 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance and Evaluation of Narrativity in Natural Language AI Explanations
Apr 20, 2026Explainable AI (XAI) aims to make the behaviour of machine learning models interpretable, yet many explanation methods remain difficult to understand. The integration of Natural Language Generation into XAI aims to deliver explanations in textual form, making them more accessible to practitioners. Current approaches, however, largely yield static lists of feature importances. Although such explanations indicate what influences the prediction, they do not explain why the prediction occurs. In this study, we draw on insights from social sciences and linguistics, and argue that XAI explanations should be presented in the form of narratives. Narrative explanations support human understanding through four defining properties: continuous structure, cause-effect mechanisms, linguistic fluency, and lexical diversity. We show that standard Natural Language Processing (NLP) metrics based solely on token probability or word frequency fail to capture these properties and can be matched or exceeded by tautological text that conveys no explanatory content. To address this issue, we propose seven automatic metrics that quantify the narrative quality of explanations along the four identified dimensions. We benchmark current state-of-the-art explanation generation methods on six datasets and show that the proposed metrics separate descriptive from narrative explanations more reliably than standard NLP metrics. Finally, to further advance the field, we propose a set of problem-agnostic XAI Narrative generation rules for producing natural language XAI explanations, so that the resulting XAI Narratives exhibit stronger narrative properties and align with the findings from the linguistic and social science literature.
An Agentic Approach to Generating XAI-Narratives
Mar 20, 2026Explainable AI (XAI) research has experienced substantial growth in recent years. Existing XAI methods, however, have been criticized for being technical and expert-oriented, motivating the development of more interpretable and accessible explanations. In response, large language model (LLM)-generated XAI narratives have been proposed as a promising approach for translating post-hoc explanations into more accessible, natural-language explanations. In this work, we propose a multi-agent framework for XAI narrative generation and refinement. The framework comprises the Narrator, which generates and revises narratives based on feedback from multiple Critic Agents on faithfulness and coherence metrics, thereby enabling narrative improvement through iteration. We design five agentic systems (Basic Design, Critic Design, Critic-Rule Design, Coherent Design, and Coherent-Rule Design) and systematically evaluate their effectiveness across five LLMs on five tabular datasets. Results validate that the Basic Design, the Critic Design, and the Critic-Rule Design are effective in improving the faithfulness of narratives across all LLMs. Claude-4.5-Sonnet on Basic Design performs best, reducing the number of unfaithful narratives by 90% after three rounds of iteration. To address recurrent issues, we further introduce an ensemble strategy based on majority voting. This approach consistently enhances performance for four LLMs, except for DeepSeek-V3.2-Exp. These findings highlight the potential of agentic systems to produce faithful and coherent XAI narratives.
Would a Large Language Model Pay Extra for a View? Inferring Willingness to Pay from Subjective Choices
Feb 10, 2026As Large Language Models (LLMs) are increasingly deployed in applications such as travel assistance and purchasing support, they are often required to make subjective choices on behalf of users in settings where no objectively correct answer exists. We study LLM decision-making in a travel-assistant context by presenting models with choice dilemmas and analyzing their responses using multinomial logit models to derive implied willingness to pay (WTP) estimates. These WTP values are subsequently compared to human benchmark values from the economics literature. In addition to a baseline setting, we examine how model behavior changes under more realistic conditions, including the provision of information about users' past choices and persona-based prompting. Our results show that while meaningful WTP values can be derived for larger LLMs, they also display systematic deviations at the attribute level. Additionally, they tend to overestimate human WTP overall, particularly when expensive options or business-oriented personas are introduced. Conditioning models on prior preferences for cheaper options yields valuations that are closer to human benchmarks. Overall, our findings highlight both the potential and the limitations of using LLMs for subjective decision support and underscore the importance of careful model selection, prompt design, and user representation when deploying such systems in practice.
