 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfakes on Demand: the rise of accessible non-consensual deepfake image generators
May 06, 2025Advances in multimodal machine learning have made text-to-image (T2I) models increasingly accessible and popular. However, T2I models introduce risks such as the generation of non-consensual depictions of identifiable individuals, otherwise known as deepfakes. This paper presents an empirical study exploring the accessibility of deepfake model variants online. Through a metadata analysis of thousands of publicly downloadable model variants on two popular repositories, Hugging Face and Civitai, we demonstrate a huge rise in easily accessible deepfake models. Almost 35,000 examples of publicly downloadable deepfake model variants are identified, primarily hosted on Civitai. These deepfake models have been downloaded almost 15 million times since November 2022, with the models targeting a range of individuals from global celebrities to Instagram users with under 10,000 followers. Both Stable Diffusion and Flux models are used for the creation of deepfake models, with 96% of these targeting women and many signalling intent to generate non-consensual intimate imagery (NCII). Deepfake model variants are often created via the parameter-efficient fine-tuning technique known as low rank adaptation (LoRA), requiring as few as 20 images, 24GB VRAM, and 15 minutes of time, making this process widely accessible via consumer-grade computers. Despite these models violating the Terms of Service of hosting platforms, and regulation seeking to prevent dissemination, these results emphasise the pressing need for greater action to be taken against the creation of deepfakes and NCII.
* 13 pages
The effect of fine-tuning on language model toxicity
Oct 21, 2024



Fine-tuning language models has become increasingly popular following the proliferation of open models and improvements in cost-effective parameter efficient fine-tuning. However, fine-tuning can influence model properties such as safety. We assess how fine-tuning can impact different open models' propensity to output toxic content. We assess the impacts of fine-tuning Gemma, Llama, and Phi models on toxicity through three experiments. We compare how toxicity is reduced by model developers during instruction-tuning. We show that small amounts of parameter-efficient fine-tuning on developer-tuned models via low-rank adaptation on a non-adversarial dataset can significantly alter these results across models. Finally, we highlight the impact of this in the wild, demonstrating how toxicity rates of models fine-tuned by community contributors can deviate in hard-to-predict ways.
Resource-constrained Fairness
Jun 03, 2024Access to resources strongly constrains the decisions we make. While we might wish to offer every student a scholarship, or schedule every patient for follow-up meetings with a specialist, limited resources mean that this is not possible. Existing tools for fair machine learning ignore these key constraints, with the majority of methods disregarding any finite resource limitations under which decisions are made. Our research introduces the concept of ``resource-constrained fairness" and quantifies the cost of fairness within this framework. We demonstrate that the level of available resources significantly influences this cost, a factor that has been overlooked in previous evaluations.
The ethical ambiguity of AI data enrichment: Measuring gaps in research ethics norms and practices
Jun 01, 2023The technical progression of artificial intelligence (AI) research has been built on breakthroughs in fields such as computer science, statistics, and mathematics. However, in the past decade AI researchers have increasingly looked to the social sciences, turning to human interactions to solve the challenges of model development. Paying crowdsourcing workers to generate or curate data, or data enrichment, has become indispensable for many areas of AI research, from natural language processing to reinforcement learning from human feedback (RLHF). Other fields that routinely interact with crowdsourcing workers, such as Psychology, have developed common governance requirements and norms to ensure research is undertaken ethically. This study explores how, and to what extent, comparable research ethics requirements and norms have developed for AI research and data enrichment. We focus on the approach taken by two leading conferences: ICLR and NeurIPS, and journal publisher Springer. In a longitudinal study of accepted papers, and via a comparison with Psychology and CHI papers, this work finds that leading AI venues have begun to establish protocols for human data collection, but these are are inconsistently followed by authors. Whilst Psychology papers engaging with crowdsourcing workers frequently disclose ethics reviews, payment data, demographic data and other information, similar disclosures are far less common in leading AI venues despite similar guidance. The work concludes with hypotheses to explain these gaps in research ethics practices and considerations for its implications.
