 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolNet: Open-source deep learning models for photovoltaic power forecasting across the globe
May 23, 2024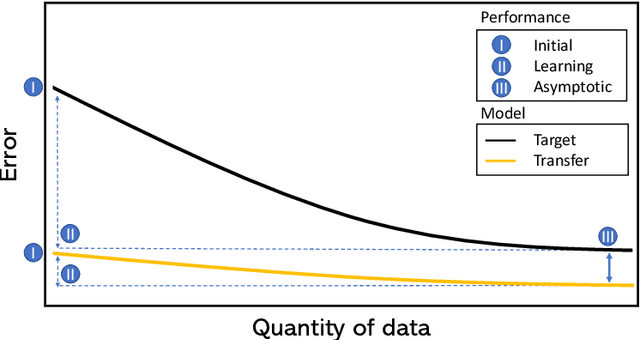
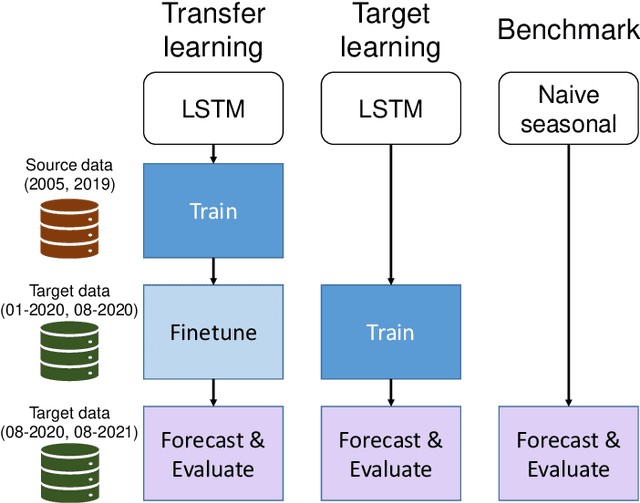
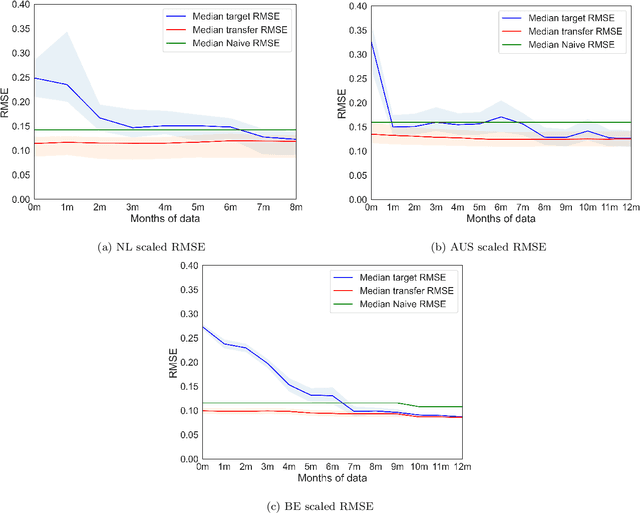
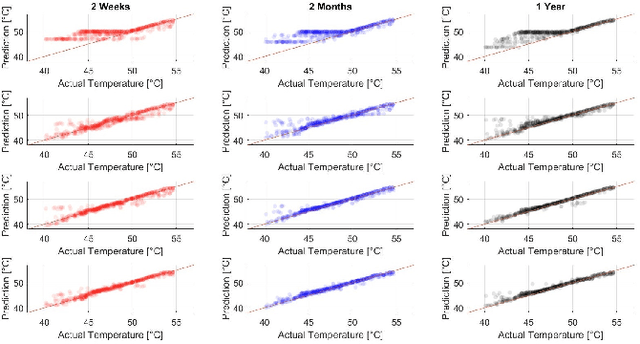
Deep learning models have gained increasing prominence in recent years in the field of solar pho-tovoltaic (PV) forecasting. One drawback of these models is that they require a lot of high-quality data to perform well. This is often infeasible in practice, due to poor measurement infrastructure in legacy systems and the rapid build-up of new solar systems across the world. This paper proposes SolNet: a novel, general-purpose, multivariate solar power forecaster, which addresses these challenges by using a two-step forecasting pipeline which incorporates transfer learning from abundant synthetic data generated from PVGIS, before fine-tuning on observational data. Using actual production data from hundreds of sites in the Netherlands, Australia and Belgium, we show that SolNet improves forecasting performance over data-scarce settings as well as baseline models. We find transfer learning benefits to be the strongest when only limited observational data is available. At the same time we provide several guidelines and considerations for transfer learning practitioners, as our results show that weather data, seasonal patterns, amount of synthetic data and possible mis-specification in source location, can have a major impact on the results. The SolNet models created in this way are applicable for any land-based solar photovoltaic system across the planet where simulated and observed data can be combined to obtain improved forecasting capabilities.
