 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment Reduces Expressed but Not Encoded Gender Bias: A Unified Framework and Study
Mar 25, 2026During training, Large Language Models (LLMs) learn social regularities that can lead to gender bias in downstream applications. Most mitigation efforts focus on reducing bias in generated outputs, typically evaluated on structured benchmarks, which raises two concerns: output-level evaluation does not reveal whether alignment modifies the model's underlying representations, and structured benchmarks may not reflect realistic usage scenarios. We propose a unified framework to jointly analyze intrinsic and extrinsic gender bias in LLMs using identical neutral prompts, enabling direct comparison between gender-related information encoded in internal representations and bias expressed in generated outputs. Contrary to prior work reporting weak or inconsistent correlations, we find a consistent association between latent gender information and expressed bias when measured under the unified protocol. We further examine the effect of alignment through supervised fine-tuning aimed at reducing gender bias. Our results suggest that while the latter indeed reduces expressed bias, measurable gender-related associations are still present in internal representations, and can be reactivated under adversarial prompting. Finally, we consider two realistic settings and show that debiasing effects observed on structured benchmarks do not necessarily generalize, e.g., to the case of story generation.
Post-processing fairness with minimal changes
Aug 27, 2024In this paper, we introduce a novel post-processing algorithm that is both model-agnostic and does not require the sensitive attribute at test time. In addition, our algorithm is explicitly designed to enforce minimal changes between biased and debiased predictions; a property that, while highly desirable, is rarely prioritized as an explicit objective in fairness literature. Our approach leverages a multiplicative factor applied to the logit value of probability scores produced by a black-box classifier. We demonstrate the efficacy of our method through empirical evaluations, comparing its performance against other four debiasing algorithms on two widely used datasets in fairness research.
Dynamic Interpretability for Model Comparison via Decision Rules
Sep 29, 2023Explainable AI (XAI) methods have mostly been built to investigate and shed light on single machine learning models and are not designed to capture and explain differences between multiple models effectively. This paper addresses the challenge of understanding and explaining differences between machine learning models, which is crucial for model selection, monitoring and lifecycle management in real-world applications. We propose DeltaXplainer, a model-agnostic method for generating rule-based explanations describing the differences between two binary classifiers. To assess the effectiveness of DeltaXplainer, we conduct experiments on synthetic and real-world datasets, covering various model comparison scenarios involving different types of concept drift.
How to choose an Explainability Method? Towards a Methodical Implementation of XAI in Practice
Jul 09, 2021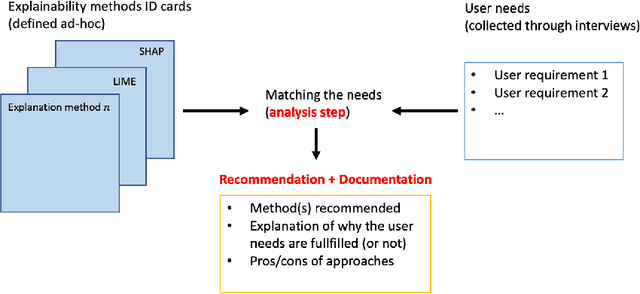
Explainability is becoming an important requirement for organizations that make use of automated decision-making due to regulatory initiatives and a shift in public awareness. Various and significantly different algorithmic methods to provide this explainability have been introduced in the field, but the existing literature in the machine learning community has paid little attention to the stakeholder whose needs are rather studied in the human-computer interface community. Therefore, organizations that want or need to provide this explainability are confronted with the selection of an appropriate method for their use case. In this paper, we argue there is a need for a methodology to bridge the gap between stakeholder needs and explanation methods. We present our ongoing work on creating this methodology to help data scientists in the process of providing explainability to stakeholders. In particular, our contributions include documents used to characterize XAI methods and user requirements (shown in Appendix), which our methodology builds upon.
