 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-focused learning for optimal PV-Battery scheduling
May 27, 2026The use of residential photovoltaics has increased dramatically in recent years. With battery systems becoming more affordable, the optimal operation of a photovoltaic-battery system can bring significant savings to households. Optimal control requires correct forecasts of underlying parameters, such as photovoltaic power generation, to schedule the battery. While forecasting models have become increasingly accurate due to algorithmic advances and data availability, accuracy is typically measured in generic metrics which might not align with the downstream application. This study proposes a decision-focused learning framework that integrates optimization and prediction by training a Long Short-Term Memory photovoltaic energy forecaster on the downstream optimal scheduling of a battery system. The proposed methodology is compared against a standard two-phase approach. Across a 14-month evaluation period, the decision-focused method reduced average electricity costs across twenty buildings by 3.6% when normalized against performance bounds defined by a perfect forecast and a baseline of no optimization. Critically, this financial improvement was achieved despite the model exhibiting a root mean squared error of 19.9%, significantly higher than the decoupled model's 8.2%. Warm-starting the decision-focused model further improves results, lowering average cost by approximately 8%, while also mitigating the negative impact on statistical accuracy (root mean squared error of 13.7%). The findings are statistically significant at the 0.001 level across the twenty households and for each household individually. These results demonstrate that aligning forecast models with optimization goals is key for achieving cost advantages in PV-battery systems. Future research should replicate these findings on other datasets, alternate forecasting models and alternate optimization algorithms.
Leveraging Asynchronous Cross-border Market Data for Improved Day-Ahead Electricity Price Forecasting in European Markets
Jul 17, 2025Accurate short-term electricity price forecasting is crucial for strategically scheduling demand and generation bids in day-ahead markets. While data-driven techniques have shown considerable prowess in achieving high forecast accuracy in recent years, they rely heavily on the quality of input covariates. In this paper, we investigate whether asynchronously published prices as a result of differing gate closure times (GCTs) in some bidding zones can improve forecasting accuracy in other markets with later GCTs. Using a state-of-the-art ensemble of models, we show significant improvements of 22% and 9% in forecast accuracy in the Belgian (BE) and Swedish bidding zones (SE3) respectively, when including price data from interconnected markets with earlier GCT (Germany-Luxembourg, Austria, and Switzerland). This improvement holds for both general as well as extreme market conditions. Our analysis also yields further important insights: frequent model recalibration is necessary for maximum accuracy but comes at substantial additional computational costs, and using data from more markets does not always lead to better performance - a fact we delve deeper into with interpretability analysis of the forecast models. Overall, these findings provide valuable guidance for market participants and decision-makers aiming to optimize bidding strategies within increasingly interconnected and volatile European energy markets.
Creating synthetic energy meter data using conditional diffusion and building metadata
Mar 31, 2024
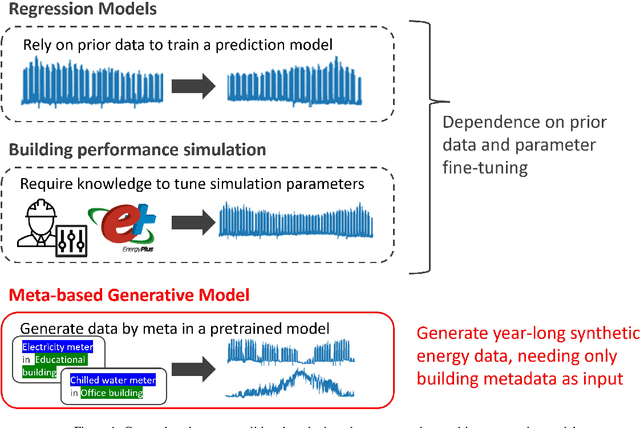
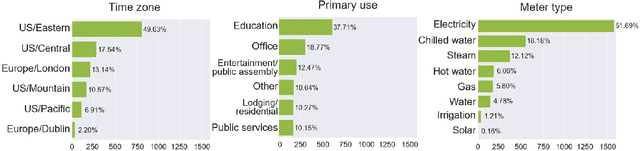
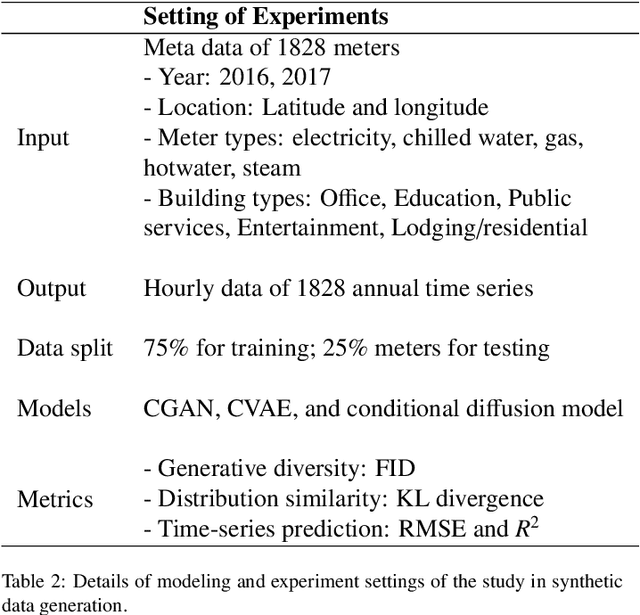
Advances in machine learning and increased computational power have driven progress in energy-related research. However, limited access to private energy data from buildings hinders traditional regression models relying on historical data. While generative models offer a solution, previous studies have primarily focused on short-term generation periods (e.g., daily profiles) and a limited number of meters. Thus, the study proposes a conditional diffusion model for generating high-quality synthetic energy data using relevant metadata. Using a dataset comprising 1,828 power meters from various buildings and countries, this model is compared with traditional methods like Conditional Generative Adversarial Networks (CGAN) and Conditional Variational Auto-Encoders (CVAE). It explicitly handles long-term annual consumption profiles, harnessing metadata such as location, weather, building, and meter type to produce coherent synthetic data that closely resembles real-world energy consumption patterns. The results demonstrate the proposed diffusion model's superior performance, with a 36% reduction in Frechet Inception Distance (FID) score and a 13% decrease in Kullback-Leibler divergence (KL divergence) compared to the following best method. The proposed method successfully generates high-quality energy data through metadata, and its code will be open-sourced, establishing a foundation for a broader array of energy data generation models in the future.
The Forecastability of Underlying Building Electricity Demand from Time Series Data
Nov 29, 2023



