Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence-Based Model Agnostic NLP Interpretability
Paper and Code
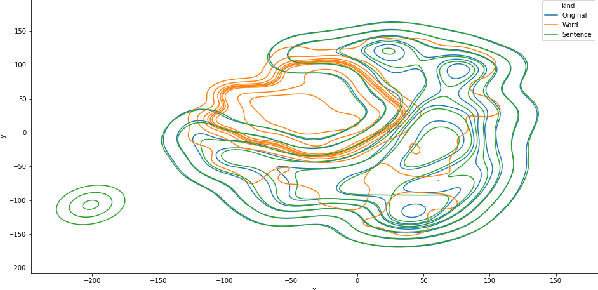
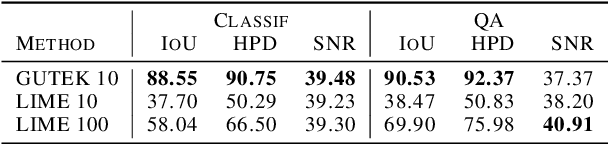

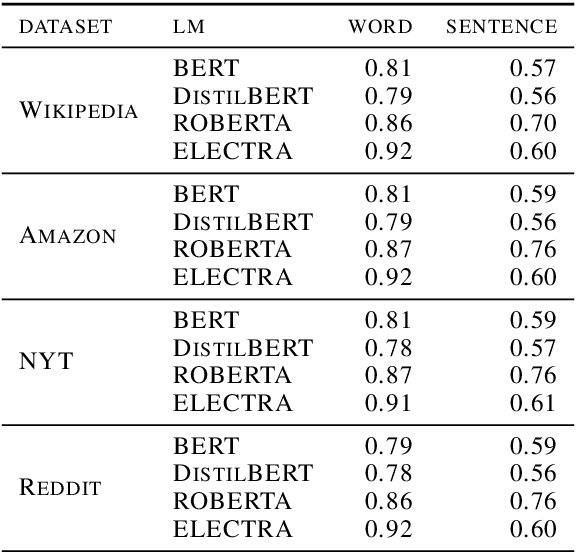
Today, interpretability of Black-Box Natural Language Processing (NLP) models based on surrogates, like LIME or SHAP, uses word-based sampling to build the explanations. In this paper we explore the use of sentences to tackle NLP interpretability. While this choice may seem straight forward, we show that, when using complex classifiers like BERT, the word-based approach raises issues not only of computational complexity, but also of an out of distribution sampling, eventually leading to non founded explanations. By using sentences, the altered text remains in-distribution and the dimensionality of the problem is reduced for better fidelity to the black-box at comparable computational complexity.
View paper on