Understanding surrogate explanations: the interplay between complexity, fidelity and coverage
Jul 09, 2021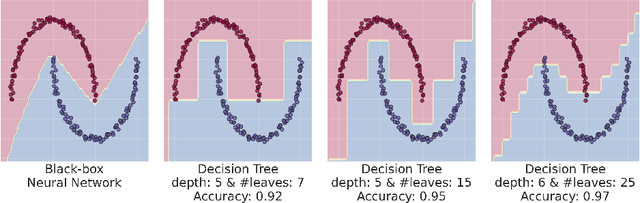
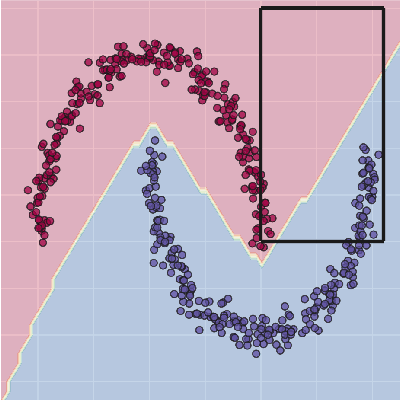
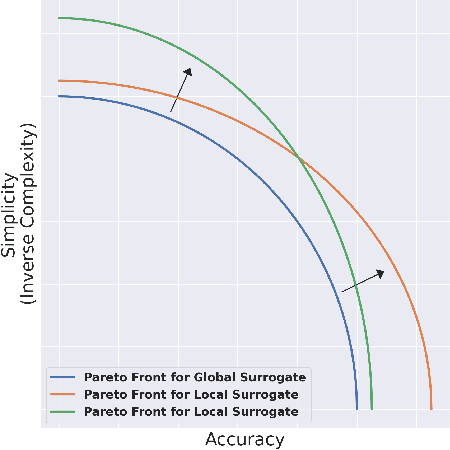
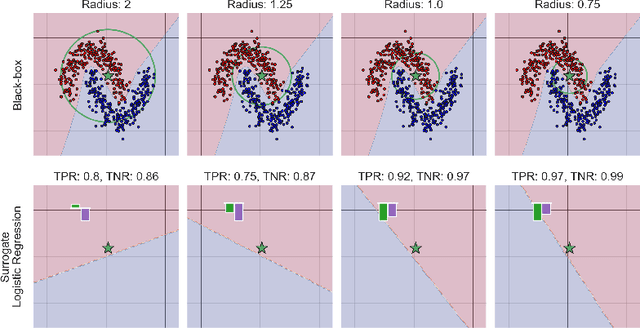
This paper analyses the fundamental ingredients behind surrogate explanations to provide a better understanding of their inner workings. We start our exposition by considering global surrogates, describing the trade-off between complexity of the surrogate and fidelity to the black-box being modelled. We show that transitioning from global to local - reducing coverage - allows for more favourable conditions on the Pareto frontier of fidelity-complexity of a surrogate. We discuss the interplay between complexity, fidelity and coverage, and consider how different user needs can lead to problem formulations where these are either constraints or penalties. We also present experiments that demonstrate how the local surrogate interpretability procedure can be made interactive and lead to better explanations.
