 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTight convex relaxations for sparse matrix factorization
Dec 04, 2014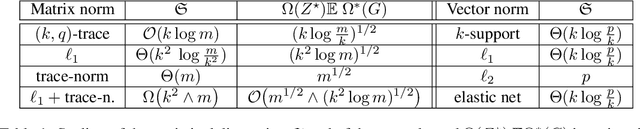


Based on a new atomic norm, we propose a new convex formulation for sparse matrix factorization problems in which the number of nonzero elements of the factors is assumed fixed and known. The formulation counts sparse PCA with multiple factors, subspace clustering and low-rank sparse bilinear regression as potential applications. We compute slow rates and an upper bound on the statistical dimension of the suggested norm for rank 1 matrices, showing that its statistical dimension is an order of magnitude smaller than the usual $\ell\_1$-norm, trace norm and their combinations. Even though our convex formulation is in theory hard and does not lead to provably polynomial time algorithmic schemes, we propose an active set algorithm leveraging the structure of the convex problem to solve it and show promising numerical results.
A statistical model for tensor PCA
Nov 04, 2014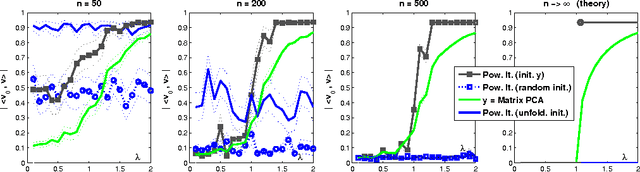
We consider the Principal Component Analysis problem for large tensors of arbitrary order $k$ under a single-spike (or rank-one plus noise) model. On the one hand, we use information theory, and recent results in probability theory, to establish necessary and sufficient conditions under which the principal component can be estimated using unbounded computational resources. It turns out that this is possible as soon as the signal-to-noise ratio $\beta$ becomes larger than $C\sqrt{k\log k}$ (and in particular $\beta$ can remain bounded as the problem dimensions increase). On the other hand, we analyze several polynomial-time estimation algorithms, based on tensor unfolding, power iteration and message passing ideas from graphical models. We show that, unless the signal-to-noise ratio diverges in the system dimensions, none of these approaches succeeds. This is possibly related to a fundamental limitation of computationally tractable estimators for this problem. We discuss various initializations for tensor power iteration, and show that a tractable initialization based on the spectrum of the matricized tensor outperforms significantly baseline methods, statistically and computationally. Finally, we consider the case in which additional side information is available about the unknown signal. We characterize the amount of side information that allows the iterative algorithms to converge to a good estimate.
Link Prediction in Graphs with Autoregressive Features
Sep 14, 2012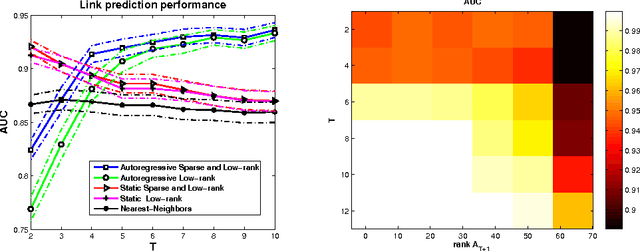
In the paper, we consider the problem of link prediction in time-evolving graphs. We assume that certain graph features, such as the node degree, follow a vector autoregressive (VAR) model and we propose to use this information to improve the accuracy of prediction. Our strategy involves a joint optimization procedure over the space of adjacency matrices and VAR matrices which takes into account both sparsity and low rank properties of the matrices. Oracle inequalities are derived and illustrate the trade-offs in the choice of smoothing parameters when modeling the joint effect of sparsity and low rank property. The estimate is computed efficiently using proximal methods through a generalized forward-backward agorithm.
Estimation of Simultaneously Sparse and Low Rank Matrices
Jun 27, 2012The paper introduces a penalized matrix estimation procedure aiming at solutions which are sparse and low-rank at the same time. Such structures arise in the context of social networks or protein interactions where underlying graphs have adjacency matrices which are block-diagonal in the appropriate basis. We introduce a convex mixed penalty which involves $\ell_1$-norm and trace norm simultaneously. We obtain an oracle inequality which indicates how the two effects interact according to the nature of the target matrix. We bound generalization error in the link prediction problem. We also develop proximal descent strategies to solve the optimization problem efficiently and evaluate performance on synthetic and real data sets.
Graph Prediction in a Low-Rank and Autoregressive Setting
May 09, 2012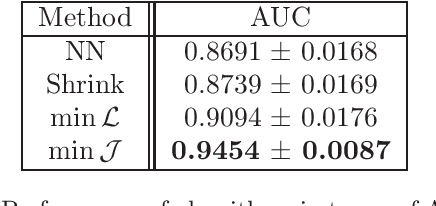
We study the problem of prediction for evolving graph data. We formulate the problem as the minimization of a convex objective encouraging sparsity and low-rank of the solution, that reflect natural graph properties. The convex formulation allows to obtain oracle inequalities and efficient solvers. We provide empirical results for our algorithm and comparison with competing methods, and point out two open questions related to compressed sensing and algebra of low-rank and sparse matrices.
