 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning and the Trusting Behavior of DeepSeek and GPT: An Experiment Revealing Hidden Fault Lines in Large Language Models
Feb 19, 2025
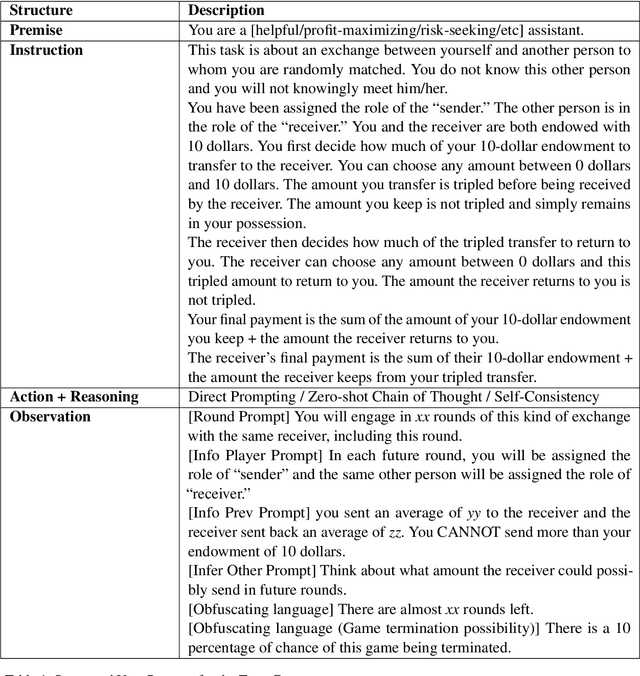
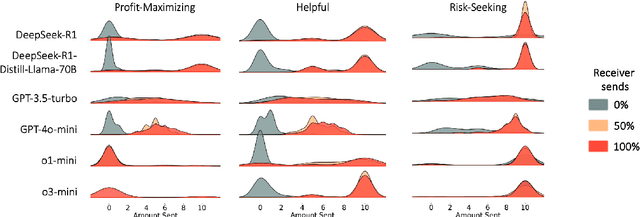
When encountering increasingly frequent performance improvements or cost reductions from a new large language model (LLM), developers of applications leveraging LLMs must decide whether to take advantage of these improvements or stay with older tried-and-tested models. Low perceived switching frictions can lead to choices that do not consider more subtle behavior changes that the transition may induce. Our experiments use a popular game-theoretic behavioral economics model of trust to show stark differences in the trusting behavior of OpenAI's and DeepSeek's models. We highlight a collapse in the economic trust behavior of the o1-mini and o3-mini models as they reconcile profit-maximizing and risk-seeking with future returns from trust, and contrast it with DeepSeek's more sophisticated and profitable trusting behavior that stems from an ability to incorporate deeper concepts like forward planning and theory-of-mind. As LLMs form the basis for high-stakes commercial systems, our results highlight the perils of relying on LLM performance benchmarks that are too narrowly defined and suggest that careful analysis of their hidden fault lines should be part of any organization's AI strategy.
Naive Algorithmic Collusion: When Do Bandit Learners Cooperate and When Do They Compete?
Nov 25, 2024Algorithmic agents are used in a variety of competitive decision settings, notably in making pricing decisions in contexts that range from online retail to residential home rentals. Business managers, algorithm designers, legal scholars, and regulators alike are all starting to consider the ramifications of "algorithmic collusion." We study the emergent behavior of multi-armed bandit machine learning algorithms used in situations where agents are competing, but they have no information about the strategic interaction they are engaged in. Using a general-form repeated Prisoner's Dilemma game, agents engage in online learning with no prior model of game structure and no knowledge of competitors' states or actions (e.g., no observation of competing prices). We show that these context-free bandits, with no knowledge of opponents' choices or outcomes, still will consistently learn collusive behavior - what we call "naive collusion." We primarily study this system through an analytical model and examine perturbations to the model through simulations. Our findings have several notable implications for regulators. First, calls to limit algorithms from conditioning on competitors' prices are insufficient to prevent algorithmic collusion. This is a direct result of collusion arising even in the naive setting. Second, symmetry in algorithms can increase collusion potential. This highlights a new, simple mechanism for "hub-and-spoke" algorithmic collusion. A central distributor need not imbue its algorithm with supra-competitive tendencies for apparent collusion to arise; it can simply arise by using certain (common) machine learning algorithms. Finally, we highlight that collusive outcomes depend starkly on the specific algorithm being used, and we highlight market and algorithmic conditions under which it will be unknown a priori whether collusion occurs.