On the overlooked issue of defining explanation objectives for local-surrogate explainers
Jun 10, 2021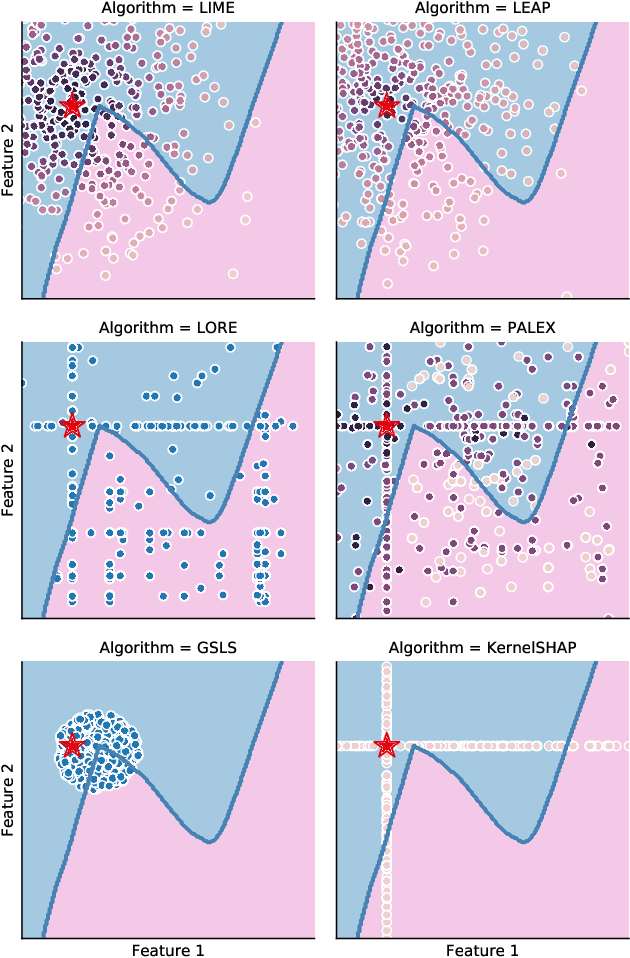

Local surrogate approaches for explaining machine learning model predictions have appealing properties, such as being model-agnostic and flexible in their modelling. Several methods exist that fit this description and share this goal. However, despite their shared overall procedure, they set out different objectives, extract different information from the black-box, and consequently produce diverse explanations, that are -- in general -- incomparable. In this work we review the similarities and differences amongst multiple methods, with a particular focus on what information they extract from the model, as this has large impact on the output: the explanation. We discuss the implications of the lack of agreement, and clarity, amongst the methods' objectives on the research and practice of explainability.
Understanding Prediction Discrepancies in Machine Learning Classifiers
Apr 12, 2021

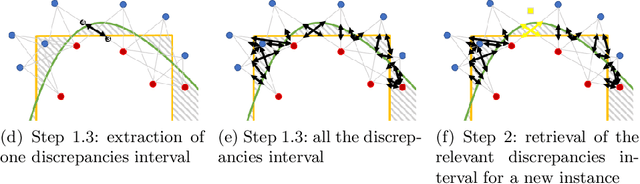

A multitude of classifiers can be trained on the same data to achieve similar performances during test time, while having learned significantly different classification patterns. This phenomenon, which we call prediction discrepancies, is often associated with the blind selection of one model instead of another with similar performances. When making a choice, the machine learning practitioner has no understanding on the differences between models, their limits, where they agree and where they don't. But his/her choice will result in concrete consequences for instances to be classified in the discrepancy zone, since the final decision will be based on the selected classification pattern. Besides the arbitrary nature of the result, a bad choice could have further negative consequences such as loss of opportunity or lack of fairness. This paper proposes to address this question by analyzing the prediction discrepancies in a pool of best-performing models trained on the same data. A model-agnostic algorithm, DIG, is proposed to capture and explain discrepancies locally, to enable the practitioner to make the best educated decision when selecting a model by anticipating its potential undesired consequences. All the code to reproduce the experiments is available.
QUACKIE: A NLP Classification Task With Ground Truth Explanations
Dec 27, 2020
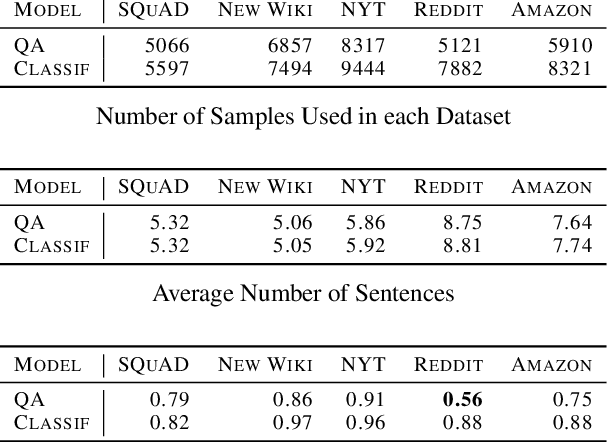
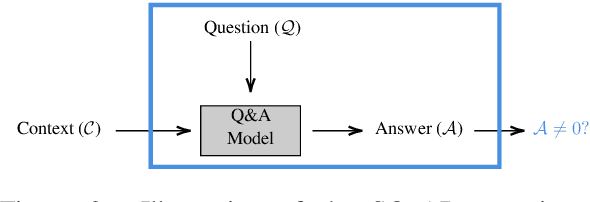

NLP Interpretability aims to increase trust in model predictions. This makes evaluating interpretability approaches a pressing issue. There are multiple datasets for evaluating NLP Interpretability, but their dependence on human provided ground truths raises questions about their unbiasedness. In this work, we take a different approach and formulate a specific classification task by diverting question-answering datasets. For this custom classification task, the interpretability ground-truth arises directly from the definition of the classification problem. We use this method to propose a benchmark and lay the groundwork for future research in NLP interpretability by evaluating a wide range of current state of the art methods.
