 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Conditional Gradient - Smoothing Algorithms with Applications to Sparse and Low Rank Regularization
Apr 15, 2014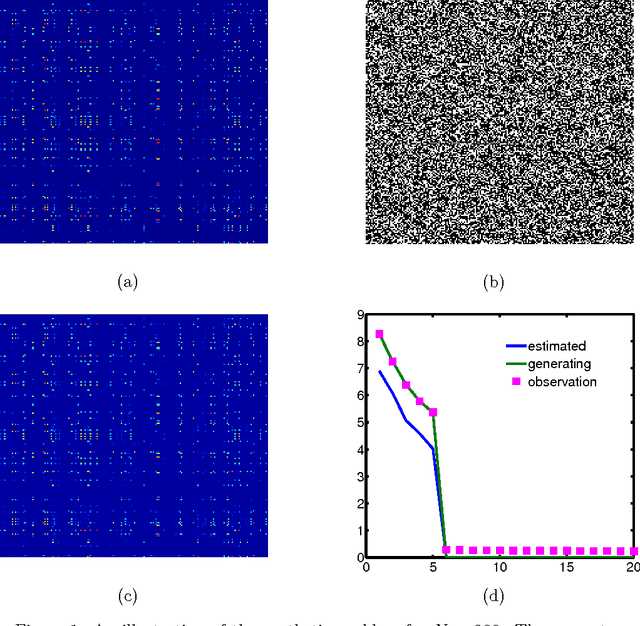

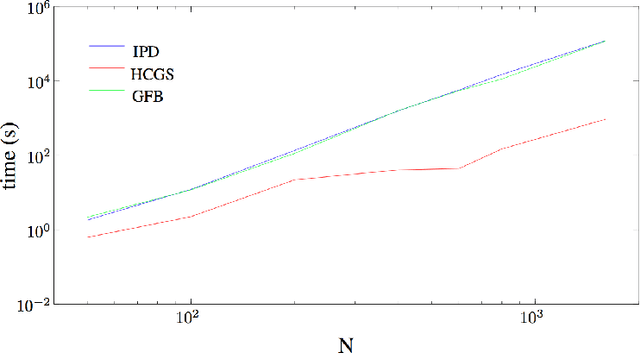
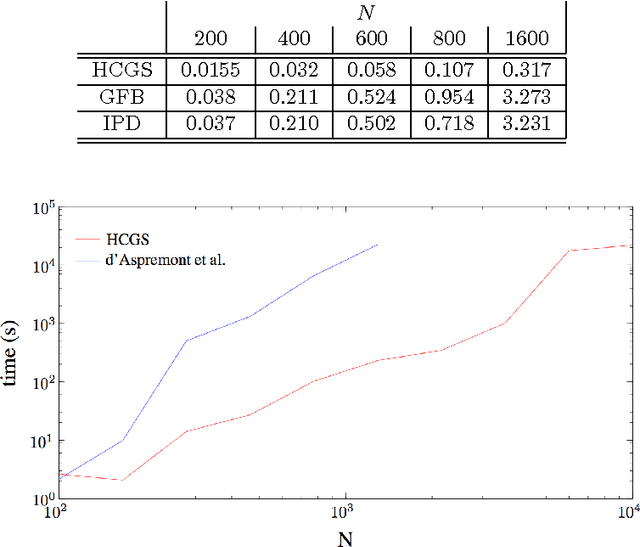
We study a hybrid conditional gradient - smoothing algorithm (HCGS) for solving composite convex optimization problems which contain several terms over a bounded set. Examples of these include regularization problems with several norms as penalties and a norm constraint. HCGS extends conditional gradient methods to cases with multiple nonsmooth terms, in which standard conditional gradient methods may be difficult to apply. The HCGS algorithm borrows techniques from smoothing proximal methods and requires first-order computations (subgradients and proximity operations). Unlike proximal methods, HCGS benefits from the advantages of conditional gradient methods, which render it more efficient on certain large scale optimization problems. We demonstrate these advantages with simulations on two matrix optimization problems: regularization of matrices with combined $\ell_1$ and trace norm penalties; and a convex relaxation of sparse PCA.