Forecasting building energy consumption has become a promising solution in Building Energy Management Systems for energy saving and optimization. Furthermore, it can play an important role in the efficient management of the operation of a smart grid. Different data-driven approaches to forecast the future energy demand of buildings at different scale, and over various time horizons, can be found in the scientific literature, including extensive Machine Learning and Deep Learning approaches. However, the identification of the most accurate forecaster model which can be utilized to predict the energy demand of such a building is still challenging.In this paper, the design and implementation of a data-driven approach to predict how forecastable the future energy demand of a building is, without first utilizing a data-driven forecasting model, is presented. The investigation utilizes a historical electricity consumption time series data set with a half-hour interval that has been collected from a group of residential buildings located in the City of London, United Kingdom
On the contribution of pre-trained models to accuracy and utility in modeling distributed energy resources
Feb 22, 2023
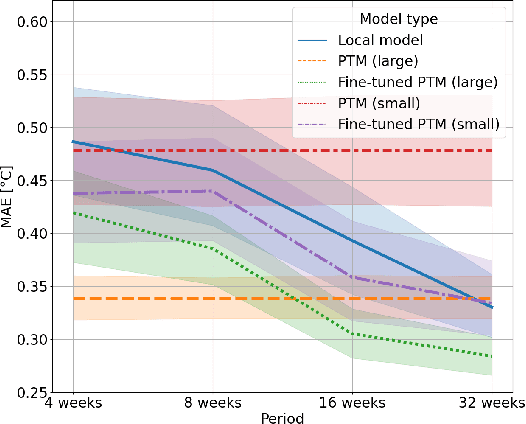

Despite their growing popularity, data-driven models of real-world dynamical systems require lots of data. However, due to sensing limitations as well as privacy concerns, this data is not always available, especially in domains such as energy. Pre-trained models using data gathered in similar contexts have shown enormous potential in addressing these concerns: they can improve predictive accuracy at a much lower observational data expense. Theoretically, due to the risk posed by negative transfer, this improvement is however neither uniform for all agents nor is it guaranteed. In this paper, using data from several distributed energy resources, we investigate and report preliminary findings on several key questions in this regard. First, we evaluate the improvement in predictive accuracy due to pre-trained models, both with and without fine-tuning. Subsequently, we consider the question of fairness: do pre-trained models create equal improvements for heterogeneous agents, and how does this translate to downstream utility? Answering these questions can help enable improvements in the creation, fine-tuning, and adoption of such pre-trained models.
Is your forecaster smarter than an energy engineer: a deep dive into electricity price forecasting
Sep 22, 2022

The field of electricity price forecasting has seen significant advances in the last years, including the development of new, more accurate forecast models. These models leverage statistical relationships in previously observed data to predict the future; however, there is a lack of analysis explaining these models, which limits their real world applicability in critical infrastructure. In this paper, using data from the Belgian electricity markets, we explore a state-of-the-art forecasting model to understand if its predictions can be trusted in more general settings than the limited context it is trained in. If the model produces poor predictions in extreme conditions or if its predictions are inconsistent with reality, it cannot be relied upon in real-world where these forecasts are used in downstream decision-making activities. Our results show that, despite being largely accurate enough in general, even state of the art forecasts struggle with remaining consistent with reality.
Deep Reinforcement Learning for Optimal Control of Space Heating
May 10, 2018



