 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing binary classifiers using only positive and unlabeled data
Dec 30, 2015
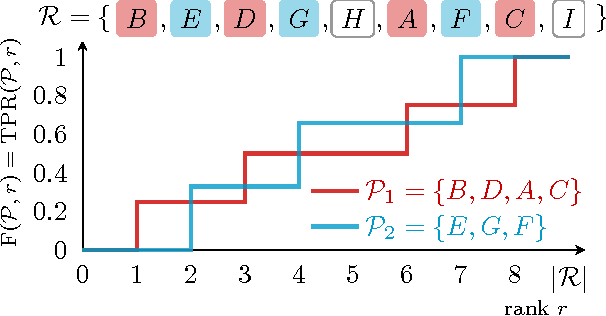
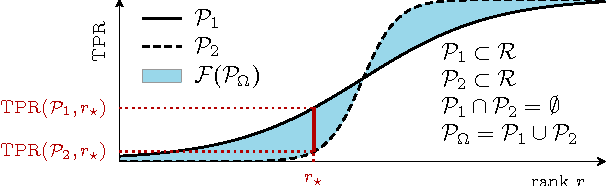
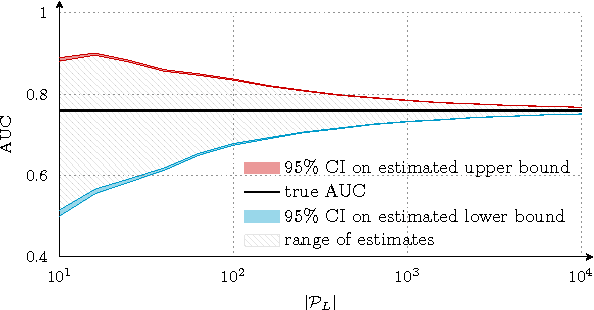
Assessing the performance of a learned model is a crucial part of machine learning. However, in some domains only positive and unlabeled examples are available, which prohibits the use of most standard evaluation metrics. We propose an approach to estimate any metric based on contingency tables, including ROC and PR curves, using only positive and unlabeled data. Estimating these performance metrics is essentially reduced to estimating the fraction of (latent) positives in the unlabeled set, assuming known positives are a random sample of all positives. We provide theoretical bounds on the quality of our estimates, illustrate the importance of estimating the fraction of positives in the unlabeled set and demonstrate empirically that we are able to reliably estimate ROC and PR curves on real data.
Building Classifiers to Predict the Start of Glucose-Lowering Pharmacotherapy Using Belgian Health Expenditure Data
Apr 28, 2015
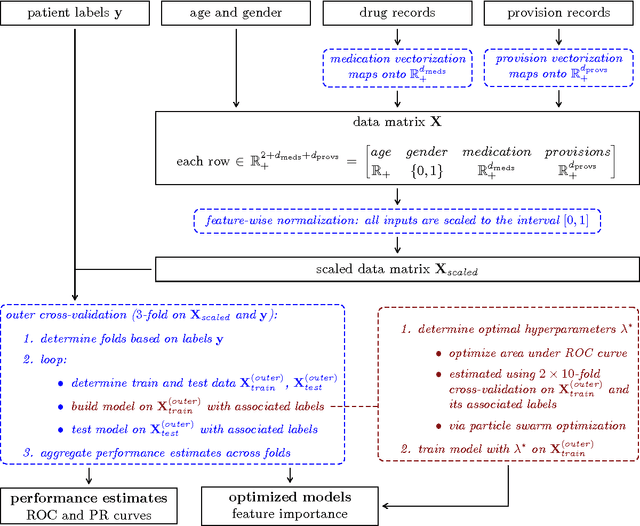

Early diagnosis is important for type 2 diabetes (T2D) to improve patient prognosis, prevent complications and reduce long-term treatment costs. We present a novel risk profiling approach based exclusively on health expenditure data that is available to Belgian mutual health insurers. We used expenditure data related to drug purchases and medical provisions to construct models that predict whether a patient will start glucose-lowering pharmacotherapy in the coming years, based on that patient's recent medical expenditure history. The design and implementation of the modeling strategy are discussed in detail and several learning methods are benchmarked for our application. Our best performing model obtains between 74.9% and 76.8% area under the ROC curve, which is comparable to state-of-the-art risk prediction approaches for T2D based on questionnaires. In contrast to other methods, our approach can be implemented on a population-wide scale at virtually no extra operational cost. Possibly, our approach can be further improved by additional information about some risk factors of T2D that is unavailable in health expenditure data.