On Sparsity Inducing Regularization Methods for Machine Learning
Mar 25, 2013During the past years there has been an explosion of interest in learning methods based on sparsity regularization. In this paper, we discuss a general class of such methods, in which the regularizer can be expressed as the composition of a convex function $\omega$ with a linear function. This setting includes several methods such the group Lasso, the Fused Lasso, multi-task learning and many more. We present a general approach for solving regularization problems of this kind, under the assumption that the proximity operator of the function $\omega$ is available. Furthermore, we comment on the application of this approach to support vector machines, a technique pioneered by the groundbreaking work of Vladimir Vapnik.
PRISMA: PRoximal Iterative SMoothing Algorithm
Nov 18, 2012
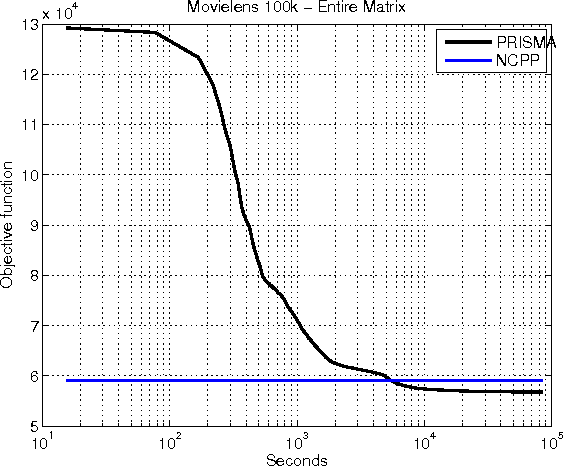


Motivated by learning problems including max-norm regularized matrix completion and clustering, robust PCA and sparse inverse covariance selection, we propose a novel optimization algorithm for minimizing a convex objective which decomposes into three parts: a smooth part, a simple non-smooth Lipschitz part, and a simple non-smooth non-Lipschitz part. We use a time variant smoothing strategy that allows us to obtain a guarantee that does not depend on knowing in advance the total number of iterations nor a bound on the domain.
Sparse Prediction with the $k$-Support Norm
Jun 12, 2012
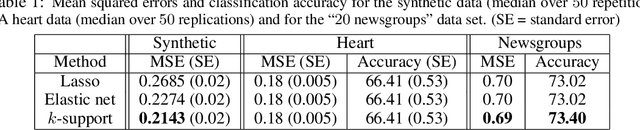

We derive a novel norm that corresponds to the tightest convex relaxation of sparsity combined with an $\ell_2$ penalty. We show that this new {\em $k$-support norm} provides a tighter relaxation than the elastic net and is thus a good replacement for the Lasso or the elastic net in sparse prediction problems. Through the study of the $k$-support norm, we also bound the looseness of the elastic net, thus shedding new light on it and providing justification for its use.