Classical methods to control heating systems are often marred by suboptimal performance, inability to adapt to dynamic conditions and unreasonable assumptions e.g. existence of building models. This paper presents a novel deep reinforcement learning algorithm which can control space heating in buildings in a computationally efficient manner, and benchmarks it against other known techniques. The proposed algorithm outperforms rule based control by between 5-10% in a simulation environment for a number of price signals. We conclude that, while not optimal, the proposed algorithm offers additional practical advantages such as faster computation times and increased robustness to non-stationarities in building dynamics.
Valuing knowledge, information and agency in Multi-agent Reinforcement Learning: a case study in smart buildings
Mar 09, 2018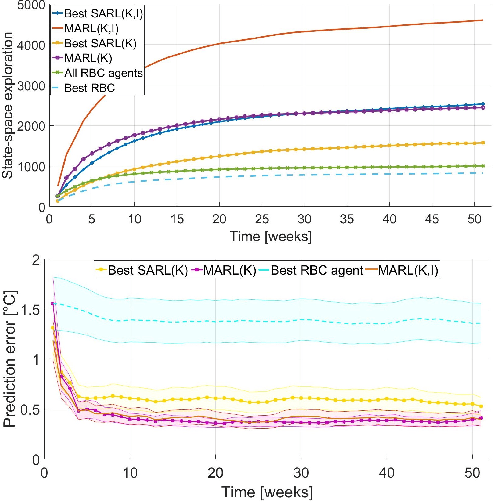
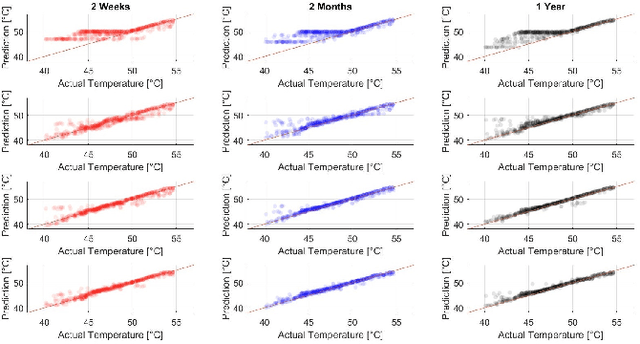
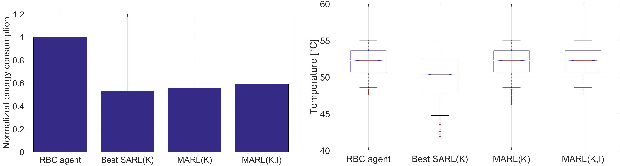
Increasing energy efficiency in buildings can reduce costs and emissions substantially. Historically, this has been treated as a local, or single-agent, optimization problem. However, many buildings utilize the same types of thermal equipment e.g. electric heaters and hot water vessels. During operation, occupants in these buildings interact with the equipment differently thereby driving them to diverse regions in the state-space. Reinforcement learning agents can learn from these interactions, recorded as sensor data, to optimize the overall energy efficiency. However, if these agents operate individually at a household level, they can not exploit the replicated structure in the problem. In this paper, we demonstrate that this problem can indeed benefit from multi-agent collaboration by making use of targeted exploration of the state-space allowing for better generalization. We also investigate trade-offs between integrating human knowledge and additional sensors. Results show that savings of over 40% are possible with collaborative multi-agent systems making use of either expert knowledge or additional sensors with no loss of occupant comfort. We find that such multi-agent systems comfortably outperform comparable single agent systems.
Deep Reinforcement Learning based Optimal Control of Hot Water Systems
Jan 04, 2018



Energy consumption for hot water production is a major draw in high efficiency buildings. Optimizing this has typically been approached from a thermodynamics perspective, decoupled from occupant influence. Furthermore, optimization usually presupposes existence of a detailed dynamics model for the hot water system. These assumptions lead to suboptimal energy efficiency in the real world. In this paper, we present a novel reinforcement learning based methodology which optimizes hot water production. The proposed methodology is completely generalizable, and does not require an offline step or human domain knowledge to build a model for the hot water vessel or the heating element. Occupant preferences too are learnt on the fly. The proposed system is applied to a set of 32 houses in the Netherlands where it reduces energy consumption for hot water production by roughly 20% with no loss of occupant comfort. Extrapolating, this translates to absolute savings of roughly 200 kWh for a single household on an annual basis. This performance can be replicated to any domestic hot water system and optimization objective, given that the fairly minimal requirements on sensor data are met. With millions of hot water systems operational worldwide, the proposed framework has the potential to reduce energy consumption in existing and new systems on a multi Gigawatt-hour scale in the years to come.