Hyperparameter Search in Machine Learning
Apr 06, 2015We introduce the hyperparameter search problem in the field of machine learning and discuss its main challenges from an optimization perspective. Machine learning methods attempt to build models that capture some element of interest based on given data. Most common learning algorithms feature a set of hyperparameters that must be determined before training commences. The choice of hyperparameters can significantly affect the resulting model's performance, but determining good values can be complex; hence a disciplined, theoretically sound search strategy is essential.
Easy Hyperparameter Search Using Optunity
Dec 02, 2014
Optunity is a free software package dedicated to hyperparameter optimization. It contains various types of solvers, ranging from undirected methods to direct search, particle swarm and evolutionary optimization. The design focuses on ease of use, flexibility, code clarity and interoperability with existing software in all machine learning environments. Optunity is written in Python and contains interfaces to environments such as R and MATLAB. Optunity uses a BSD license and is freely available online at http://www.optunity.net.
A Robust Ensemble Approach to Learn From Positive and Unlabeled Data Using SVM Base Models
Oct 21, 2014
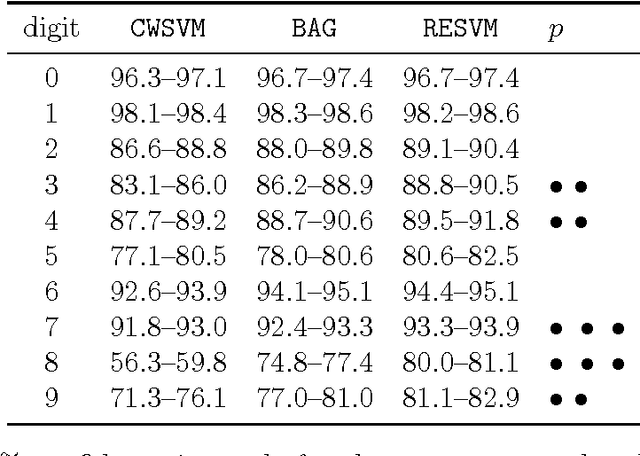
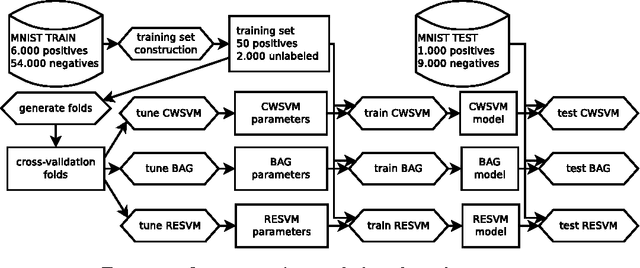
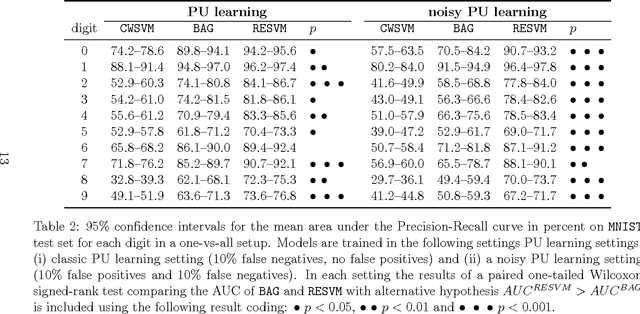
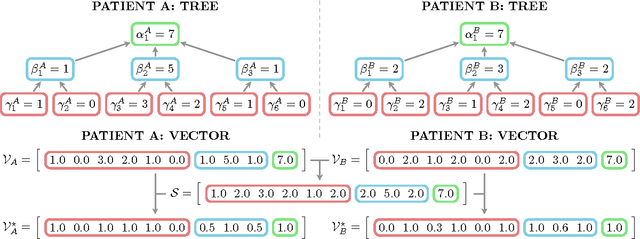
We present a novel approach to learn binary classifiers when only positive and unlabeled instances are available (PU learning). This problem is routinely cast as a supervised task with label noise in the negative set. We use an ensemble of SVM models trained on bootstrap resamples of the training data for increased robustness against label noise. The approach can be considered in a bagging framework which provides an intuitive explanation for its mechanics in a semi-supervised setting. We compared our method to state-of-the-art approaches in simulations using multiple public benchmark data sets. The included benchmark comprises three settings with increasing label noise: (i) fully supervised, (ii) PU learning and (iii) PU learning with false positives. Our approach shows a marginal improvement over existing methods in the second setting and a significant improvement in the third.
