 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Definition and Detection of Cherry-Picking in Counterfactual Explanations
Jan 08, 2026Counterfactual explanations are widely used to communicate how inputs must change for a model to alter its prediction. For a single instance, many valid counterfactuals can exist, which leaves open the possibility for an explanation provider to cherry-pick explanations that better suit a narrative of their choice, highlighting favourable behaviour and withholding examples that reveal problematic behaviour. We formally define cherry-picking for counterfactual explanations in terms of an admissible explanation space, specified by the generation procedure, and a utility function. We then study to what extent an external auditor can detect such manipulation. Considering three levels of access to the explanation process: full procedural access, partial procedural access, and explanation-only access, we show that detection is extremely limited in practice. Even with full procedural access, cherry-picked explanations can remain difficult to distinguish from non cherry-picked explanations, because the multiplicity of valid counterfactuals and flexibility in the explanation specification provide sufficient degrees of freedom to mask deliberate selection. Empirically, we demonstrate that this variability often exceeds the effect of cherry-picking on standard counterfactual quality metrics such as proximity, plausibility, and sparsity, making cherry-picked explanations statistically indistinguishable from baseline explanations. We argue that safeguards should therefore prioritise reproducibility, standardisation, and procedural constraints over post-hoc detection, and we provide recommendations for algorithm developers, explanation providers, and auditors.
Prompt-Counterfactual Explanations for Generative AI System Behavior
Jan 06, 2026As generative AI systems become integrated into real-world applications, organizations increasingly need to be able to understand and interpret their behavior. In particular, decision-makers need to understand what causes generative AI systems to exhibit specific output characteristics. Within this general topic, this paper examines a key question: what is it about the input -- the prompt -- that causes an LLM-based generative AI system to produce output that exhibits specific characteristics, such as toxicity, negative sentiment, or political bias. To examine this question, we adapt a common technique from the Explainable AI literature: counterfactual explanations. We explain why traditional counterfactual explanations cannot be applied directly to generative AI systems, due to several differences in how generative AI systems function. We then propose a flexible framework that adapts counterfactual explanations to non-deterministic, generative AI systems in scenarios where downstream classifiers can reveal key characteristics of their outputs. Based on this framework, we introduce an algorithm for generating prompt-counterfactual explanations (PCEs). Finally, we demonstrate the production of counterfactual explanations for generative AI systems with three case studies, examining different output characteristics (viz., political leaning, toxicity, and sentiment). The case studies further show that PCEs can streamline prompt engineering to suppress undesirable output characteristics and can enhance red-teaming efforts to uncover additional prompts that elicit undesirable outputs. Ultimately, this work lays a foundation for prompt-focused interpretability in generative AI: a capability that will become indispensable as these models are entrusted with higher-stakes tasks and subject to emerging regulatory requirements for transparency and accountability.
Beware of "Explanations" of AI
Apr 09, 2025Understanding the decisions made and actions taken by increasingly complex AI system remains a key challenge. This has led to an expanding field of research in explainable artificial intelligence (XAI), highlighting the potential of explanations to enhance trust, support adoption, and meet regulatory standards. However, the question of what constitutes a "good" explanation is dependent on the goals, stakeholders, and context. At a high level, psychological insights such as the concept of mental model alignment can offer guidance, but success in practice is challenging due to social and technical factors. As a result of this ill-defined nature of the problem, explanations can be of poor quality (e.g. unfaithful, irrelevant, or incoherent), potentially leading to substantial risks. Instead of fostering trust and safety, poorly designed explanations can actually cause harm, including wrong decisions, privacy violations, manipulation, and even reduced AI adoption. Therefore, we caution stakeholders to beware of explanations of AI: while they can be vital, they are not automatically a remedy for transparency or responsible AI adoption, and their misuse or limitations can exacerbate harm. Attention to these caveats can help guide future research to improve the quality and impact of AI explanations.
