 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Definition and Detection of Cherry-Picking in Counterfactual Explanations
Jan 08, 2026Counterfactual explanations are widely used to communicate how inputs must change for a model to alter its prediction. For a single instance, many valid counterfactuals can exist, which leaves open the possibility for an explanation provider to cherry-pick explanations that better suit a narrative of their choice, highlighting favourable behaviour and withholding examples that reveal problematic behaviour. We formally define cherry-picking for counterfactual explanations in terms of an admissible explanation space, specified by the generation procedure, and a utility function. We then study to what extent an external auditor can detect such manipulation. Considering three levels of access to the explanation process: full procedural access, partial procedural access, and explanation-only access, we show that detection is extremely limited in practice. Even with full procedural access, cherry-picked explanations can remain difficult to distinguish from non cherry-picked explanations, because the multiplicity of valid counterfactuals and flexibility in the explanation specification provide sufficient degrees of freedom to mask deliberate selection. Empirically, we demonstrate that this variability often exceeds the effect of cherry-picking on standard counterfactual quality metrics such as proximity, plausibility, and sparsity, making cherry-picked explanations statistically indistinguishable from baseline explanations. We argue that safeguards should therefore prioritise reproducibility, standardisation, and procedural constraints over post-hoc detection, and we provide recommendations for algorithm developers, explanation providers, and auditors.
Beware of "Explanations" of AI
Apr 09, 2025Understanding the decisions made and actions taken by increasingly complex AI system remains a key challenge. This has led to an expanding field of research in explainable artificial intelligence (XAI), highlighting the potential of explanations to enhance trust, support adoption, and meet regulatory standards. However, the question of what constitutes a "good" explanation is dependent on the goals, stakeholders, and context. At a high level, psychological insights such as the concept of mental model alignment can offer guidance, but success in practice is challenging due to social and technical factors. As a result of this ill-defined nature of the problem, explanations can be of poor quality (e.g. unfaithful, irrelevant, or incoherent), potentially leading to substantial risks. Instead of fostering trust and safety, poorly designed explanations can actually cause harm, including wrong decisions, privacy violations, manipulation, and even reduced AI adoption. Therefore, we caution stakeholders to beware of explanations of AI: while they can be vital, they are not automatically a remedy for transparency or responsible AI adoption, and their misuse or limitations can exacerbate harm. Attention to these caveats can help guide future research to improve the quality and impact of AI explanations.
Evaluation and Facilitation of Online Discussions in the LLM Era: A Survey
Mar 03, 2025
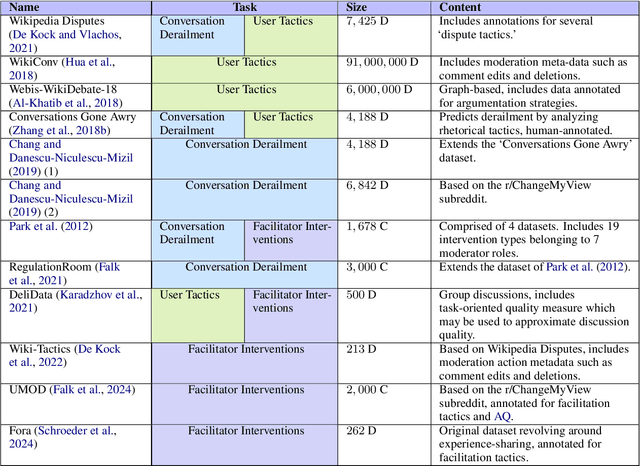


We present a survey of methods for assessing and enhancing the quality of online discussions, focusing on the potential of Large Language Models (LLMs). While online discourses aim, at least in theory, to foster mutual understanding, they often devolve into harmful exchanges, such as hate speech, threatening social cohesion and democratic values. Recent advancements in LLMs enable facilitation agents that not only moderate content, but also actively improve the quality of interactions. Our survey synthesizes ideas from Natural Language Processing (NLP) and Social Sciences to provide (a) a new taxonomy on discussion quality evaluation, (b) an overview of intervention and facilitation strategies, along with a new taxonomy on conversation facilitation datasets, (c) an LLM-oriented roadmap of good practices and future research directions, from technological and societal perspectives.