A Regularization Approach for Prediction of Edges and Node Features in Dynamic Graphs
Mar 24, 2012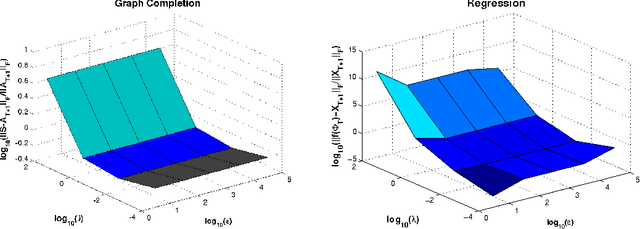
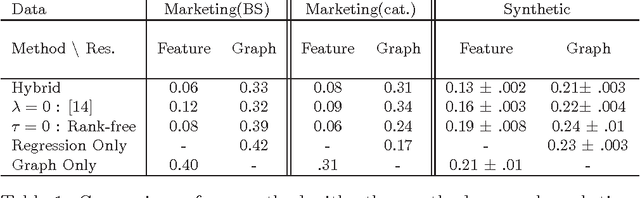
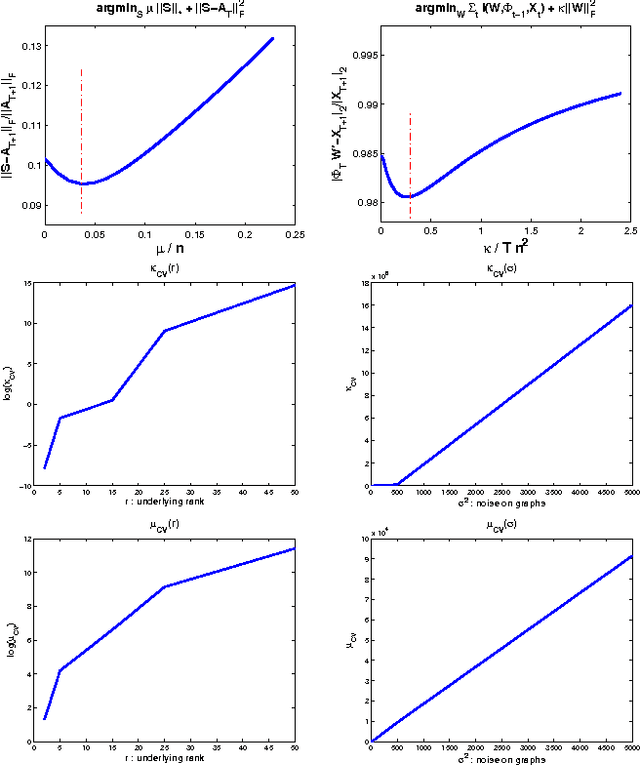
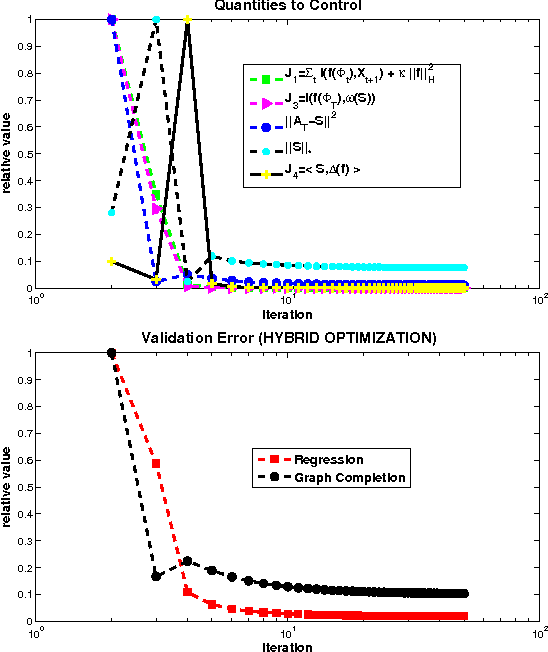
We consider the two problems of predicting links in a dynamic graph sequence and predicting functions defined at each node of the graph. In many applications, the solution of one problem is useful for solving the other. Indeed, if these functions reflect node features, then they are related through the graph structure. In this paper, we formulate a hybrid approach that simultaneously learns the structure of the graph and predicts the values of the node-related functions. Our approach is based on the optimization of a joint regularization objective. We empirically test the benefits of the proposed method with both synthetic and real data. The results indicate that joint regularization improves prediction performance over the graph evolution and the node features.