On the Definition and Detection of Cherry-Picking in Counterfactual Explanations
Jan 08, 2026Counterfactual explanations are widely used to communicate how inputs must change for a model to alter its prediction. For a single instance, many valid counterfactuals can exist, which leaves open the possibility for an explanation provider to cherry-pick explanations that better suit a narrative of their choice, highlighting favourable behaviour and withholding examples that reveal problematic behaviour. We formally define cherry-picking for counterfactual explanations in terms of an admissible explanation space, specified by the generation procedure, and a utility function. We then study to what extent an external auditor can detect such manipulation. Considering three levels of access to the explanation process: full procedural access, partial procedural access, and explanation-only access, we show that detection is extremely limited in practice. Even with full procedural access, cherry-picked explanations can remain difficult to distinguish from non cherry-picked explanations, because the multiplicity of valid counterfactuals and flexibility in the explanation specification provide sufficient degrees of freedom to mask deliberate selection. Empirically, we demonstrate that this variability often exceeds the effect of cherry-picking on standard counterfactual quality metrics such as proximity, plausibility, and sparsity, making cherry-picked explanations statistically indistinguishable from baseline explanations. We argue that safeguards should therefore prioritise reproducibility, standardisation, and procedural constraints over post-hoc detection, and we provide recommendations for algorithm developers, explanation providers, and auditors.
From What Ifs to Insights: Counterfactuals in Causal Inference vs. Explainable AI
May 19, 2025Counterfactuals play a pivotal role in the two distinct data science fields of causal inference (CI) and explainable artificial intelligence (XAI). While the core idea behind counterfactuals remains the same in both fields--the examination of what would have happened under different circumstances--there are key differences in how they are used and interpreted. We introduce a formal definition that encompasses the multi-faceted concept of the counterfactual in CI and XAI. We then discuss how counterfactuals are used, evaluated, generated, and operationalized in CI vs. XAI, highlighting conceptual and practical differences. By comparing and contrasting the two, we hope to identify opportunities for cross-fertilization across CI and XAI.
Exploring the generalization of LLM truth directions on conversational formats
May 14, 2025Several recent works argue that LLMs have a universal truth direction where true and false statements are linearly separable in the activation space of the model. It has been demonstrated that linear probes trained on a single hidden state of the model already generalize across a range of topics and might even be used for lie detection in LLM conversations. In this work we explore how this truth direction generalizes between various conversational formats. We find good generalization between short conversations that end on a lie, but poor generalization to longer formats where the lie appears earlier in the input prompt. We propose a solution that significantly improves this type of generalization by adding a fixed key phrase at the end of each conversation. Our results highlight the challenges towards reliable LLM lie detectors that generalize to new settings.
Beware of "Explanations" of AI
Apr 09, 2025Understanding the decisions made and actions taken by increasingly complex AI system remains a key challenge. This has led to an expanding field of research in explainable artificial intelligence (XAI), highlighting the potential of explanations to enhance trust, support adoption, and meet regulatory standards. However, the question of what constitutes a "good" explanation is dependent on the goals, stakeholders, and context. At a high level, psychological insights such as the concept of mental model alignment can offer guidance, but success in practice is challenging due to social and technical factors. As a result of this ill-defined nature of the problem, explanations can be of poor quality (e.g. unfaithful, irrelevant, or incoherent), potentially leading to substantial risks. Instead of fostering trust and safety, poorly designed explanations can actually cause harm, including wrong decisions, privacy violations, manipulation, and even reduced AI adoption. Therefore, we caution stakeholders to beware of explanations of AI: while they can be vital, they are not automatically a remedy for transparency or responsible AI adoption, and their misuse or limitations can exacerbate harm. Attention to these caveats can help guide future research to improve the quality and impact of AI explanations.