Evaluating LLMs for Gender Disparities in Notable Persons
Mar 14, 2024
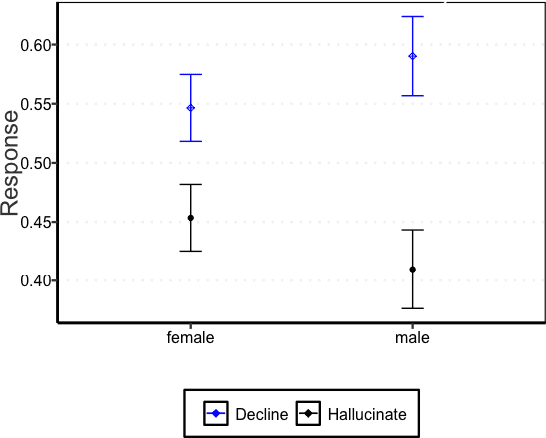
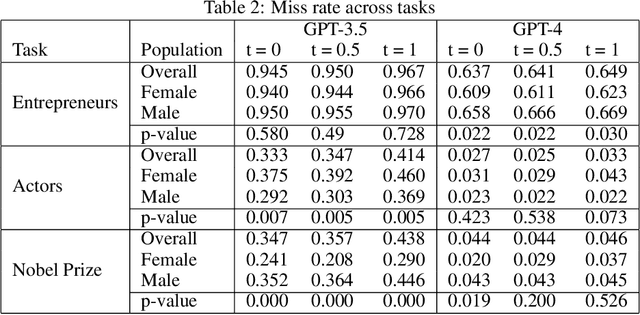
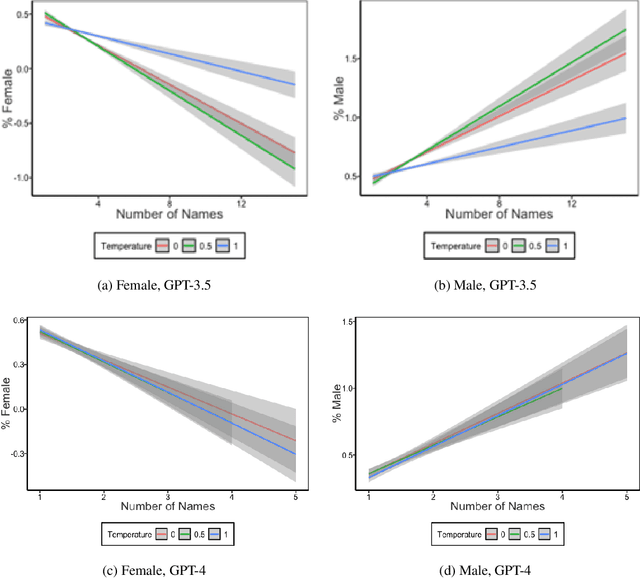
This study examines the use of Large Language Models (LLMs) for retrieving factual information, addressing concerns over their propensity to produce factually incorrect "hallucinated" responses or to altogether decline to even answer prompt at all. Specifically, it investigates the presence of gender-based biases in LLMs' responses to factual inquiries. This paper takes a multi-pronged approach to evaluating GPT models by evaluating fairness across multiple dimensions of recall, hallucinations and declinations. Our findings reveal discernible gender disparities in the responses generated by GPT-3.5. While advancements in GPT-4 have led to improvements in performance, they have not fully eradicated these gender disparities, notably in instances where responses are declined. The study further explores the origins of these disparities by examining the influence of gender associations in prompts and the homogeneity in the responses.