 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI for Psychological Profiling from Digital Footprints: A Case Study of Big Five Personality Predictions from Spending Data
Nov 12, 2021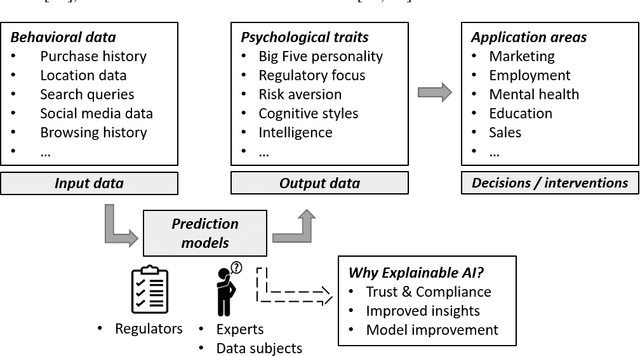
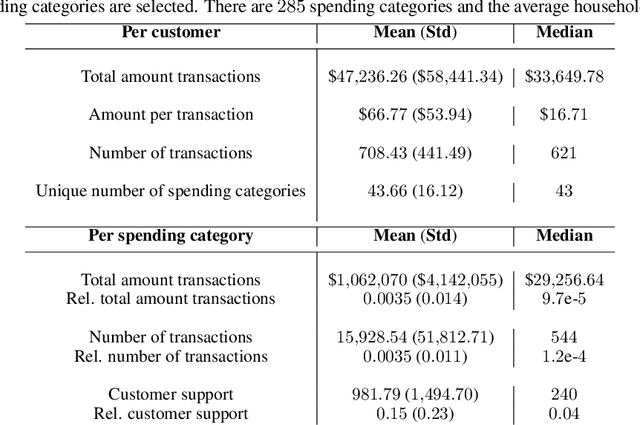
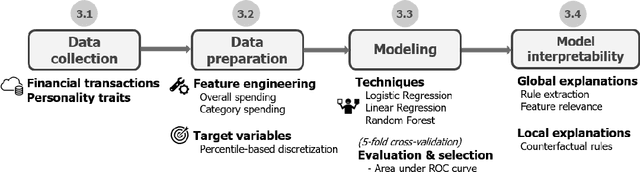
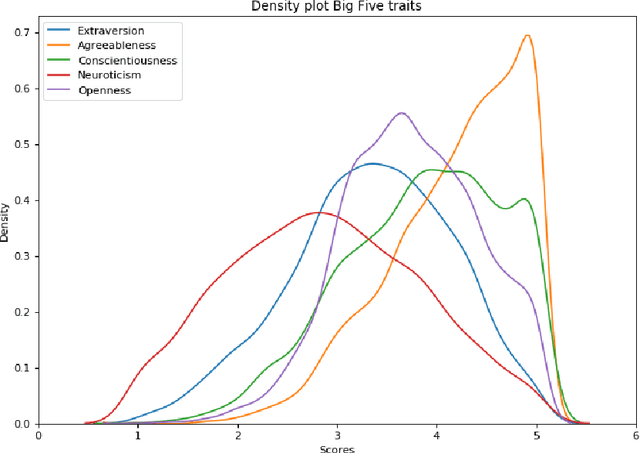
Every step we take in the digital world leaves behind a record of our behavior; a digital footprint. Research has suggested that algorithms can translate these digital footprints into accurate estimates of psychological characteristics, including personality traits, mental health or intelligence. The mechanisms by which AI generates these insights, however, often remain opaque. In this paper, we show how Explainable AI (XAI) can help domain experts and data subjects validate, question, and improve models that classify psychological traits from digital footprints. We elaborate on two popular XAI methods (rule extraction and counterfactual explanations) in the context of Big Five personality predictions (traits and facets) from financial transactions data (N = 6,408). First, we demonstrate how global rule extraction sheds light on the spending patterns identified by the model as most predictive for personality, and discuss how these rules can be used to explain, validate, and improve the model. Second, we implement local rule extraction to show that individuals are assigned to personality classes because of their unique financial behavior, and that there exists a positive link between the model's prediction confidence and the number of features that contributed to the prediction. Our experiments highlight the importance of both global and local XAI methods. By better understanding how predictive models work in general as well as how they derive an outcome for a particular person, XAI promotes accountability in a world in which AI impacts the lives of billions of people around the world.