How good is my story? Towards quantitative metrics for evaluating LLM-generated XAI narratives
Dec 13, 2024A rapidly developing application of LLMs in XAI is to convert quantitative explanations such as SHAP into user-friendly narratives to explain the decisions made by smaller prediction models. Evaluating the narratives without relying on human preference studies or surveys is becoming increasingly important in this field. In this work we propose a framework and explore several automated metrics to evaluate LLM-generated narratives for explanations of tabular classification tasks. We apply our approach to compare several state-of-the-art LLMs across different datasets and prompt types. As a demonstration of their utility, these metrics allow us to identify new challenges related to LLM hallucinations for XAI narratives.
GraphXAIN: Narratives to Explain Graph Neural Networks
Nov 04, 2024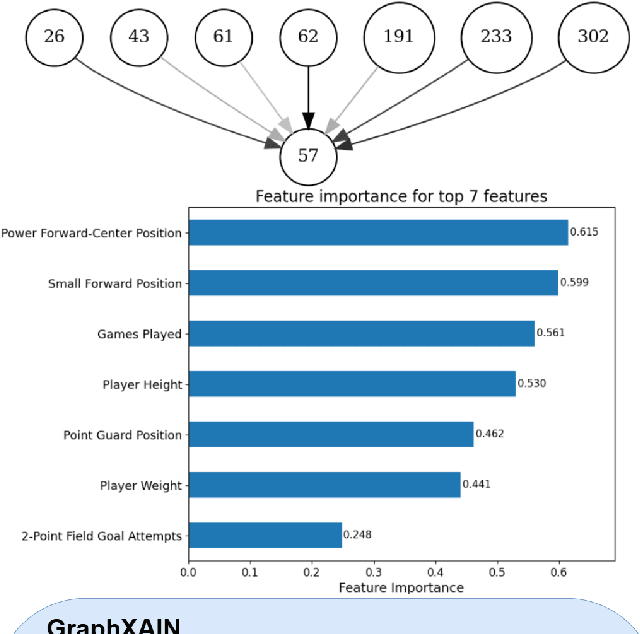
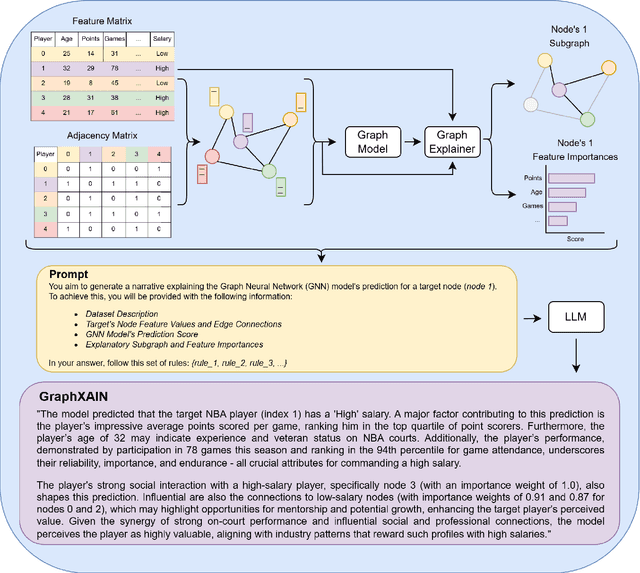
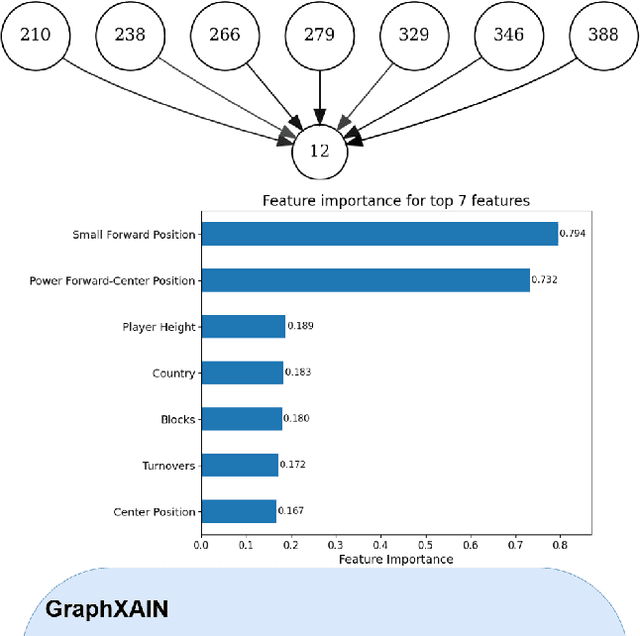
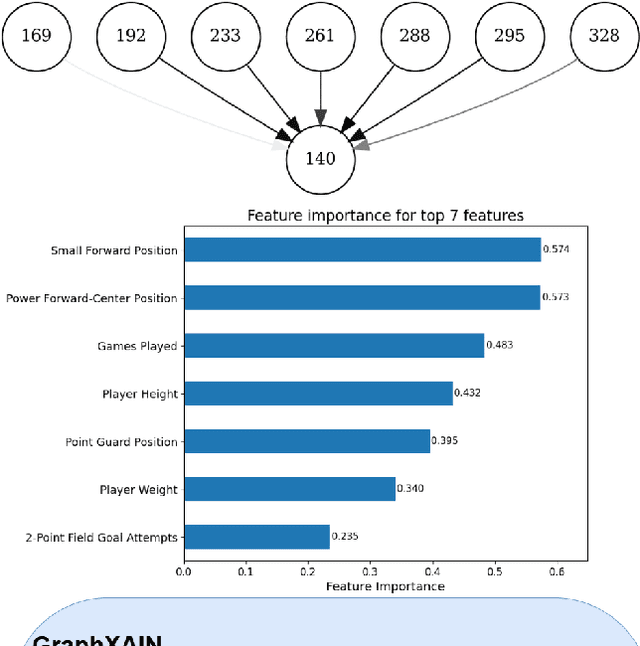
Graph Neural Networks (GNNs) are a powerful technique for machine learning on graph-structured data, yet they pose interpretability challenges, especially for non-expert users. Existing GNN explanation methods often yield technical outputs such as subgraphs and feature importance scores, which are not easily understood. Building on recent insights from social science and other Explainable AI (XAI) methods, we propose GraphXAIN, a natural language narrative that explains individual predictions made by GNNs. We present a model-agnostic and explainer-agnostic XAI approach that complements graph explainers by generating GraphXAINs, using Large Language Models (LLMs) and integrating graph data, individual predictions from GNNs, explanatory subgraphs, and feature