Manipulation Risks in Explainable AI: The Implications of the Disagreement Problem
Jun 27, 2023

Artificial Intelligence (AI) systems are increasingly used in high-stakes domains of our life, increasing the need to explain these decisions and to make sure that they are aligned with how we want the decision to be made. The field of Explainable AI (XAI) has emerged in response. However, it faces a significant challenge known as the disagreement problem, where multiple explanations are possible for the same AI decision or prediction. While the existence of the disagreement problem is acknowledged, the potential implications associated with this problem have not yet been widely studied. First, we provide an overview of the different strategies explanation providers could deploy to adapt the returned explanation to their benefit. We make a distinction between strategies that attack the machine learning model or underlying data to influence the explanations, and strategies that leverage the explanation phase directly. Next, we analyse several objectives and concrete scenarios the providers could have to engage in this behavior, and the potential dangerous consequences this manipulative behavior could have on society. We emphasize that it is crucial to investigate this issue now, before these methods are widely implemented, and propose some mitigation strategies.
Metafeatures-based Rule-Extraction for Classifiers on Behavioral and Textual Data
Mar 10, 2020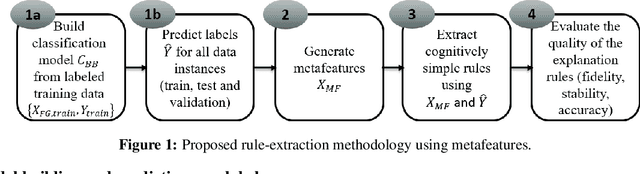
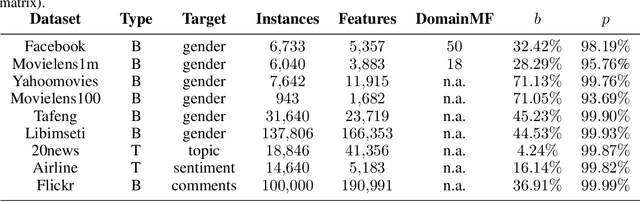

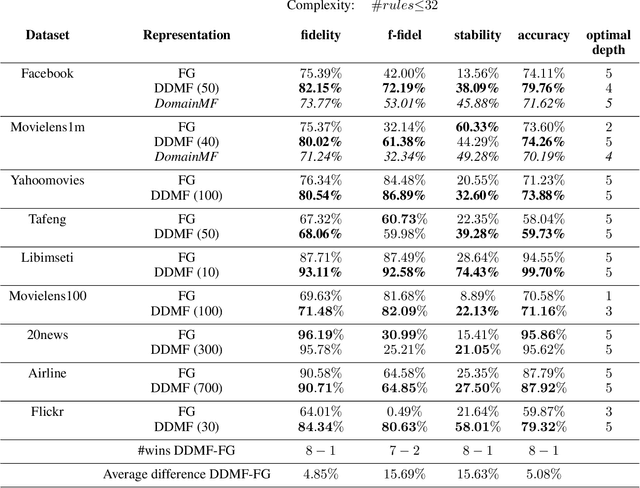
Machine learning using behavioral and text data can result in highly accurate prediction models, but these are often very difficult to interpret. Linear models require investigating thousands of coefficients, while the opaqueness of nonlinear models makes things even worse. Rule-extraction techniques have been proposed to combine the desired predictive behaviour of complex "black-box" models with explainability. However, rule-extraction in the context of ultra-high-dimensional and sparse data can be challenging, and has thus far received scant attention. Because of the sparsity and massive dimensionality, rule-extraction might fail in their primary explainability goal as the black-box model may need to be replaced by many rules, leaving the user again with an incomprehensible model. To address this problem, we develop and test a rule-extraction methodology based on higher-level, less-sparse "metafeatures". We empirically validate the quality of the rules in terms of fidelity, explanation stability and accuracy over a collection of data sets, and benchmark their performance against rules extracted using the original features. Our analysis points to key trade-offs between explainability, fidelity, accuracy, and stability that Machine Learning researchers and practitioners need to consider. Results indicate that the proposed metafeatures approach leads to better trade-offs between these, and is better able to mimic the black-box model. There is an average decrease of the loss in fidelity, accuracy, and stability from using metafeatures instead of the original fine-grained features by respectively 18.08%, 20.15% and 17.73%, all statistically significant at a 5% significance level. Metafeatures thus improve a key "cost of explainability", which we define as the loss in fidelity when replacing a black-box with an explainable model.