A General Framework for Structured Sparsity via Proximal Optimization
Jun 26, 2011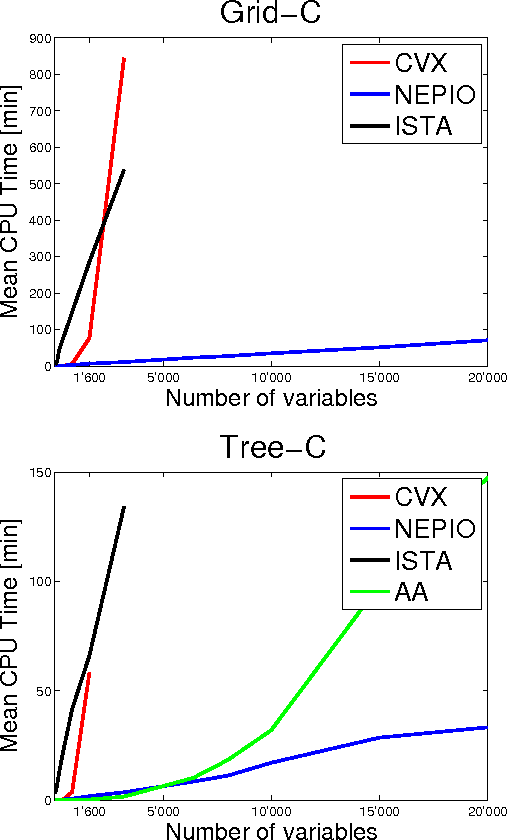
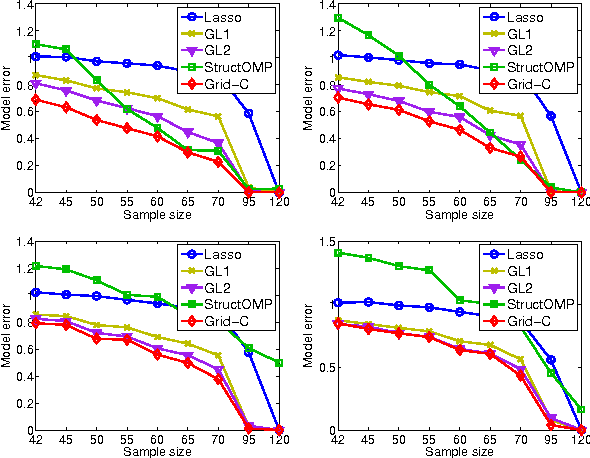
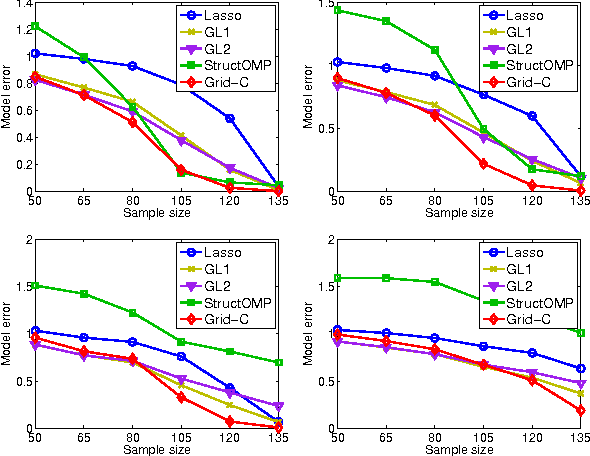

We study a generalized framework for structured sparsity. It extends the well-known methods of Lasso and Group Lasso by incorporating additional constraints on the variables as part of a convex optimization problem. This framework provides a straightforward way of favouring prescribed sparsity patterns, such as orderings, contiguous regions and overlapping groups, among others. Existing optimization methods are limited to specific constraint sets and tend to not scale well with sample size and dimensionality. We propose a novel first order proximal method, which builds upon results on fixed points and successive approximations. The algorithm can be applied to a general class of conic and norm constraints sets and relies on a proximity operator subproblem which can be computed explicitly. Experiments on different regression problems demonstrate the efficiency of the optimization algorithm and its scalability with the size of the problem. They also demonstrate state of the art statistical performance, which improves over Lasso and StructOMP.