Metafeatures-based Rule-Extraction for Classifiers on Behavioral and Textual Data
Mar 10, 2020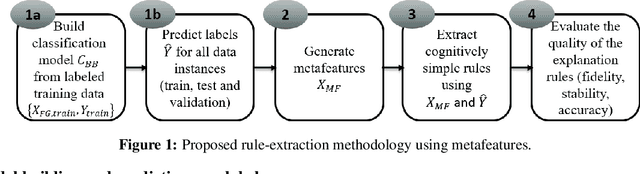
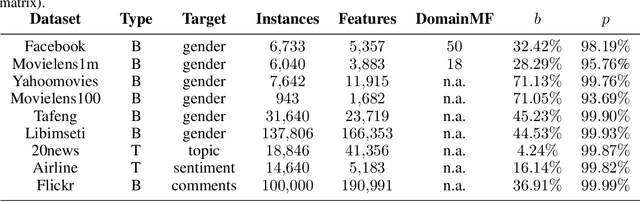

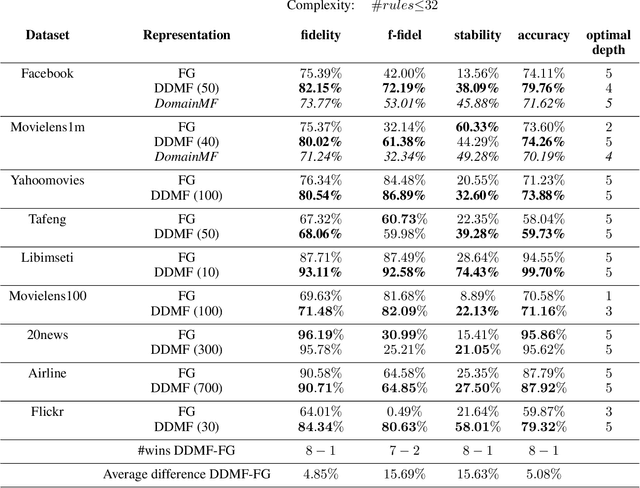
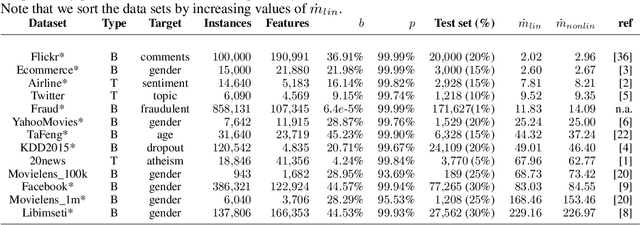
Machine learning using behavioral and text data can result in highly accurate prediction models, but these are often very difficult to interpret. Linear models require investigating thousands of coefficients, while the opaqueness of nonlinear models makes things even worse. Rule-extraction techniques have been proposed to combine the desired predictive behaviour of complex "black-box" models with explainability. However, rule-extraction in the context of ultra-high-dimensional and sparse data can be challenging, and has thus far received scant attention. Because of the sparsity and massive dimensionality, rule-extraction might fail in their primary explainability goal as the black-box model may need to be replaced by many rules, leaving the user again with an incomprehensible model. To address this problem, we develop and test a rule-extraction methodology based on higher-level, less-sparse "metafeatures". We empirically validate the quality of the rules in terms of fidelity, explanation stability and accuracy over a collection of data sets, and benchmark their performance against rules extracted using the original features. Our analysis points to key trade-offs between explainability, fidelity, accuracy, and stability that Machine Learning researchers and practitioners need to consider. Results indicate that the proposed metafeatures approach leads to better trade-offs between these, and is better able to mimic the black-box model. There is an average decrease of the loss in fidelity, accuracy, and stability from using metafeatures instead of the original fine-grained features by respectively 18.08%, 20.15% and 17.73%, all statistically significant at a 5% significance level. Metafeatures thus improve a key "cost of explainability", which we define as the loss in fidelity when replacing a black-box with an explainable model.
Counterfactual Explanation Algorithms for Behavioral and Textual Data
Dec 04, 2019

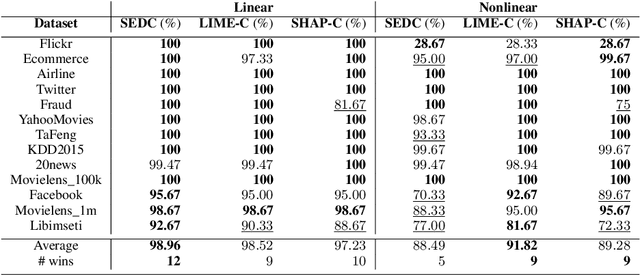
We study the interpretability of predictive systems that use high-dimensonal behavioral and textual data. Examples include predicting product interest based on online browsing data and detecting spam emails or objectionable web content. Recently, counterfactual explanations have been proposed for generating insight into model predictions, which focus on what is relevant to a particular instance. Conducting a complete search to compute counterfactuals is very time-consuming because of the huge dimensionality. To our knowledge, for behavioral and text data, only one model-agnostic heuristic algorithm (SEDC) for finding counterfactual explanations has been proposed in the literature. However, there may be better algorithms for finding counterfactuals quickly. This study aligns the recently proposed Linear Interpretable Model-agnostic Explainer (LIME) and Shapley Additive Explanations (SHAP) with the notion of counterfactual explanations, and empirically benchmarks their effectiveness and efficiency against SEDC using a collection of 13 data sets. Results show that LIME-Counterfactual (LIME-C) and SHAP-Counterfactual (SHAP-C) have low and stable computation times, but mostly, they are less efficient than SEDC. However, for certain instances on certain data sets, SEDC's run time is comparably large. With regard to effectiveness, LIME-C and SHAP-C find reasonable, if not always optimal, counterfactual explanations. SHAP-C, however, seems to have difficulties with highly unbalanced data. Because of its good overall performance, LIME-C seems to be a favorable alternative to SEDC, which failed for some nonlinear models to find counterfactuals because of the particular heuristic search algorithm it uses. A main upshot of this paper is that there is a good deal of room for further research. For example, we propose algorithmic adjustments that are direct upshots of the paper's findings.