Counterfactual Explanation Algorithms for Behavioral and Textual Data
Dec 04, 2019
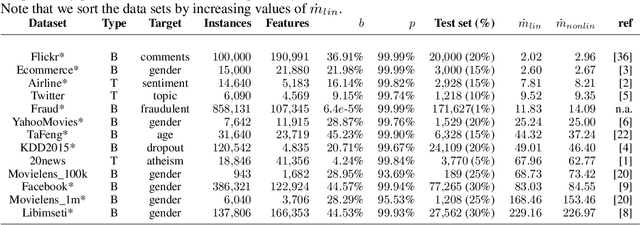

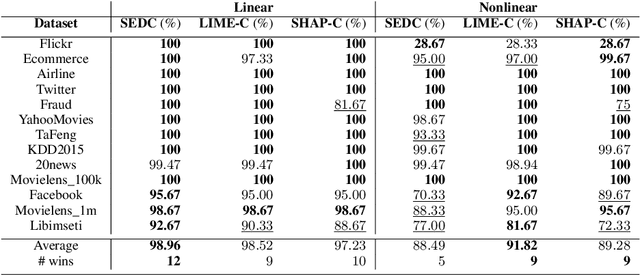
We study the interpretability of predictive systems that use high-dimensonal behavioral and textual data. Examples include predicting product interest based on online browsing data and detecting spam emails or objectionable web content. Recently, counterfactual explanations have been proposed for generating insight into model predictions, which focus on what is relevant to a particular instance. Conducting a complete search to compute counterfactuals is very time-consuming because of the huge dimensionality. To our knowledge, for behavioral and text data, only one model-agnostic heuristic algorithm (SEDC) for finding counterfactual explanations has been proposed in the literature. However, there may be better algorithms for finding counterfactuals quickly. This study aligns the recently proposed Linear Interpretable Model-agnostic Explainer (LIME) and Shapley Additive Explanations (SHAP) with the notion of counterfactual explanations, and empirically benchmarks their effectiveness and efficiency against SEDC using a collection of 13 data sets. Results show that LIME-Counterfactual (LIME-C) and SHAP-Counterfactual (SHAP-C) have low and stable computation times, but mostly, they are less efficient than SEDC. However, for certain instances on certain data sets, SEDC's run time is comparably large. With regard to effectiveness, LIME-C and SHAP-C find reasonable, if not always optimal, counterfactual explanations. SHAP-C, however, seems to have difficulties with highly unbalanced data. Because of its good overall performance, LIME-C seems to be a favorable alternative to SEDC, which failed for some nonlinear models to find counterfactuals because of the particular heuristic search algorithm it uses. A main upshot of this paper is that there is a good deal of room for further research. For example, we propose algorithmic adjustments that are direct upshots of the paper's findings.
