pronounced in situations that necessitate continuous rate adjustments and the incorporation of fairness criteria. Specifically, indirect Ratebook optimization, a widely-used method for new business price setting, relies on predictor models such as XGBoost or GLMs/GAMs to estimate on downstream individually optimized prices. However, this strategy is prone to sequential errors and struggles to effectively manage optimizations for continuous rate scenarios. In practice, to save time actuaries frequently opt for optimization within discrete intervals (e.g., range of [-20\%, +20\%] with fix increments) leading to approximate estimations. Moreover, to circumvent infeasible solutions they often use relaxed constraints leading to suboptimal pricing strategies. The reverse-engineered nature of traditional models complicates the enforcement of fairness and can lead to biased outcomes. Our method addresses these challenges by employing a direct optimization strategy in the continuous space of rates and by embedding fairness through an adversarial predictor model. This innovation not only reduces sequential errors and simplifies the complexities found in traditional models but also directly integrates fairness measures into the commercial premium calculation. We demonstrate improved margin performance and stronger enforcement of fairness highlighting the critical need to evolve existing pricing strategies.
On the Fairness ROAD: Robust Optimization for Adversarial Debiasing
Oct 27, 2023In the field of algorithmic fairness, significant attention has been put on group fairness criteria, such as Demographic Parity and Equalized Odds. Nevertheless, these objectives, measured as global averages, have raised concerns about persistent local disparities between sensitive groups. In this work, we address the problem of local fairness, which ensures that the predictor is unbiased not only in terms of expectations over the whole population, but also within any subregion of the feature space, unknown at training time. To enforce this objective, we introduce ROAD, a novel approach that leverages the Distributionally Robust Optimization (DRO) framework within a fair adversarial learning objective, where an adversary tries to infer the sensitive attribute from the predictions. Using an instance-level re-weighting strategy, ROAD is designed to prioritize inputs that are likely to be locally unfair, i.e. where the adversary faces the least difficulty in reconstructing the sensitive attribute. Numerical experiments demonstrate the effectiveness of our method: it achieves Pareto dominance with respect to local fairness and accuracy for a given global fairness level across three standard datasets, and also enhances fairness generalization under distribution shift.
Achieving Diversity in Counterfactual Explanations: a Review and Discussion
May 10, 2023In the field of Explainable Artificial Intelligence (XAI), counterfactual examples explain to a user the predictions of a trained decision model by indicating the modifications to be made to the instance so as to change its associated prediction. These counterfactual examples are generally defined as solutions to an optimization problem whose cost function combines several criteria that quantify desiderata for a good explanation meeting user needs. A large variety of such appropriate properties can be considered, as the user needs are generally unknown and differ from one user to another; their selection and formalization is difficult. To circumvent this issue, several approaches propose to generate, rather than a single one, a set of diverse counterfactual examples to explain a prediction. This paper proposes a review of the numerous, sometimes conflicting, definitions that have been proposed for this notion of diversity. It discusses their underlying principles as well as the hypotheses on the user needs they rely on and proposes to categorize them along several dimensions (explicit vs implicit, universe in which they are defined, level at which they apply), leading to the identification of further research challenges on this topic.
When Mitigating Bias is Unfair: A Comprehensive Study on the Impact of Bias Mitigation Algorithms
Feb 14, 2023



Most works on the fairness of machine learning systems focus on the blind optimization of common fairness metrics, such as Demographic Parity and Equalized Odds. In this paper, we conduct a comparative study of several bias mitigation approaches to investigate their behaviors at a fine grain, the prediction level. Our objective is to characterize the differences between fair models obtained with different approaches. With comparable performances in fairness and accuracy, are the different bias mitigation approaches impacting a similar number of individuals? Do they mitigate bias in a similar way? Do they affect the same individuals when debiasing a model? Our findings show that bias mitigation approaches differ a lot in their strategies, both in the number of impacted individuals and the populations targeted. More surprisingly, we show these results even apply for several runs of the same mitigation approach. These findings raise questions about the limitations of the current group fairness metrics, as well as the arbitrariness, hence unfairness, of the whole debiasing process.
Integrating Prior Knowledge in Post-hoc Explanations
Apr 25, 2022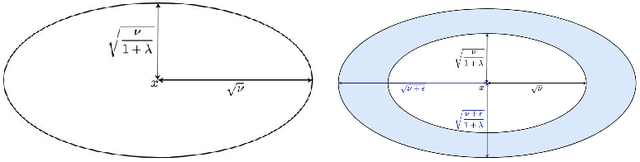
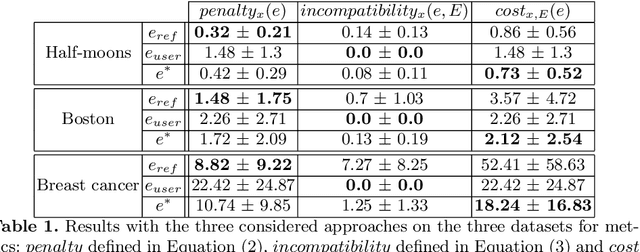
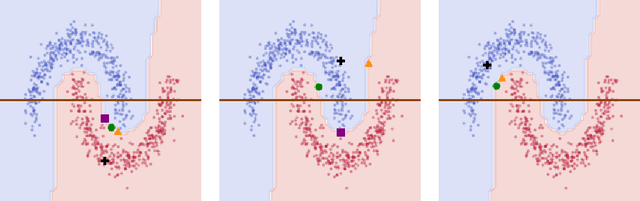
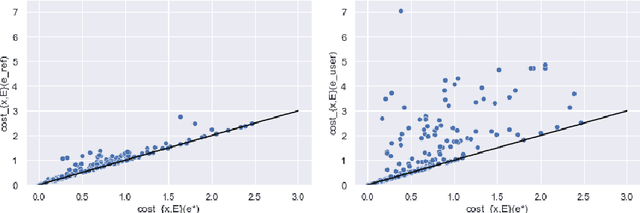
In the field of eXplainable Artificial Intelligence (XAI), post-hoc interpretability methods aim at explaining to a user the predictions of a trained decision model. Integrating prior knowledge into such interpretability methods aims at improving the explanation understandability and allowing for personalised explanations adapted to each user. In this paper, we propose to define a cost function that explicitly integrates prior knowledge into the interpretability objectives: we present a general framework for the optimization problem of post-hoc interpretability methods, and show that user knowledge can thus be integrated to any method by adding a compatibility term in the cost function. We instantiate the proposed formalization in the case of counterfactual explanations and propose a new interpretability method called Knowledge Integration in Counterfactual Explanation (KICE) to optimize it. The paper performs an experimental study on several benchmark data sets to characterize the counterfactual instances generated by KICE, as compared to reference methods.