 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing Performance And Sample Efficiency With Model-agnostic Interactive Feature Attributions
Jun 28, 2023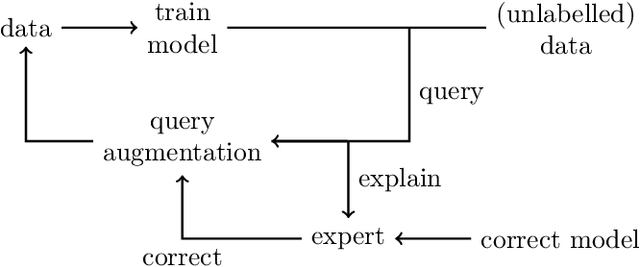
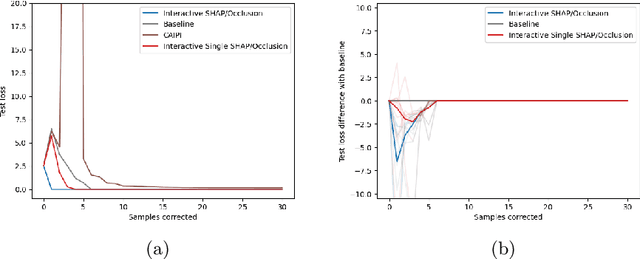
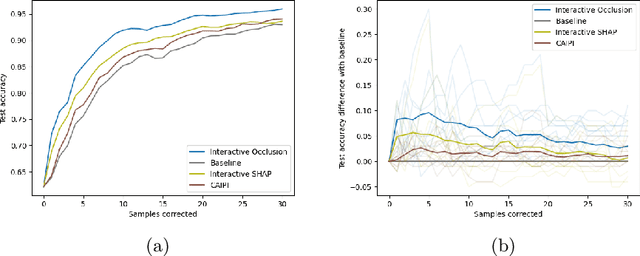
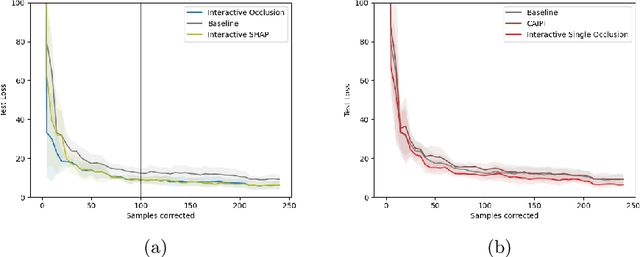
Model-agnostic feature attributions can provide local insights in complex ML models. If the explanation is correct, a domain expert can validate and trust the model's decision. However, if it contradicts the expert's knowledge, related work only corrects irrelevant features to improve the model. To allow for unlimited interaction, in this paper we provide model-agnostic implementations for two popular explanation methods (Occlusion and Shapley values) to enforce entirely different attributions in the complex model. For a particular set of samples, we use the corrected feature attributions to generate extra local data, which is used to retrain the model to have the right explanation for the samples. Through simulated and real data experiments on a variety of models we show how our proposed approach can significantly improve the model's performance only by augmenting its training dataset based on corrected explanations. Adding our interactive explanations to active learning settings increases the sample efficiency significantly and outperforms existing explanatory interactive strategies. Additionally we explore how a domain expert can provide feature attributions which are sufficiently correct to improve the model.
Explaining the Model and Feature Dependencies by Decomposition of the Shapley Value
Jun 19, 2023Shapley values have become one of the go-to methods to explain complex models to end-users. They provide a model agnostic post-hoc explanation with foundations in game theory: what is the worth of a player (in machine learning, a feature value) in the objective function (the output of the complex machine learning model). One downside is that they always require outputs of the model when some features are missing. These are usually computed by taking the expectation over the missing features. This however introduces a non-trivial choice: do we condition on the unknown features or not? In this paper we examine this question and claim that they represent two different explanations which are valid for different end-users: one that explains the model and one that explains the model combined with the feature dependencies in the data. We propose a new algorithmic approach to combine both explanations, removing the burden of choice and enhancing the explanatory power of Shapley values, and show that it achieves intuitive results on simple problems. We apply our method to two real-world datasets and discuss the explanations. Finally, we demonstrate how our method is either equivalent or superior to state-to-of-art Shapley value implementations while simultaneously allowing for increased insight into the model-data structure.