Reproducible evaluation of classification methods in Alzheimer's disease: framework and application to MRI and PET data
Aug 20, 2018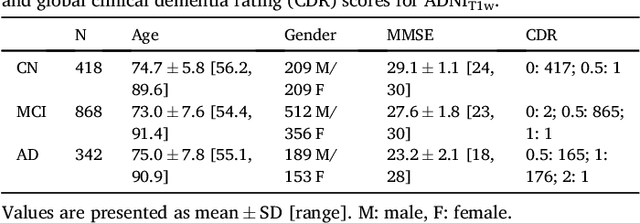
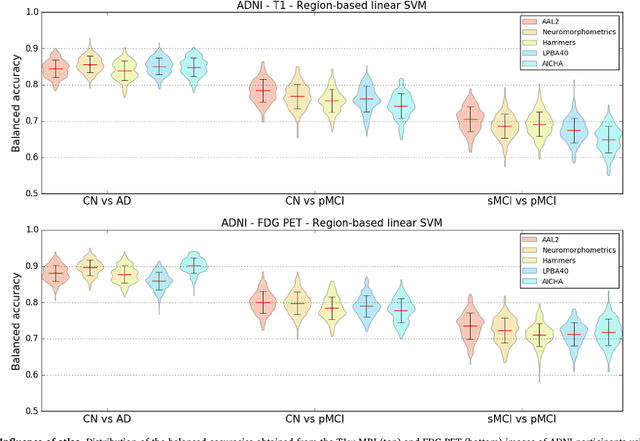
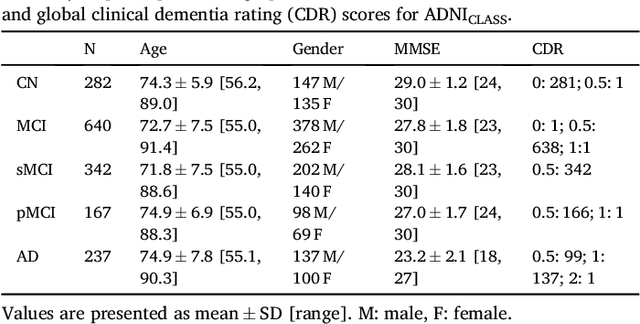
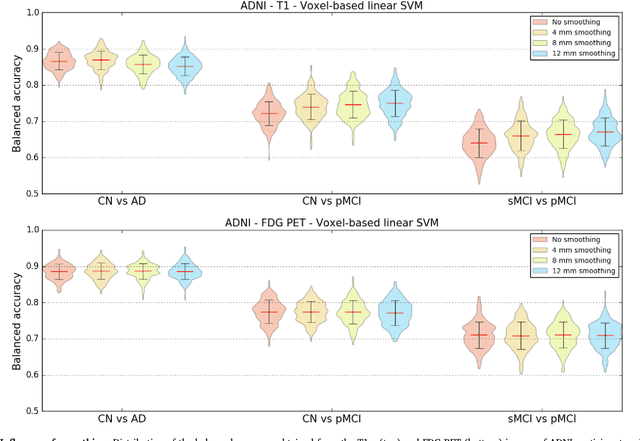
A large number of papers have introduced novel machine learning and feature extraction methods for automatic classification of AD. However, they are difficult to reproduce because key components of the validation are often not readily available. These components include selected participants and input data, image preprocessing and cross-validation procedures. The performance of the different approaches is also difficult to compare objectively. In particular, it is often difficult to assess which part of the method provides a real improvement, if any. We propose a framework for reproducible and objective classification experiments in AD using three publicly available datasets (ADNI, AIBL and OASIS). The framework comprises: i) automatic conversion of the three datasets into BIDS format, ii) a modular set of preprocessing pipelines, feature extraction and classification methods, together with an evaluation framework, that provide a baseline for benchmarking the different components. We demonstrate the use of the framework for a large-scale evaluation on 1960 participants using T1 MRI and FDG PET data. In this evaluation, we assess the influence of different modalities, preprocessing, feature types, classifiers, training set sizes and datasets. Performances were in line with the state-of-the-art. FDG PET outperformed T1 MRI for all classification tasks. No difference in performance was found for the use of different atlases, image smoothing, partial volume correction of FDG PET images, or feature type. Linear SVM and L2-logistic regression resulted in similar performance and both outperformed random forests. The classification performance increased along with the number of subjects used for training. Classifiers trained on ADNI generalized well to AIBL and OASIS. All the code of the framework and the experiments is publicly available at: https://gitlab.icm-institute.org/aramislab/AD-ML.