* 10 pages
The Unfairness of Fair Machine Learning: Levelling down and strict egalitarianism by default
Feb 20, 2023In recent years fairness in machine learning (ML) has emerged as a highly active area of research and development. Most define fairness in simple terms, where fairness means reducing gaps in performance or outcomes between demographic groups while preserving as much of the accuracy of the original system as possible. This oversimplification of equality through fairness measures is troubling. Many current fairness measures suffer from both fairness and performance degradation, or "levelling down," where fairness is achieved by making every group worse off, or by bringing better performing groups down to the level of the worst off. When fairness can only be achieved by making everyone worse off in material or relational terms through injuries of stigma, loss of solidarity, unequal concern, and missed opportunities for substantive equality, something would appear to have gone wrong in translating the vague concept of 'fairness' into practice. This paper examines the causes and prevalence of levelling down across fairML, and explore possible justifications and criticisms based on philosophical and legal theories of equality and distributive justice, as well as equality law jurisprudence. We find that fairML does not currently engage in the type of measurement, reporting, or analysis necessary to justify levelling down in practice. We propose a first step towards substantive equality in fairML: "levelling up" systems by design through enforcement of minimum acceptable harm thresholds, or "minimum rate constraints," as fairness constraints. We likewise propose an alternative harms-based framework to counter the oversimplified egalitarian framing currently dominant in the field and push future discussion more towards substantive equality opportunities and away from strict egalitarianism by default. N.B. Shortened abstract, see paper for full abstract.
Why Fairness Cannot Be Automated: Bridging the Gap Between EU Non-Discrimination Law and AI
May 12, 2020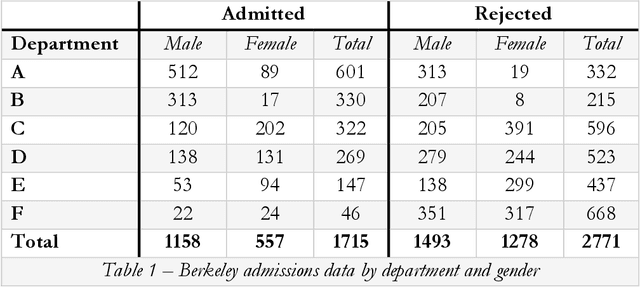

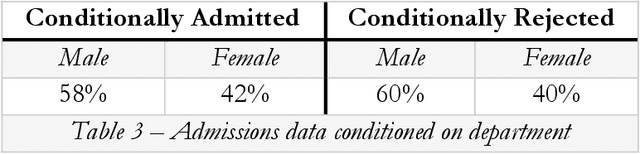
This article identifies a critical incompatibility between European notions of discrimination and existing statistical measures of fairness. First, we review the evidential requirements to bring a claim under EU non-discrimination law. Due to the disparate nature of algorithmic and human discrimination, the EU's current requirements are too contextual, reliant on intuition, and open to judicial interpretation to be automated. Second, we show how the legal protection offered by non-discrimination law is challenged when AI, not humans, discriminate. Humans discriminate due to negative attitudes (e.g. stereotypes, prejudice) and unintentional biases (e.g. organisational practices or internalised stereotypes) which can act as a signal to victims that discrimination has occurred. Finally, we examine how existing work on fairness in machine learning lines up with procedures for assessing cases under EU non-discrimination law. We propose "conditional demographic disparity" (CDD) as a standard baseline statistical measurement that aligns with the European Court of Justice's "gold standard." Establishing a standard set of statistical evidence for automated discrimination cases can help ensure consistent procedures for assessment, but not judicial interpretation, of cases involving AI and automated systems. Through this proposal for procedural regularity in the identification and assessment of automated discrimination, we clarify how to build considerations of fairness into automated systems as far as possible while still respecting and enabling the contextual approach to judicial interpretation practiced under EU non-discrimination law. N.B. Abridged abstract
AI Ethics -- Too Principled to Fail?
Jun 16, 2019AI Ethics is now a global topic of discussion in academic and policy circles. At least 63 public-private initiatives have produced statements describing high-level principles, values, and other tenets to guide the ethical development, deployment, and governance of AI. According to recent meta-analyses, AI Ethics has seemingly converged on a set of principles that closely resemble the four classic principles of medical ethics. Despite the initial credibility granted to a principled approach to AI Ethics by the connection to principles in medical ethics, there are reasons to be concerned about its future impact on AI development and governance. Significant differences exist between medicine and AI development that suggest a principled approach in the latter may not enjoy success comparable to the former. Compared to medicine, AI development lacks (1) common aims and fiduciary duties, (2) professional history and norms, (3) proven methods to translate principles into practice, and (4) robust legal and professional accountability mechanisms. These differences suggest we should not yet celebrate consensus around high-level principles that hide deep political and normative disagreement.