A Dual Perspective of Reinforcement Learning for Imposing Policy Constraints
Apr 25, 2024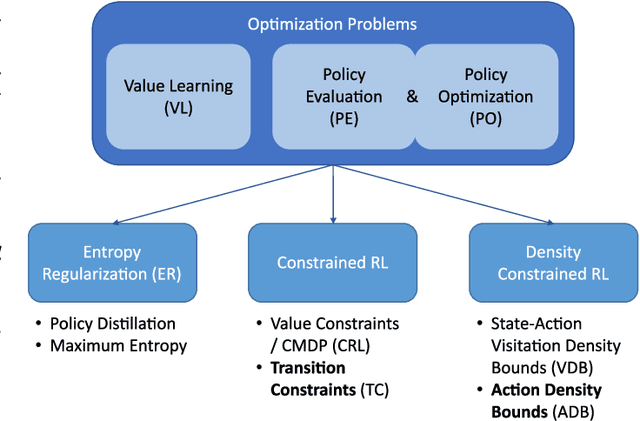

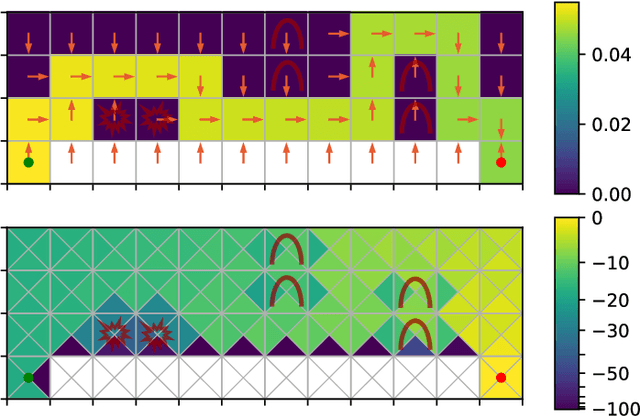
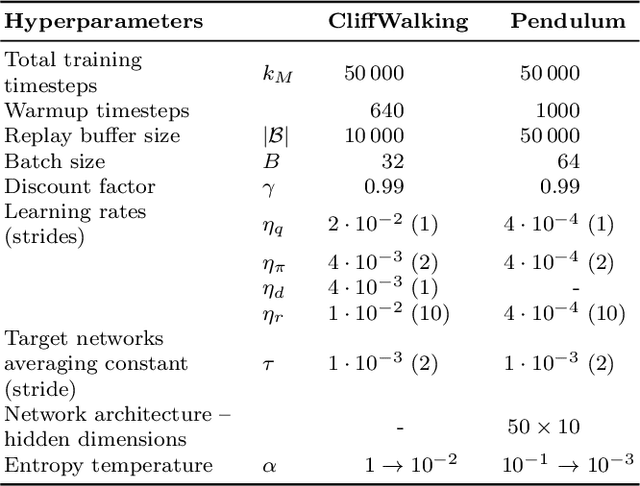
Model-free reinforcement learning methods lack an inherent mechanism to impose behavioural constraints on the trained policies. While certain extensions exist, they remain limited to specific types of constraints, such as value constraints with additional reward signals or visitation density constraints. In this work we try to unify these existing techniques and bridge the gap with classical optimization and control theory, using a generic primal-dual framework for value-based and actor-critic reinforcement learning methods. The obtained dual formulations turn out to be especially useful for imposing additional constraints on the learned policy, as an intrinsic relationship between such dual constraints (or regularization terms) and reward modifications in the primal is reveiled. Furthermore, using this framework, we are able to introduce some novel types of constraints, allowing to impose bounds on the policy's action density or on costs associated with transitions between consecutive states and actions. From the adjusted primal-dual optimization problems, a practical algorithm is derived that supports various combinations of policy constraints that are automatically handled throughout training using trainable reward modifications. The resulting $\texttt{DualCRL}$ method is examined in more detail and evaluated under different (combinations of) constraints on two interpretable environments. The results highlight the efficacy of the method, which ultimately provides the designer of such systems with a versatile toolbox of possible policy constraints.