Fast Prediction with SVM Models Containing RBF Kernels
Oct 03, 2014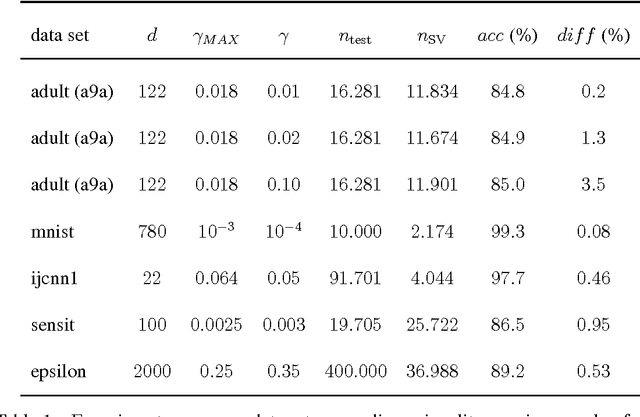

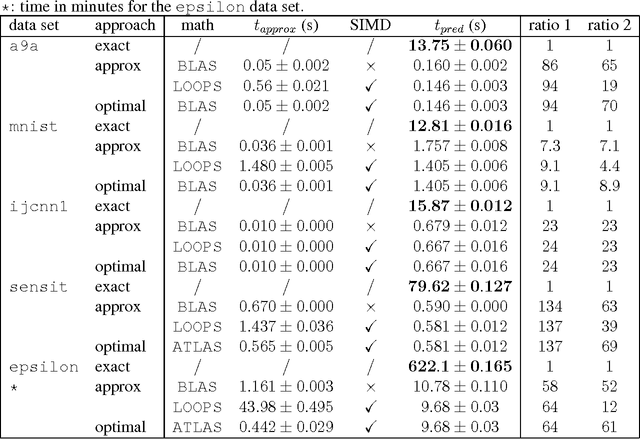
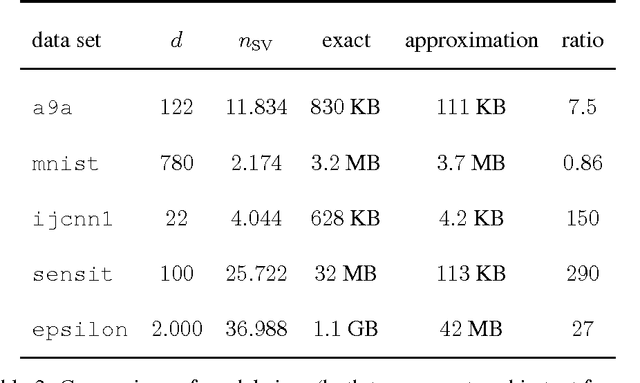
We present an approximation scheme for support vector machine models that use an RBF kernel. A second-order Maclaurin series approximation is used for exponentials of inner products between support vectors and test instances. The approximation is applicable to all kernel methods featuring sums of kernel evaluations and makes no assumptions regarding data normalization. The prediction speed of approximated models no longer relates to the amount of support vectors but is quadratic in terms of the number of input dimensions. If the number of input dimensions is small compared to the amount of support vectors, the approximated model is significantly faster in prediction and has a smaller memory footprint. An optimized C++ implementation was made to assess the gain in prediction speed in a set of practical tests. We additionally provide a method to verify the approximation accuracy, prior to training models or during run-time, to ensure the loss in accuracy remains acceptable and within known bounds.
EnsembleSVM: A Library for Ensemble Learning Using Support Vector Machines
Mar 04, 2014
EnsembleSVM is a free software package containing efficient routines to perform ensemble learning with support vector machine (SVM) base models. It currently offers ensemble methods based on binary SVM models. Our implementation avoids duplicate storage and evaluation of support vectors which are shared between constituent models. Experimental results show that using ensemble approaches can drastically reduce training complexity while maintaining high predictive accuracy. The EnsembleSVM software package is freely available online at http://esat.kuleuven.be/stadius/ensemblesvm.
* 5 pages, 1 table