 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Explanation Algorithms for Behavioral and Textual Data
Paper and Code

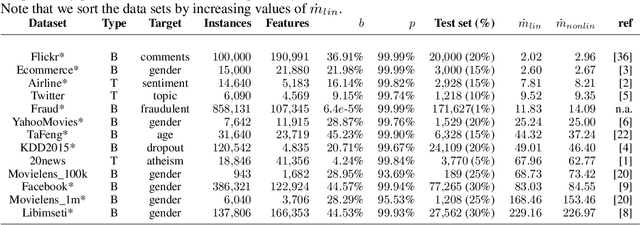

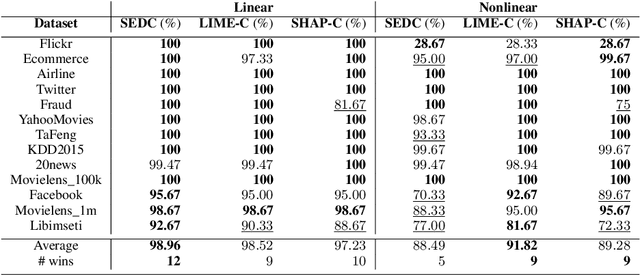
We study the interpretability of predictive systems that use high-dimensonal behavioral and textual data. Examples include predicting product interest based on online browsing data and detecting spam emails or objectionable web content. Recently, counterfactual explanations have been proposed for generating insight into model predictions, which focus on what is relevant to a particular instance. Conducting a complete search to compute counterfactuals is very time-consuming because of the huge dimensionality. To our knowledge, for behavioral and text data, only one model-agnostic heuristic algorithm (SEDC) for finding counterfactual explanations has been proposed in the literature. However, there may be better algorithms for finding counterfactuals quickly. This study aligns the recently proposed Linear Interpretable Model-agnostic Explainer (LIME) and Shapley Additive Explanations (SHAP) with the notion of counterfactual explanations, and empirically benchmarks their effectiveness and efficiency against SEDC using a collection of 13 data sets. Results show that LIME-Counterfactual (LIME-C) and SHAP-Counterfactual (SHAP-C) have low and stable computation times, but mostly, they are less efficient than SEDC. However, for certain instances on certain data sets, SEDC's run time is comparably large. With regard to effectiveness, LIME-C and SHAP-C find reasonable, if not always optimal, counterfactual explanations. SHAP-C, however, seems to have difficulties with highly unbalanced data. Because of its good overall performance, LIME-C seems to be a favorable alternative to SEDC, which failed for some nonlinear models to find counterfactuals because of the particular heuristic search algorithm it uses. A main upshot of this paper is that there is a good deal of room for further research. For example, we propose algorithmic adjustments that are direct upshots of the paper's findings.