Yet Another ADNI Machine Learning Paper? Paving The Way Towards Fully-reproducible Research on Classification of Alzheimer's Disease
Sep 21, 2017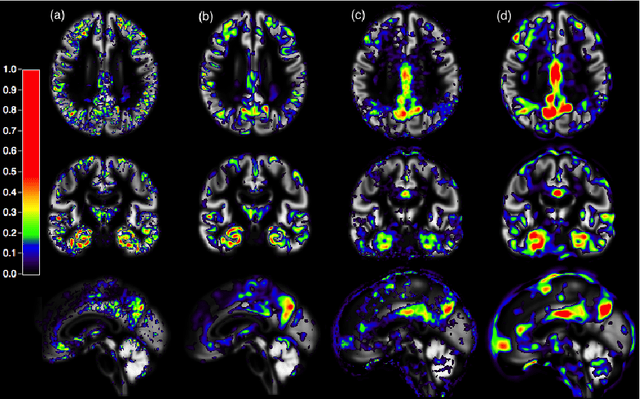
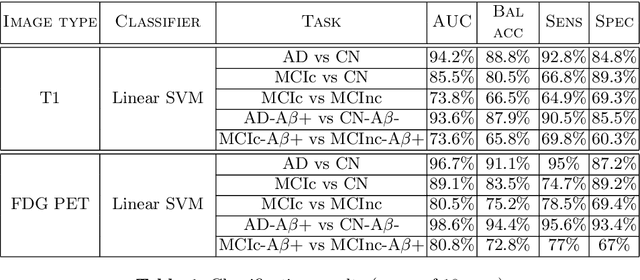
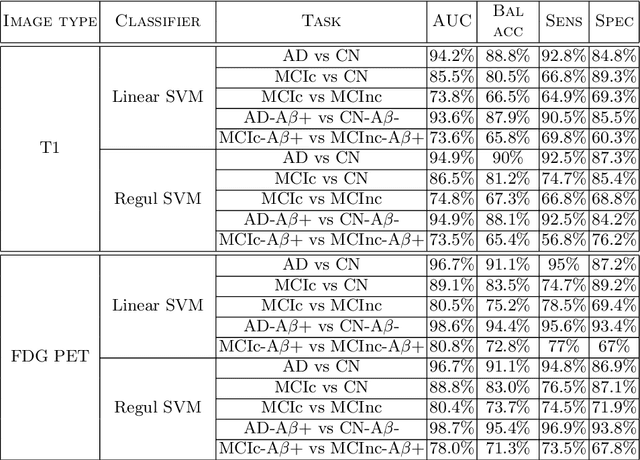
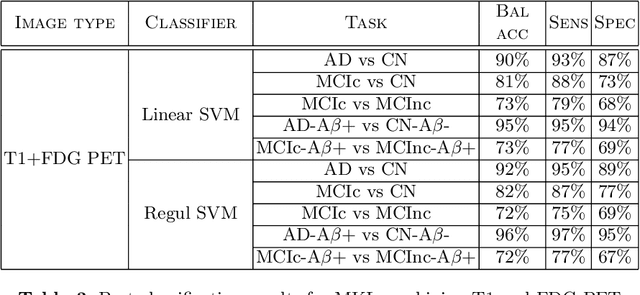
In recent years, the number of papers on Alzheimer's disease classification has increased dramatically, generating interesting methodological ideas on the use machine learning and feature extraction methods. However, practical impact is much more limited and, eventually, one could not tell which of these approaches are the most efficient. While over 90\% of these works make use of ADNI an objective comparison between approaches is impossible due to variations in the subjects included, image pre-processing, performance metrics and cross-validation procedures. In this paper, we propose a framework for reproducible classification experiments using multimodal MRI and PET data from ADNI. The core components are: 1) code to automatically convert the full ADNI database into BIDS format; 2) a modular architecture based on Nipype in order to easily plug-in different classification and feature extraction tools; 3) feature extraction pipelines for MRI and PET data; 4) baseline classification approaches for unimodal and multimodal features. This provides a flexible framework for benchmarking different feature extraction and classification tools in a reproducible manner. We demonstrate its use on all (1519) baseline T1 MR images and all (1102) baseline FDG PET images from ADNI 1, GO and 2 with SPM-based feature extraction pipelines and three different classification techniques (linear SVM, anatomically regularized SVM and multiple kernel learning SVM). The highest accuracies achieved were: 91% for AD vs CN, 83% for MCIc vs CN, 75% for MCIc vs MCInc, 94% for AD-A$\beta$+ vs CN-A$\beta$- and 72% for MCIc-A$\beta$+ vs MCInc-A$\beta$+. The code is publicly available at https://gitlab.icm-institute.org/aramislab/AD-ML (depends on the Clinica software platform, publicly available at http://www.clinica.run).
