 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom What Ifs to Insights: Counterfactuals in Causal Inference vs. Explainable AI
May 19, 2025Counterfactuals play a pivotal role in the two distinct data science fields of causal inference (CI) and explainable artificial intelligence (XAI). While the core idea behind counterfactuals remains the same in both fields--the examination of what would have happened under different circumstances--there are key differences in how they are used and interpreted. We introduce a formal definition that encompasses the multi-faceted concept of the counterfactual in CI and XAI. We then discuss how counterfactuals are used, evaluated, generated, and operationalized in CI vs. XAI, highlighting conceptual and practical differences. By comparing and contrasting the two, we hope to identify opportunities for cross-fertilization across CI and XAI.
Beware of "Explanations" of AI
Apr 09, 2025Understanding the decisions made and actions taken by increasingly complex AI system remains a key challenge. This has led to an expanding field of research in explainable artificial intelligence (XAI), highlighting the potential of explanations to enhance trust, support adoption, and meet regulatory standards. However, the question of what constitutes a "good" explanation is dependent on the goals, stakeholders, and context. At a high level, psychological insights such as the concept of mental model alignment can offer guidance, but success in practice is challenging due to social and technical factors. As a result of this ill-defined nature of the problem, explanations can be of poor quality (e.g. unfaithful, irrelevant, or incoherent), potentially leading to substantial risks. Instead of fostering trust and safety, poorly designed explanations can actually cause harm, including wrong decisions, privacy violations, manipulation, and even reduced AI adoption. Therefore, we caution stakeholders to beware of explanations of AI: while they can be vital, they are not automatically a remedy for transparency or responsible AI adoption, and their misuse or limitations can exacerbate harm. Attention to these caveats can help guide future research to improve the quality and impact of AI explanations.
Atomist or Holist? A Diagnosis and Vision for More Productive Interdisciplinary AI Ethics Dialogue
Sep 01, 2022
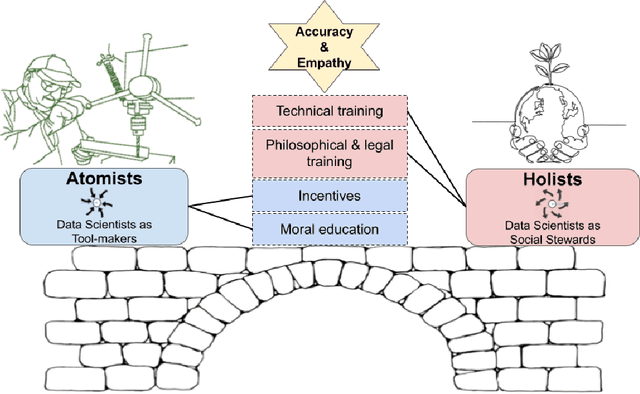

In response to growing recognition of the social, legal, and ethical impacts of new AI-based technologies, major AI and ML conferences and journals now encourage or require submitted papers to include ethics impact statements and undergo ethics reviews. This move has sparked heated debate concerning the role of ethics in AI and data science research, at times devolving into counter-productive name-calling and threats of "cancellation." We diagnose this deep ideological conflict as one between atomists and holists. Among other things, atomists espouse the idea that facts are and should be kept separate from values, while holists believe facts and values are and should be inextricable from one another. With the goals of encouraging civil discourse across disciplines and reducing disciplinary polarization, we draw on a variety of historical sources ranging from philosophy and law, to social theory and humanistic psychology, to describe each ideology's beliefs and assumptions. Finally, we call on atomists and holists within the data science community to exhibit greater empathy during ethical disagreements and propose four targeted strategies to ensure data science research benefits society.
"Improving" prediction of human behavior using behavior modification
Aug 26, 2020



The fields of statistics and machine learning design algorithms, models, and approaches to improve prediction. Larger and richer behavioral data increase predictive power, as evident from recent advances in behavioral prediction technology. Large internet platforms that collect behavioral big data predict user behavior for internal purposes and for third parties (advertisers, insurers, security forces, political consulting firms) who utilize the predictions for personalization, targeting and other decision-making. While standard data collection and modeling efforts are directed at improving predicted values, internet platforms can minimize prediction error by "pushing" users' actions towards their predicted values using behavior modification techniques. The better the platform can make users conform to their predicted outcomes, the more it can boast its predictive accuracy and ability to induce behavior change. Hence, platforms are strongly incentivized to "make predictions true". This strategy is absent from the ML and statistics literature. Investigating its properties requires incorporating causal notation into the correlation-based predictive environment---an integration currently missing. To tackle this void, we integrate Pearl's causal do(.) operator into the predictive framework. We then decompose the expected prediction error given behavior modification, and identify the components impacting predictive power. Our derivation elucidates the implications of such behavior modification to data scientists, platforms, their clients, and the humans whose behavior is manipulated. Behavior modification can make users' behavior more predictable and even more homogeneous; yet this apparent predictability might not generalize when clients use predictions in practice. Outcomes pushed towards their predictions can be at odds with clients' intentions, and harmful to manipulated users.
How Personal is Machine Learning Personalization?
Dec 24, 2019

Though used extensively, the concept and process of machine learning (ML) personalization have generally received little attention from academics, practitioners, and the general public. We describe the ML approach as relying on the metaphor of the person as a feature vector and contrast this with humanistic views of the person. In light of the recent calls by the IEEE to consider the effects of ML on human well-being, we ask whether ML personalization can be reconciled with these humanistic views of the person, which highlight the importance of moral and social identity. As human behavior increasingly becomes digitized, analyzed, and predicted, to what extent do our subsequent decisions about what to choose, buy, or do, made both by us and others, reflect who we are as persons? This paper first explicates the term personalization by considering ML personalization and highlights its relation to humanistic conceptions of the person, then proposes several dimensions for evaluating the degree of personalization of ML personalized scores. By doing so, we hope to contribute to current debate on the issues of algorithmic bias, transparency, and fairness in machine learning.
Lift Up and Act! Classifier Performance in Resource-Constrained Applications
Jun 20, 2019



Classification tasks are common across many fields and applications where the decision maker's action is limited by resource constraints. In direct marketing only a subset of customers is contacted; scarce human resources limit the number of interviews to the most promising job candidates; limited donated organs are prioritized to those with best fit. In such scenarios, performance measures such as the classification matrix, ROC analysis, and even ranking metrics such as AUC measures outcomes different from the action of interest. At the same time, gains and lift that do measure the relevant outcome are rarely used by machine learners. In this paper we define resource-constrained classifier performance as a task distinguished from classification and ranking. We explain how gains and lift can lead to different algorithm choices and discuss the effect of class distribution.