Accelerated sparse Kernel Spectral Clustering for large scale data clustering problems
Oct 20, 2023



An improved version of the sparse multiway kernel spectral clustering (KSC) is presented in this brief. The original algorithm is derived from weighted kernel principal component (KPCA) analysis formulated within the primal-dual least-squares support vector machine (LS-SVM) framework. Sparsity is achieved then by the combination of the incomplete Cholesky decomposition (ICD) based low rank approximation of the kernel matrix with the so called reduced set method. The original ICD based sparse KSC algorithm was reported to be computationally far too demanding, especially when applied on large scale data clustering problems that actually it was designed for, which has prevented to gain more than simply theoretical relevance so far. This is altered by the modifications reported in this brief that drastically improve the computational characteristics. Solving the alternative, symmetrized version of the computationally most demanding core eigenvalue problem eliminates the necessity of forming and SVD of large matrices during the model construction. This results in solving clustering problems now within seconds that were reported to require hours without altering the results. Furthermore, sparsity is also improved significantly, leading to more compact model representation, increasing further not only the computational efficiency but also the descriptive power. These transform the original, only theoretically relevant ICD based sparse KSC algorithm applicable for large scale practical clustering problems. Theoretical results and improvements are demonstrated by computational experiments on carefully selected synthetic data as well as on real life problems such as image segmentation.
Increasing Performance And Sample Efficiency With Model-agnostic Interactive Feature Attributions
Jun 28, 2023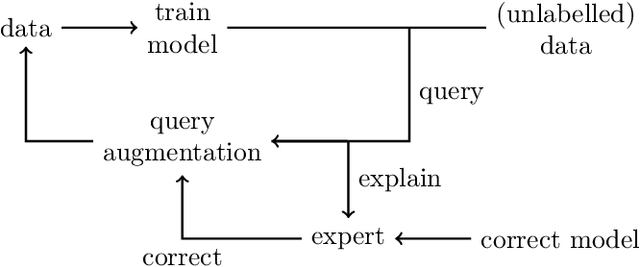
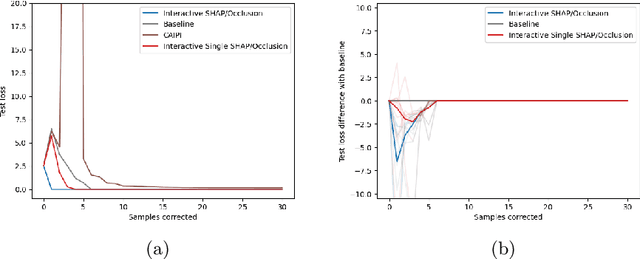
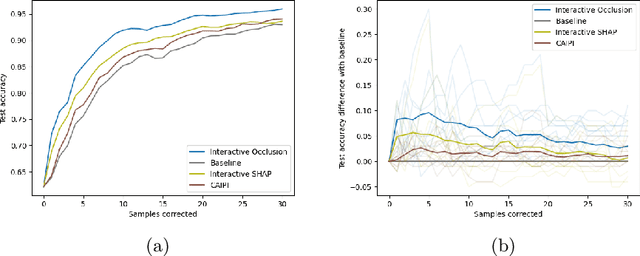
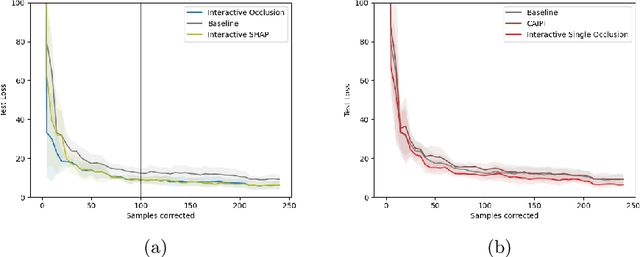
Model-agnostic feature attributions can provide local insights in complex ML models. If the explanation is correct, a domain expert can validate and trust the model's decision. However, if it contradicts the expert's knowledge, related work only corrects irrelevant features to improve the model. To allow for unlimited interaction, in this paper we provide model-agnostic implementations for two popular explanation methods (Occlusion and Shapley values) to enforce entirely different attributions in the complex model. For a particular set of samples, we use the corrected feature attributions to generate extra local data, which is used to retrain the model to have the right explanation for the samples. Through simulated and real data experiments on a variety of models we show how our proposed approach can significantly improve the model's performance only by augmenting its training dataset based on corrected explanations. Adding our interactive explanations to active learning settings increases the sample efficiency significantly and outperforms existing explanatory interactive strategies. Additionally we explore how a domain expert can provide feature attributions which are sufficiently correct to improve the model.