Efficient First Order Methods for Linear Composite Regularizers
Apr 07, 2011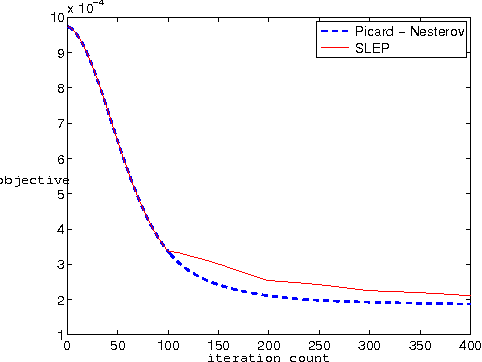
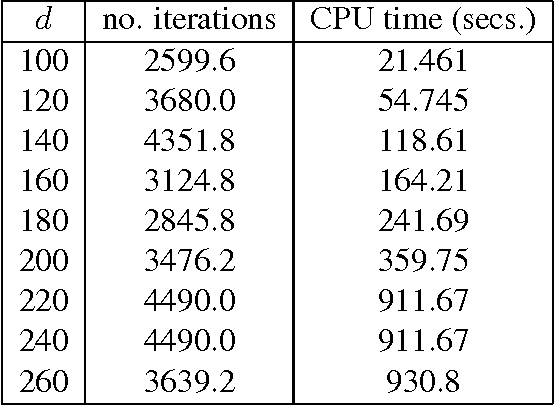
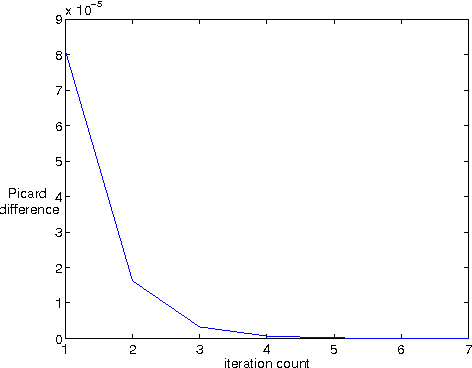
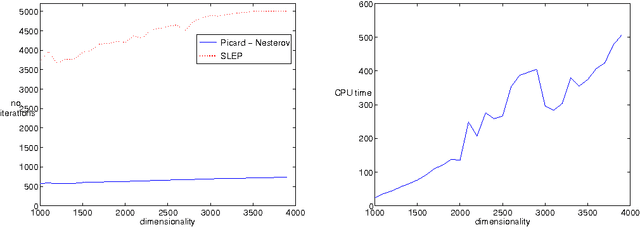
A wide class of regularization problems in machine learning and statistics employ a regularization term which is obtained by composing a simple convex function \omega with a linear transformation. This setting includes Group Lasso methods, the Fused Lasso and other total variation methods, multi-task learning methods and many more. In this paper, we present a general approach for computing the proximity operator of this class of regularizers, under the assumption that the proximity operator of the function \omega is known in advance. Our approach builds on a recent line of research on optimal first order optimization methods and uses fixed point iterations for numerically computing the proximity operator. It is more general than current approaches and, as we show with numerical simulations, computationally more efficient than available first order methods which do not achieve the optimal rate. In particular, our method outperforms state of the art O(1/T) methods for overlapping Group Lasso and matches optimal O(1/T^2) methods for the Fused Lasso and tree structured Group Lasso.
When is there a representer theorem? Vector versus matrix regularizers
Sep 09, 2008

We consider a general class of regularization methods which learn a vector of parameters on the basis of linear measurements. It is well known that if the regularizer is a nondecreasing function of the inner product then the learned vector is a linear combination of the input data. This result, known as the {\em representer theorem}, is at the basis of kernel-based methods in machine learning. In this paper, we prove the necessity of the above condition, thereby completing the characterization of kernel methods based on regularization. We further extend our analysis to regularization methods which learn a matrix, a problem which is motivated by the application to multi-task learning. In this context, we study a more general representer theorem, which holds for a larger class of regularizers. We provide a necessary and sufficient condition for these class of matrix regularizers and highlight them with some concrete examples of practical importance. Our analysis uses basic principles from matrix theory, especially the useful notion of matrix nondecreasing function.
* 22 pages 2 figures