importances. We define XAI Narratives and XAI Descriptions, highlighting their distinctions and emphasizing the importance of narrative principles in effective explanations. By incorporating natural language narratives, our approach supports graph practitioners and non-expert users, aligning with social science research on explainability and enhancing user understanding and trust in complex GNN models. We demonstrate GraphXAIN's capabilities on a real-world graph dataset, illustrating how its generated narratives can aid understanding compared to traditional graph explainer outputs or other descriptive explanation methods.
Exposing Image Classifier Shortcuts with Counterfactual Frequency (CoF) Tables
May 24, 2024The rise of deep learning in image classification has brought unprecedented accuracy but also highlighted a key issue: the use of 'shortcuts' by models. Such shortcuts are easy-to-learn patterns from the training data that fail to generalise to new data. Examples include the use of a copyright watermark to recognise horses, snowy background to recognise huskies, or ink markings to detect malignant skin lesions. The explainable AI (XAI) community has suggested using instance-level explanations to detect shortcuts without external data, but this requires the examination of many explanations to confirm the presence of such shortcuts, making it a labour-intensive process. To address these challenges, we introduce Counterfactual Frequency (CoF) tables, a novel approach that aggregates instance-based explanations into global insights, and exposes shortcuts. The aggregation implies the need for some semantic concepts to be used in the explanations, which we solve by labelling the segments of an image. We demonstrate the utility of CoF tables across several datasets, revealing the shortcuts learned from them.