Explaining the Model and Feature Dependencies by Decomposition of the Shapley Value
Jun 19, 2023Shapley values have become one of the go-to methods to explain complex models to end-users. They provide a model agnostic post-hoc explanation with foundations in game theory: what is the worth of a player (in machine learning, a feature value) in the objective function (the output of the complex machine learning model). One downside is that they always require outputs of the model when some features are missing. These are usually computed by taking the expectation over the missing features. This however introduces a non-trivial choice: do we condition on the unknown features or not? In this paper we examine this question and claim that they represent two different explanations which are valid for different end-users: one that explains the model and one that explains the model combined with the feature dependencies in the data. We propose a new algorithmic approach to combine both explanations, removing the burden of choice and enhancing the explanatory power of Shapley values, and show that it achieves intuitive results on simple problems. We apply our method to two real-world datasets and discuss the explanations. Finally, we demonstrate how our method is either equivalent or superior to state-to-of-art Shapley value implementations while simultaneously allowing for increased insight into the model-data structure.
CoRe-Sleep: A Multimodal Fusion Framework for Time Series Robust to Imperfect Modalities
Mar 27, 2023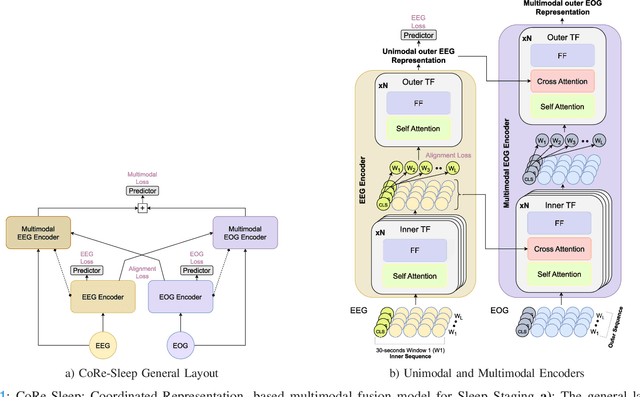
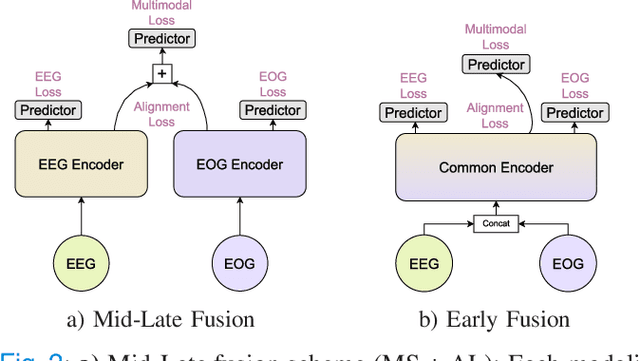
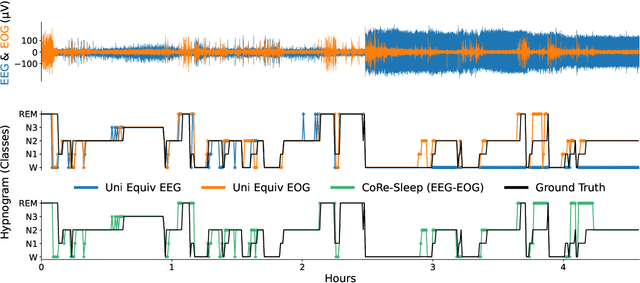
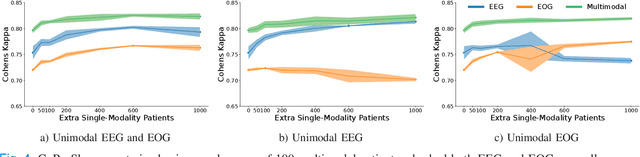
Sleep abnormalities can have severe health consequences. Automated sleep staging, i.e. labelling the sequence of sleep stages from the patient's physiological recordings, could simplify the diagnostic process. Previous work on automated sleep staging has achieved great results, mainly relying on the EEG signal. However, often multiple sources of information are available beyond EEG. This can be particularly beneficial when the EEG recordings are noisy or even missing completely. In this paper, we propose CoRe-Sleep, a Coordinated Representation multimodal fusion network that is particularly focused on improving the robustness of signal analysis on imperfect data. We demonstrate how appropriately handling multimodal information can be the key to achieving such robustness. CoRe-Sleep tolerates noisy or missing modalities segments, allowing training on incomplete data. Additionally, it shows state-of-the-art performance when testing on both multimodal and unimodal data using a single model on SHHS-1, the largest publicly available study that includes sleep stage labels. The results indicate that training the model on multimodal data does positively influence performance when tested on unimodal data. This work aims at bridging the gap between automated analysis tools and their clinical utility.
