 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetafeatures-based Rule-Extraction for Classifiers on Behavioral and Textual Data
Paper and Code
Mar 10, 2020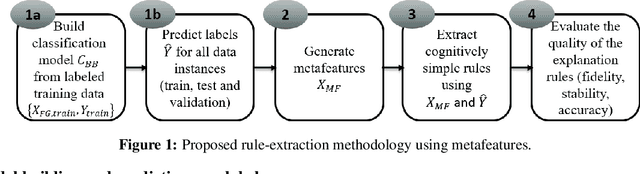
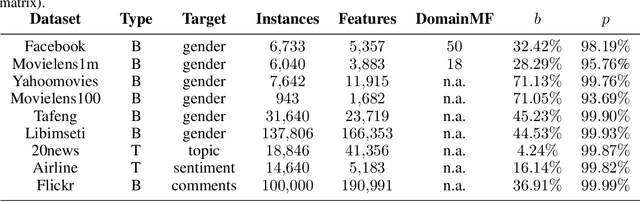

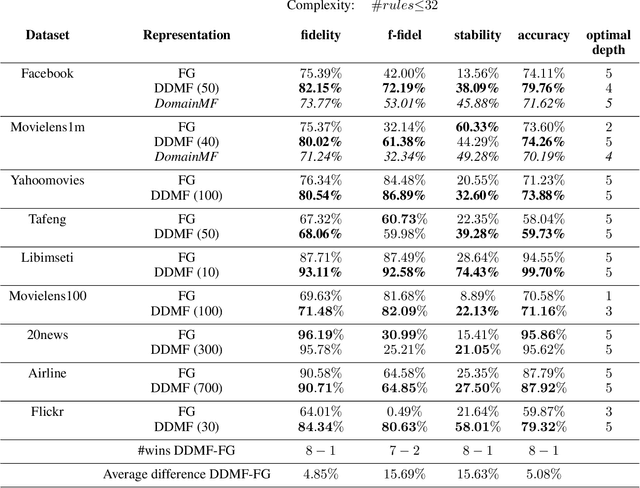
Machine learning using behavioral and text data can result in highly accurate prediction models, but these are often very difficult to interpret. Linear models require investigating thousands of coefficients, while the opaqueness of nonlinear models makes things even worse. Rule-extraction techniques have been proposed to combine the desired predictive behaviour of complex "black-box" models with explainability. However, rule-extraction in the context of ultra-high-dimensional and sparse data can be challenging, and has thus far received scant attention. Because of the sparsity and massive dimensionality, rule-extraction might fail in their primary explainability goal as the black-box model may need to be replaced by many rules, leaving the user again with an incomprehensible model. To address this problem, we develop and test a rule-extraction methodology based on higher-level, less-sparse "metafeatures". We empirically validate the quality of the rules in terms of fidelity, explanation stability and accuracy over a collection of data sets, and benchmark their performance against rules extracted using the original features. Our analysis points to key trade-offs between explainability, fidelity, accuracy, and stability that Machine Learning researchers and practitioners need to consider. Results indicate that the proposed metafeatures approach leads to better trade-offs between these, and is better able to mimic the black-box model. There is an average decrease of the loss in fidelity, accuracy, and stability from using metafeatures instead of the original fine-grained features by respectively 18.08%, 20.15% and 17.73%, all statistically significant at a 5% significance level. Metafeatures thus improve a key "cost of explainability", which we define as the loss in fidelity when replacing a black-box with an explainable model.