Sentence-Based Model Agnostic NLP Interpretability
Dec 27, 2020
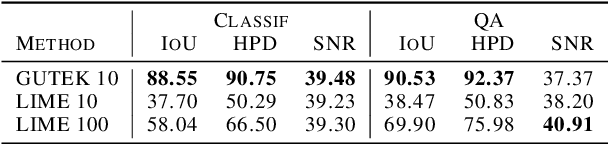

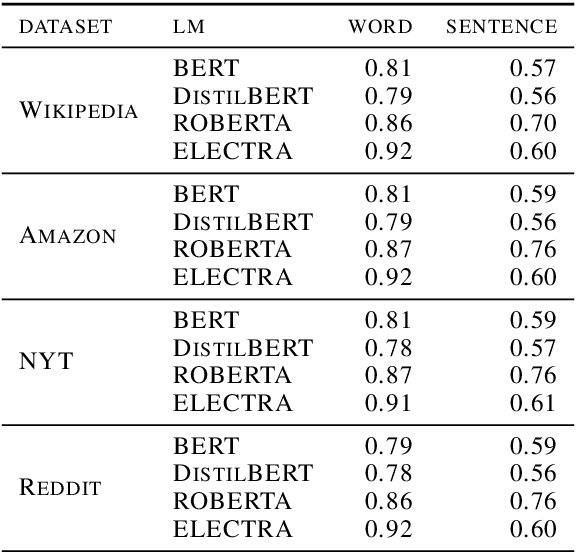
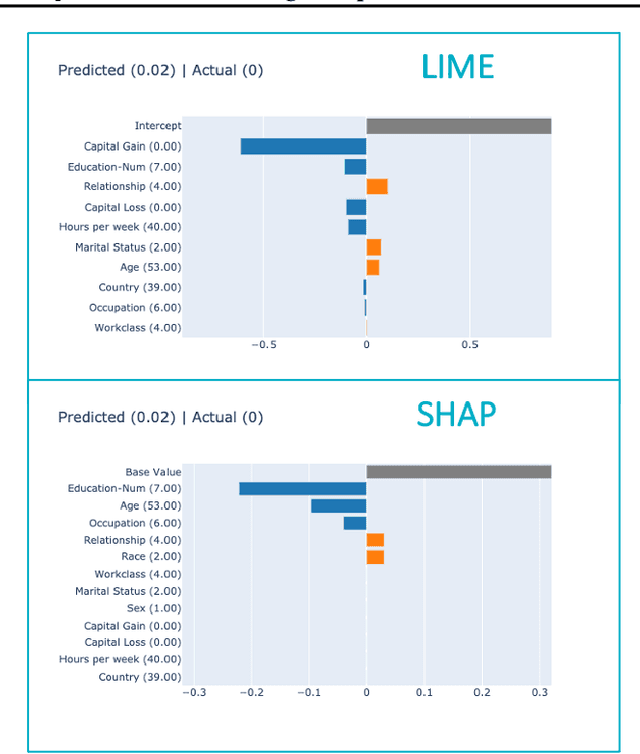
Today, interpretability of Black-Box Natural Language Processing (NLP) models based on surrogates, like LIME or SHAP, uses word-based sampling to build the explanations. In this paper we explore the use of sentences to tackle NLP interpretability. While this choice may seem straight forward, we show that, when using complex classifiers like BERT, the word-based approach raises issues not only of computational complexity, but also of an out of distribution sampling, eventually leading to non founded explanations. By using sentences, the altered text remains in-distribution and the dimensionality of the problem is reduced for better fidelity to the black-box at comparable computational complexity.