A Regularization Approach for Prediction of Edges and Node Features in Dynamic Graphs
Mar 24, 2012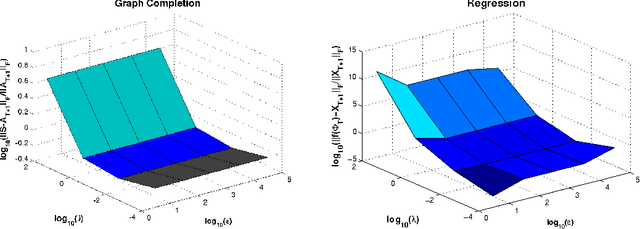
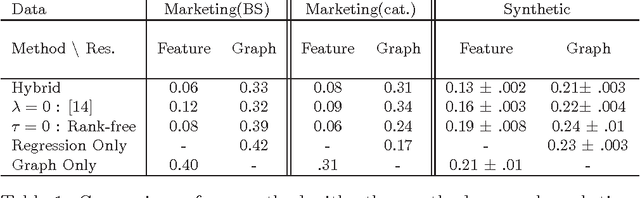
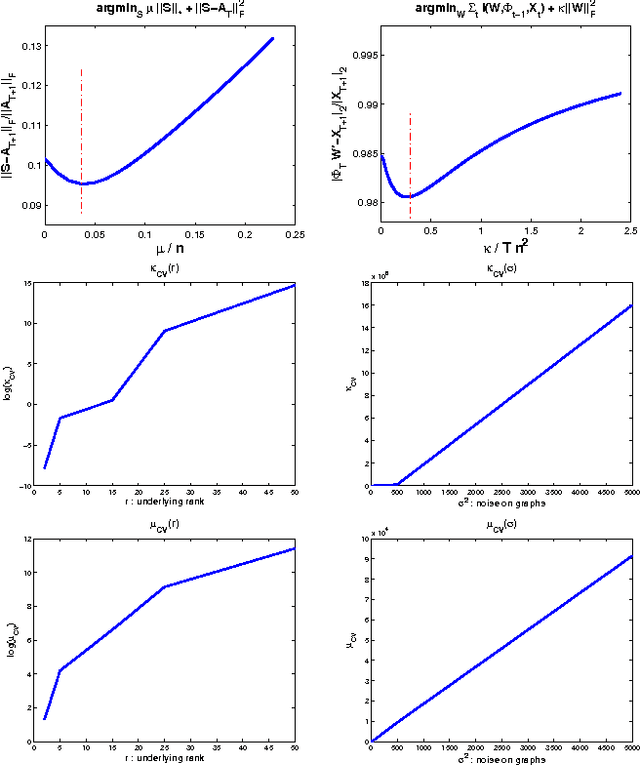
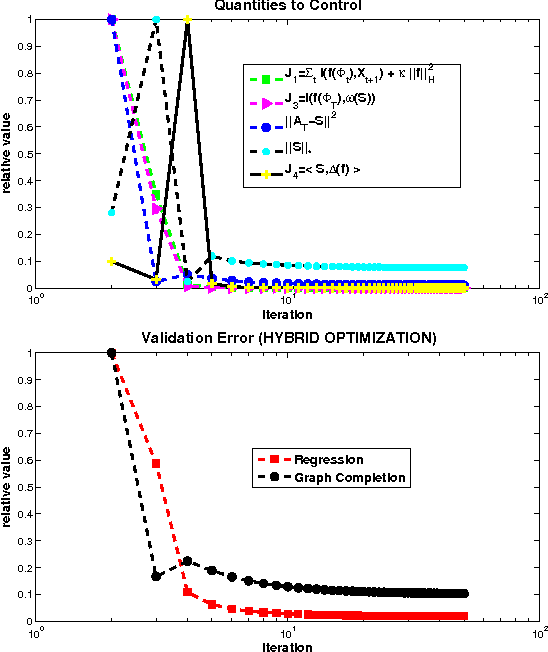
We consider the two problems of predicting links in a dynamic graph sequence and predicting functions defined at each node of the graph. In many applications, the solution of one problem is useful for solving the other. Indeed, if these functions reflect node features, then they are related through the graph structure. In this paper, we formulate a hybrid approach that simultaneously learns the structure of the graph and predicts the values of the node-related functions. Our approach is based on the optimization of a joint regularization objective. We empirically test the benefits of the proposed method with both synthetic and real data. The results indicate that joint regularization improves prediction performance over the graph evolution and the node features.