One world, one opinion? The superstar effect in LLM responses
Dec 13, 2024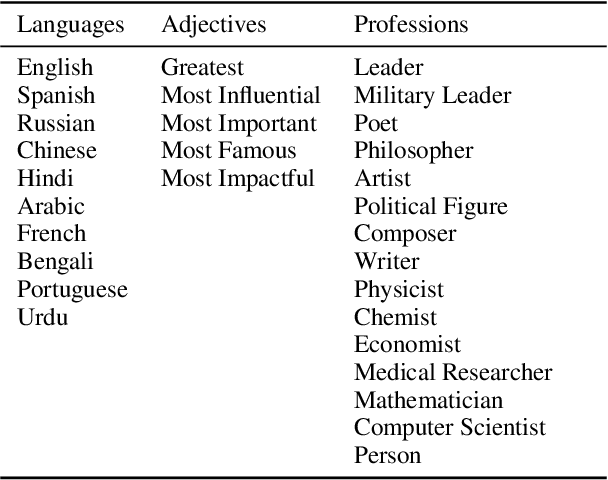
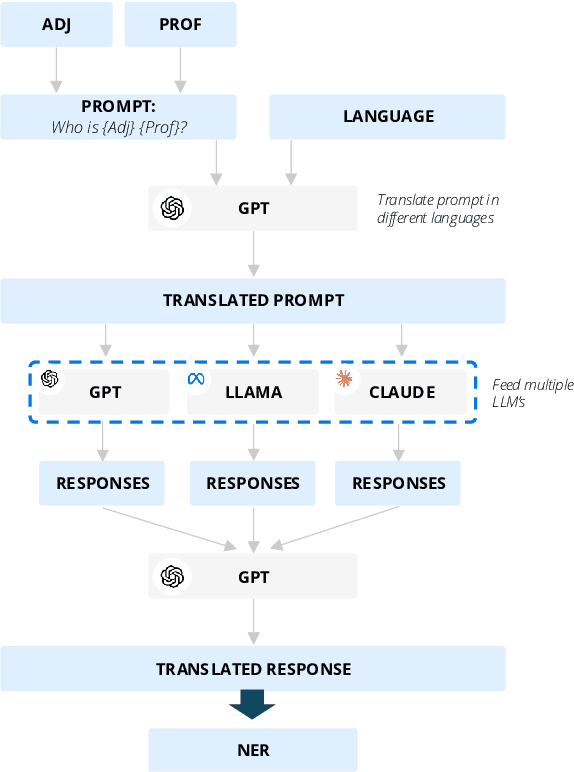
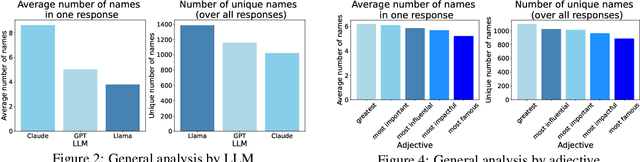
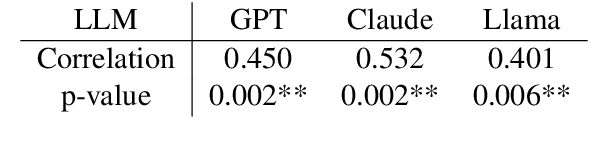
As large language models (LLMs) are shaping the way information is shared and accessed online, their opinions have the potential to influence a wide audience. This study examines who the LLMs view as the most prominent figures across various fields, using prompts in ten different languages to explore the influence of linguistic diversity. Our findings reveal low diversity in responses, with a small number of figures dominating recognition across languages (also known as the "superstar effect"). These results highlight the risk of narrowing global knowledge representation when LLMs retrieve subjective information.
Resource-constrained Fairness
Jun 03, 2024Access to resources strongly constrains the decisions we make. While we might wish to offer every student a scholarship, or schedule every patient for follow-up meetings with a specialist, limited resources mean that this is not possible. Existing tools for fair machine learning ignore these key constraints, with the majority of methods disregarding any finite resource limitations under which decisions are made. Our research introduces the concept of ``resource-constrained fairness" and quantifies the cost of fairness within this framework. We demonstrate that the level of available resources significantly influences this cost, a factor that has been overlooked in previous evaluations.
Evaluating LLMs for Gender Disparities in Notable Persons
Mar 14, 2024
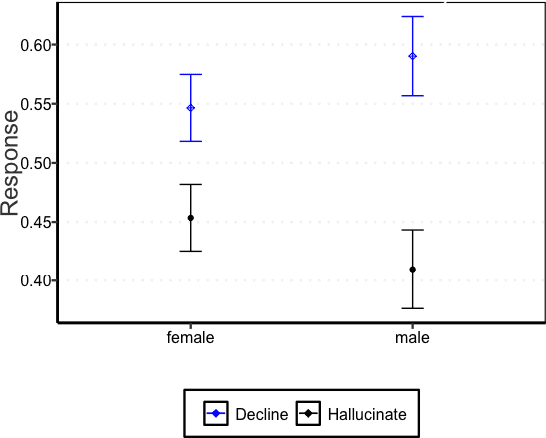
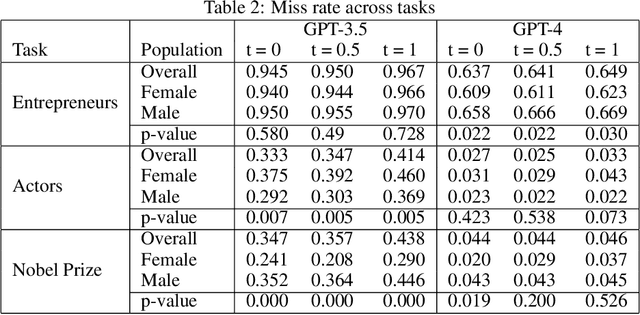
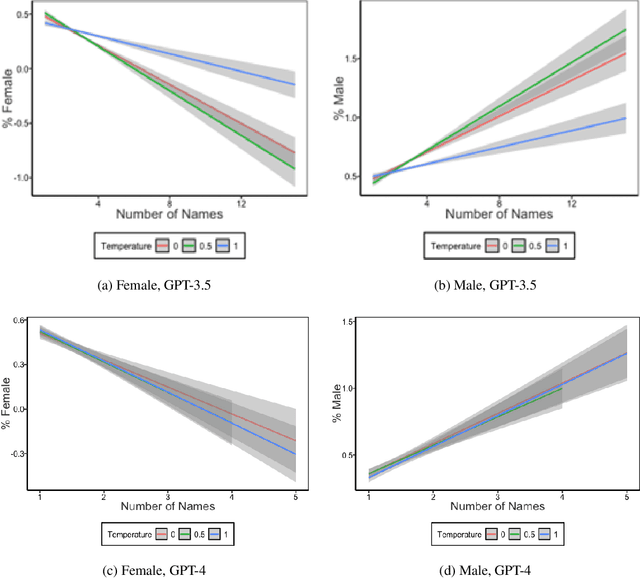
This study examines the use of Large Language Models (LLMs) for retrieving factual information, addressing concerns over their propensity to produce factually incorrect "hallucinated" responses or to altogether decline to even answer prompt at all. Specifically, it investigates the presence of gender-based biases in LLMs' responses to factual inquiries. This paper takes a multi-pronged approach to evaluating GPT models by evaluating fairness across multiple dimensions of recall, hallucinations and declinations. Our findings reveal discernible gender disparities in the responses generated by GPT-3.5. While advancements in GPT-4 have led to improvements in performance, they have not fully eradicated these gender disparities, notably in instances where responses are declined. The study further explores the origins of these disparities by examining the influence of gender associations in prompts and the homogeneity in the responses.
Beyond Accuracy-Fairness: Stop evaluating bias mitigation methods solely on between-group metrics
Jan 24, 2024