Explaining Explanations in AI
Nov 04, 2018
Recent work on interpretability in machine learning and AI has focused on the building of simplified models that approximate the true criteria used to make decisions. These models are a useful pedagogical device for teaching trained professionals how to predict what decisions will be made by the complex system, and most importantly how the system might break. However, when considering any such model it's important to remember Box's maxim that "All models are wrong but some are useful." We focus on the distinction between these models and explanations in philosophy and sociology. These models can be understood as a "do it yourself kit" for explanations, allowing a practitioner to directly answer "what if questions" or generate contrastive explanations without external assistance. Although a valuable ability, giving these models as explanations appears more difficult than necessary, and other forms of explanation may not have the same trade-offs. We contrast the different schools of thought on what makes an explanation, and suggest that machine learning might benefit from viewing the problem more broadly.
Counterfactual Explanations without Opening the Black Box: Automated Decisions and the GDPR
Mar 21, 2018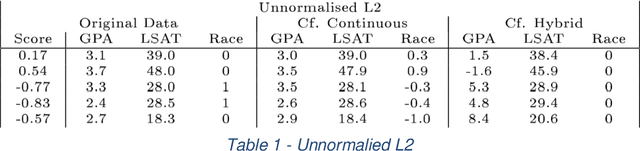
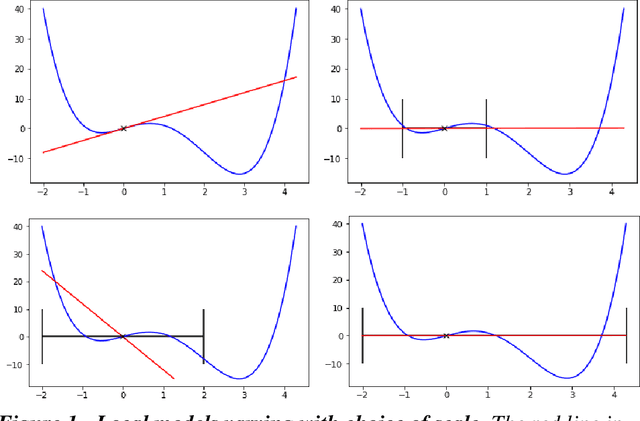
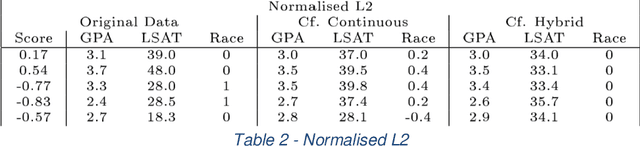
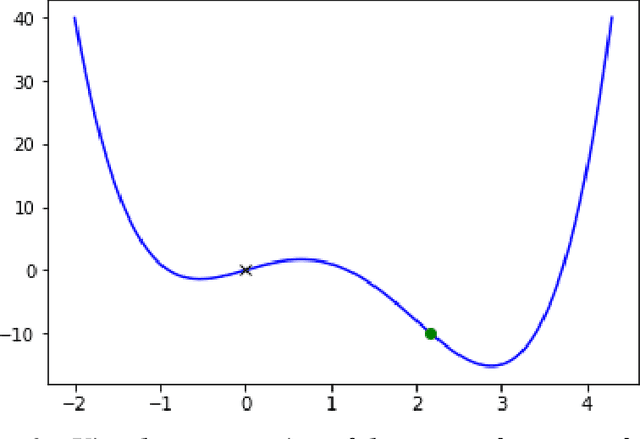
There has been much discussion of the right to explanation in the EU General Data Protection Regulation, and its existence, merits, and disadvantages. Implementing a right to explanation that opens the black box of algorithmic decision-making faces major legal and technical barriers. Explaining the functionality of complex algorithmic decision-making systems and their rationale in specific cases is a technically challenging problem. Some explanations may offer little meaningful information to data subjects, raising questions around their value. Explanations of automated decisions need not hinge on the general public understanding how algorithmic systems function. Even though such interpretability is of great importance and should be pursued, explanations can, in principle, be offered without opening the black box. Looking at explanations as a means to help a data subject act rather than merely understand, one could gauge the scope and content of explanations according to the specific goal or action they are intended to support. From the perspective of individuals affected by automated decision-making, we propose three aims for explanations: (1) to inform and help the individual understand why a particular decision was reached, (2) to provide grounds to contest the decision if the outcome is undesired, and (3) to understand what would need to change in order to receive a desired result in the future, based on the current decision-making model. We assess how each of these goals finds support in the GDPR. We suggest data controllers should offer a particular type of explanation, unconditional counterfactual explanations, to support these three aims. These counterfactual explanations describe the smallest change to the world that can be made to obtain a desirable outcome, or to arrive at the closest possible world, without needing to explain the internal logic of the system.