Valuing knowledge, information and agency in Multi-agent Reinforcement Learning: a case study in smart buildings
Mar 09, 2018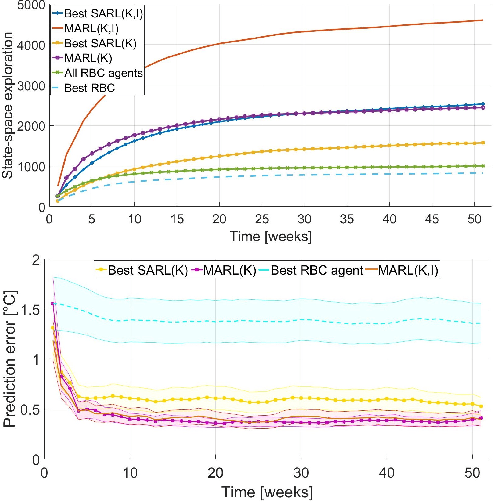
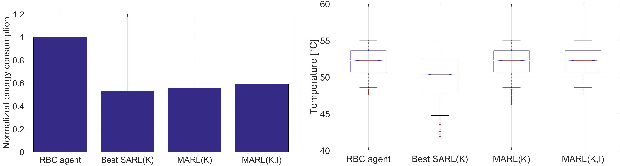
Increasing energy efficiency in buildings can reduce costs and emissions substantially. Historically, this has been treated as a local, or single-agent, optimization problem. However, many buildings utilize the same types of thermal equipment e.g. electric heaters and hot water vessels. During operation, occupants in these buildings interact with the equipment differently thereby driving them to diverse regions in the state-space. Reinforcement learning agents can learn from these interactions, recorded as sensor data, to optimize the overall energy efficiency. However, if these agents operate individually at a household level, they can not exploit the replicated structure in the problem. In this paper, we demonstrate that this problem can indeed benefit from multi-agent collaboration by making use of targeted exploration of the state-space allowing for better generalization. We also investigate trade-offs between integrating human knowledge and additional sensors. Results show that savings of over 40% are possible with collaborative multi-agent systems making use of either expert knowledge or additional sensors with no loss of occupant comfort. We find that such multi-agent systems comfortably outperform comparable single agent systems.
Complexity Issues and Randomization Strategies in Frank-Wolfe Algorithms for Machine Learning
Oct 15, 2014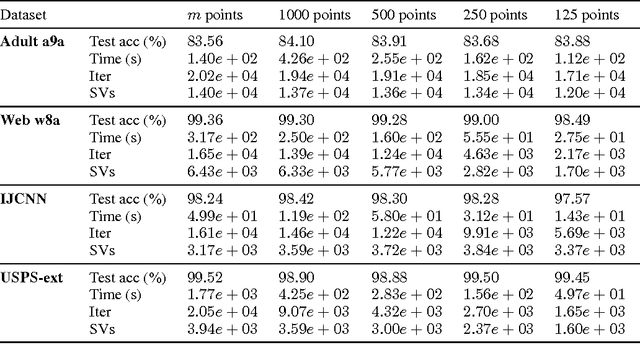
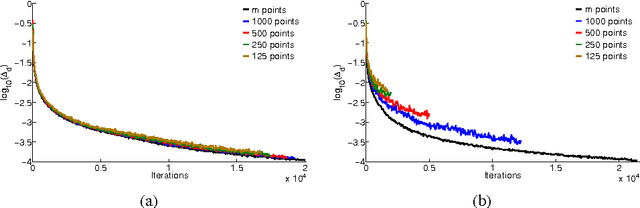
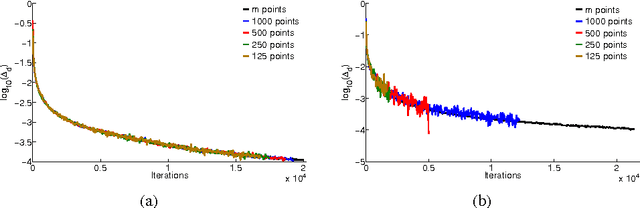

Frank-Wolfe algorithms for convex minimization have recently gained considerable attention from the Optimization and Machine Learning communities, as their properties make them a suitable choice in a variety of applications. However, as each iteration requires to optimize a linear model, a clever implementation is crucial to make such algorithms viable on large-scale datasets. For this purpose, approximation strategies based on a random sampling have been proposed by several researchers. In this work, we perform an experimental study on the effectiveness of these techniques, analyze possible alternatives and provide some guidelines based on our results.