A New Approach to Collaborative Filtering: Operator Estimation with Spectral Regularization
Dec 19, 2008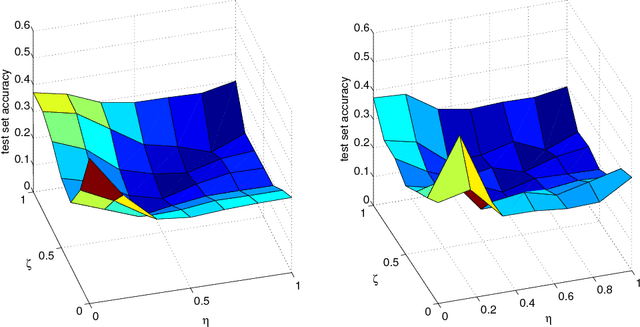
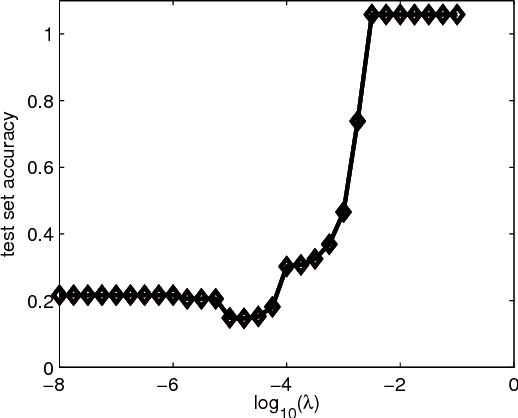
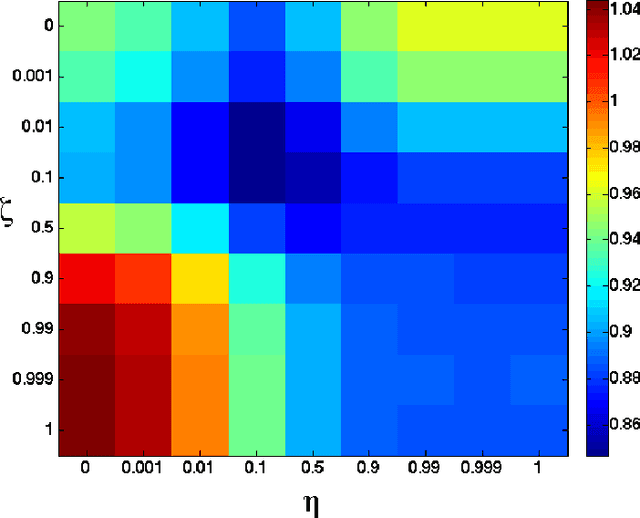
We present a general approach for collaborative filtering (CF) using spectral regularization to learn linear operators from "users" to the "objects" they rate. Recent low-rank type matrix completion approaches to CF are shown to be special cases. However, unlike existing regularization based CF methods, our approach can be used to also incorporate information such as attributes of the users or the objects -- a limitation of existing regularization based CF methods. We then provide novel representer theorems that we use to develop new estimation methods. We provide learning algorithms based on low-rank decompositions, and test them on a standard CF dataset. The experiments indicate the advantages of generalizing the existing regularization based CF methods to incorporate related information about users and objects. Finally, we show that certain multi-task learning methods can be also seen as special cases of our proposed approach.