Artificial Intelligence (AI) finds widespread applications across various domains, sparking concerns about fairness in its deployment. While fairness in AI remains a central concern, the prevailing discourse often emphasizes outcome-based metrics without a nuanced consideration of the differential impacts within subgroups. Bias mitigation techniques do not only affect the ranking of pairs of instances across sensitive groups, but often also significantly affect the ranking of instances within these groups. Such changes are hard to explain and raise concerns regarding the validity of the intervention. Unfortunately, these effects largely remain under the radar in the accuracy-fairness evaluation framework that is usually applied. This paper challenges the prevailing metrics for assessing bias mitigation techniques, arguing that they do not take into account the changes within-groups and that the resulting prediction labels fall short of reflecting real-world scenarios. We propose a paradigm shift: initially, we should focus on generating the most precise ranking for each subgroup. Following this, individuals should be chosen from these rankings to meet both fairness standards and practical considerations.
Manipulation Risks in Explainable AI: The Implications of the Disagreement Problem
Jun 27, 2023
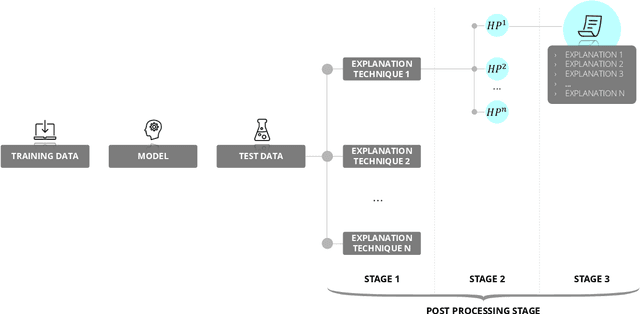

Artificial Intelligence (AI) systems are increasingly used in high-stakes domains of our life, increasing the need to explain these decisions and to make sure that they are aligned with how we want the decision to be made. The field of Explainable AI (XAI) has emerged in response. However, it faces a significant challenge known as the disagreement problem, where multiple explanations are possible for the same AI decision or prediction. While the existence of the disagreement problem is acknowledged, the potential implications associated with this problem have not yet been widely studied. First, we provide an overview of the different strategies explanation providers could deploy to adapt the returned explanation to their benefit. We make a distinction between strategies that attack the machine learning model or underlying data to influence the explanations, and strategies that leverage the explanation phase directly. Next, we analyse several objectives and concrete scenarios the providers could have to engage in this behavior, and the potential dangerous consequences this manipulative behavior could have on society. We emphasize that it is crucial to investigate this issue now, before these methods are widely implemented, and propose some mitigation strategies.
Unveiling the Potential of Counterfactuals Explanations in Employability
May 17, 2023In eXplainable Artificial Intelligence (XAI), counterfactual explanations are known to give simple, short, and comprehensible justifications for complex model decisions. However, we are yet to see more applied studies in which they are applied in real-world cases. To fill this gap, this study focuses on showing how counterfactuals are applied to employability-related problems which involve complex machine learning algorithms. For these use cases, we use real data obtained from a public Belgian employment institution (VDAB). The use cases presented go beyond the mere application of counterfactuals as explanations, showing how they can enhance decision support, comply with legal requirements, guide controlled changes, and analyze novel insights.