Hybrid Conditional Gradient - Smoothing Algorithms with Applications to Sparse and Low Rank Regularization
Apr 15, 2014

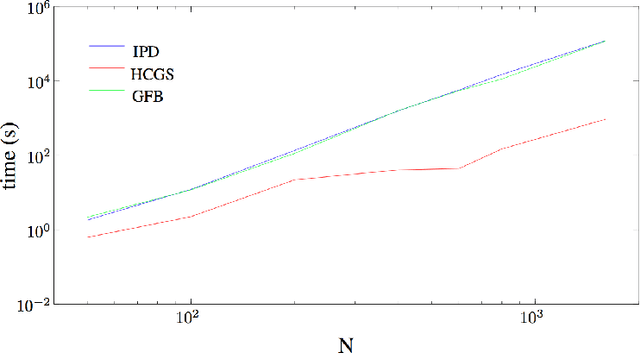
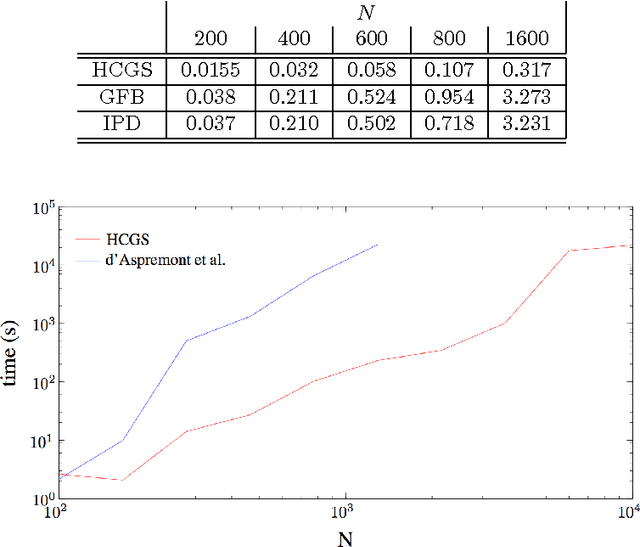
We study a hybrid conditional gradient - smoothing algorithm (HCGS) for solving composite convex optimization problems which contain several terms over a bounded set. Examples of these include regularization problems with several norms as penalties and a norm constraint. HCGS extends conditional gradient methods to cases with multiple nonsmooth terms, in which standard conditional gradient methods may be difficult to apply. The HCGS algorithm borrows techniques from smoothing proximal methods and requires first-order computations (subgradients and proximity operations). Unlike proximal methods, HCGS benefits from the advantages of conditional gradient methods, which render it more efficient on certain large scale optimization problems. We demonstrate these advantages with simulations on two matrix optimization problems: regularization of matrices with combined $\ell_1$ and trace norm penalties; and a convex relaxation of sparse PCA.
EnsembleSVM: A Library for Ensemble Learning Using Support Vector Machines
Mar 04, 2014
EnsembleSVM is a free software package containing efficient routines to perform ensemble learning with support vector machine (SVM) base models. It currently offers ensemble methods based on binary SVM models. Our implementation avoids duplicate storage and evaluation of support vectors which are shared between constituent models. Experimental results show that using ensemble approaches can drastically reduce training complexity while maintaining high predictive accuracy. The EnsembleSVM software package is freely available online at http://esat.kuleuven.be/stadius/ensemblesvm.
* 5 pages, 1 table