A Regularization Approach for Prediction of Edges and Node Features in Dynamic Graphs
Mar 24, 2012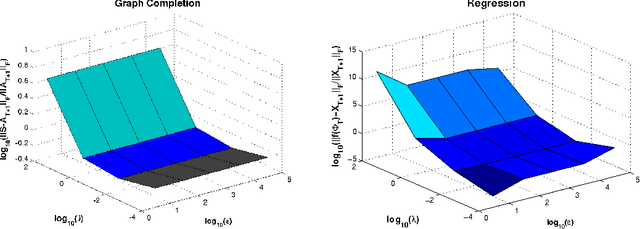
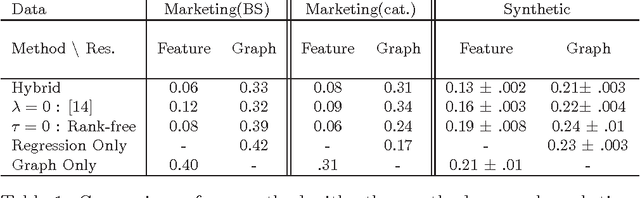
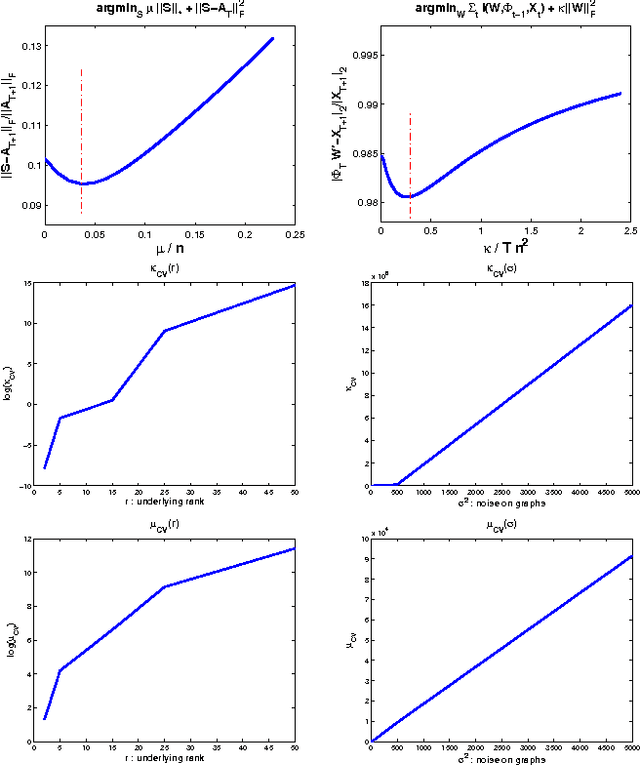
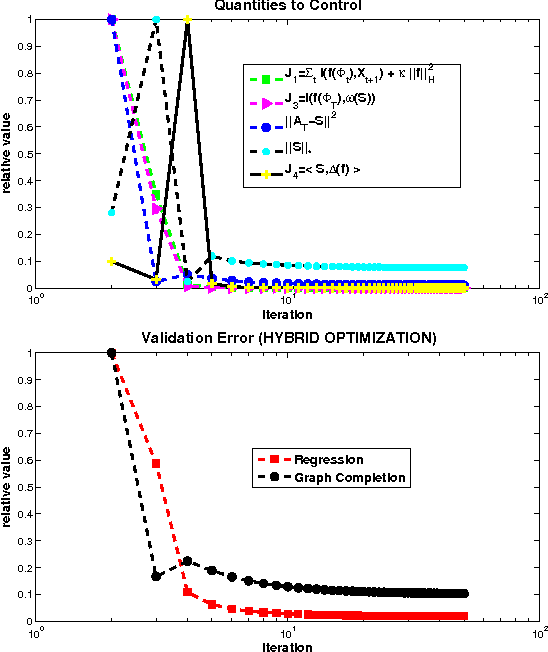
We consider the two problems of predicting links in a dynamic graph sequence and predicting functions defined at each node of the graph. In many applications, the solution of one problem is useful for solving the other. Indeed, if these functions reflect node features, then they are related through the graph structure. In this paper, we formulate a hybrid approach that simultaneously learns the structure of the graph and predicts the values of the node-related functions. Our approach is based on the optimization of a joint regularization objective. We empirically test the benefits of the proposed method with both synthetic and real data. The results indicate that joint regularization improves prediction performance over the graph evolution and the node features.