Imperceptible Adversarial Attacks on Tabular Data
Dec 13, 2019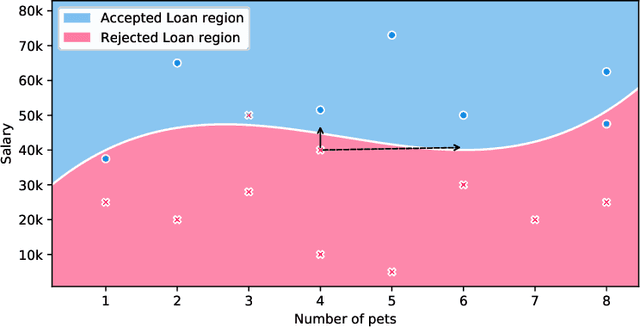
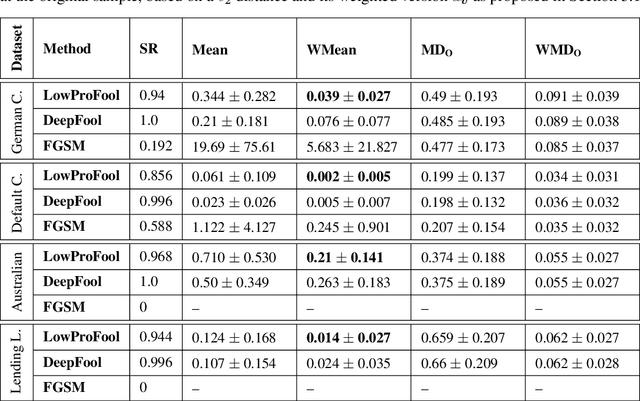
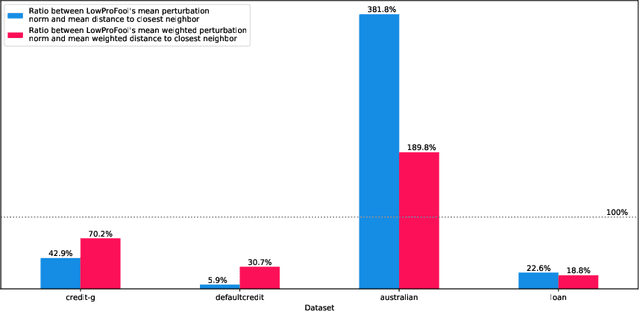
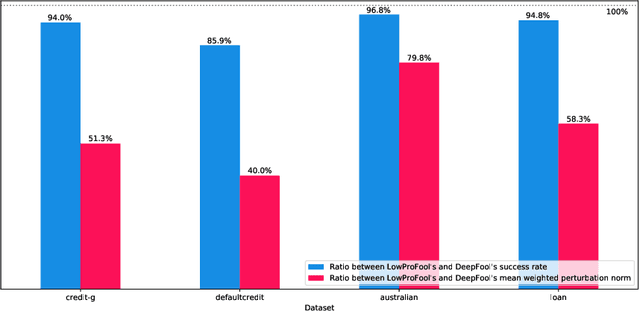
Security of machine learning models is a concern as they may face adversarial attacks for unwarranted advantageous decisions. While research on the topic has mainly been focusing on the image domain, numerous industrial applications, in particular in finance, rely on standard tabular data. In this paper, we discuss the notion of adversarial examples in the tabular domain. We propose a formalization based on the imperceptibility of attacks in the tabular domain leading to an approach to generate imperceptible adversarial examples. Experiments show that we can generate imperceptible adversarial examples with a high fooling rate.