 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating synthetic energy meter data using conditional diffusion and building metadata
Mar 31, 2024
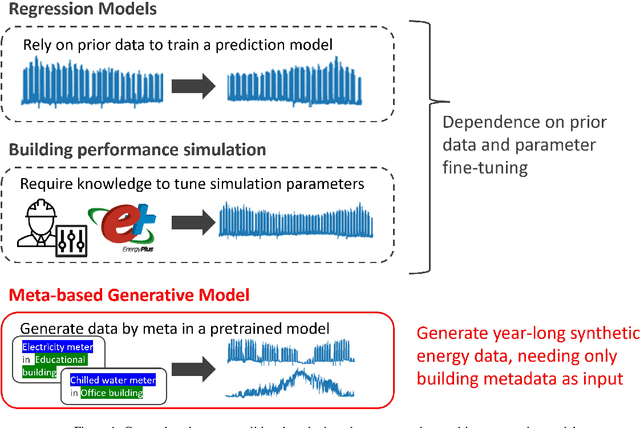
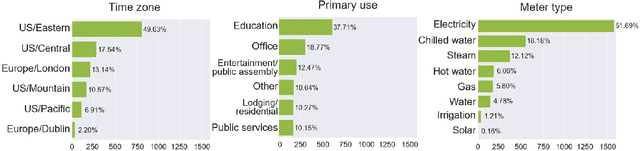
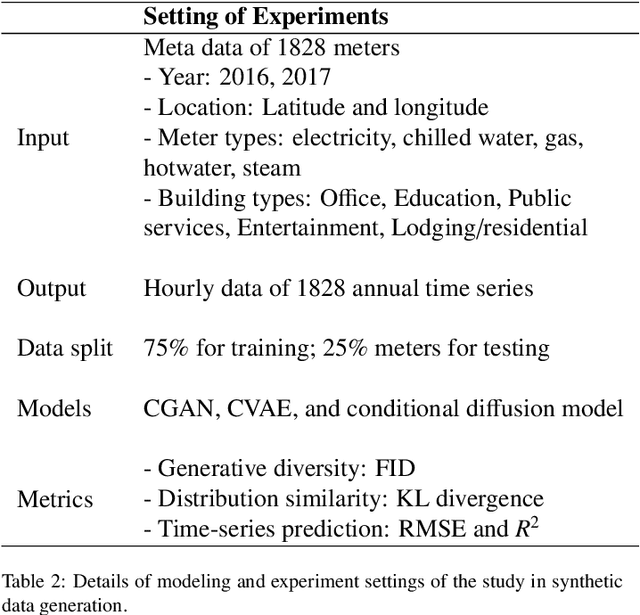
Advances in machine learning and increased computational power have driven progress in energy-related research. However, limited access to private energy data from buildings hinders traditional regression models relying on historical data. While generative models offer a solution, previous studies have primarily focused on short-term generation periods (e.g., daily profiles) and a limited number of meters. Thus, the study proposes a conditional diffusion model for generating high-quality synthetic energy data using relevant metadata. Using a dataset comprising 1,828 power meters from various buildings and countries, this model is compared with traditional methods like Conditional Generative Adversarial Networks (CGAN) and Conditional Variational Auto-Encoders (CVAE). It explicitly handles long-term annual consumption profiles, harnessing metadata such as location, weather, building, and meter type to produce coherent synthetic data that closely resembles real-world energy consumption patterns. The results demonstrate the proposed diffusion model's superior performance, with a 36% reduction in Frechet Inception Distance (FID) score and a 13% decrease in Kullback-Leibler divergence (KL divergence) compared to the following best method. The proposed method successfully generates high-quality energy data through metadata, and its code will be open-sourced, establishing a foundation for a broader array of energy data generation models in the future.
Opening the Black Box: Towards inherently interpretable energy data imputation models using building physics insight
Nov 28, 2023Missing data are frequently observed by practitioners and researchers in the building energy modeling community. In this regard, advanced data-driven solutions, such as Deep Learning methods, are typically required to reflect the non-linear behavior of these anomalies. As an ongoing research question related to Deep Learning, a model's applicability to limited data settings can be explored by introducing prior knowledge in the network. This same strategy can also lead to more interpretable predictions, hence facilitating the field application of the approach. For that purpose, the aim of this paper is to propose the use of Physics-informed Denoising Autoencoders (PI-DAE) for missing data imputation in commercial buildings. In particular, the presented method enforces physics-inspired soft constraints to the loss function of a Denoising Autoencoder (DAE). In order to quantify the benefits of the physical component, an ablation study between different DAE configurations is conducted. First, three univariate DAEs are optimized separately on indoor air temperature, heating, and cooling data. Then, two multivariate DAEs are derived from the previous configurations. Eventually, a building thermal balance equation is coupled to the last multivariate configuration to obtain PI-DAE. Additionally, two commonly used benchmarks are employed to support the findings. It is shown how introducing physical knowledge in a multivariate Denoising Autoencoder can enhance the inherent model interpretability through the optimized physics-based coefficients. While no significant improvement is observed in terms of reconstruction error with the proposed PI-DAE, its enhanced robustness to varying rates of missing data and the valuable insights derived from the physics-based coefficients create opportunities for wider applications within building systems and the built environment.
Filling time-series gaps using image techniques: Multidimensional context autoencoder approach for building energy data imputation
Jul 13, 2023Building energy prediction and management has become increasingly important in recent decades, driven by the growth of Internet of Things (IoT) devices and the availability of more energy data. However, energy data is often collected from multiple sources and can be incomplete or inconsistent, which can hinder accurate predictions and management of energy systems and limit the usefulness of the data for decision-making and research. To address this issue, past studies have focused on imputing missing gaps in energy data, including random and continuous gaps. One of the main challenges in this area is the lack of validation on a benchmark dataset with various building and meter types, making it difficult to accurately evaluate the performance of different imputation methods. Another challenge is the lack of application of state-of-the-art imputation methods for missing gaps in energy data. Contemporary image-inpainting methods, such as Partial Convolution (PConv), have been widely used in the computer vision domain and have demonstrated their effectiveness in dealing with complex missing patterns. To study whether energy data imputation can benefit from the image-based deep learning method, this study compared PConv, Convolutional neural networks (CNNs), and weekly persistence method using one of the biggest publicly available whole building energy datasets, consisting of 1479 power meters worldwide, as the benchmark. The results show that, compared to the CNN with the raw time series (1D-CNN) and the weekly persistence method, neural network models with reshaped energy data with two dimensions reduced the Mean Squared Error (MSE) by 10% to 30%. The advanced deep learning method, Partial convolution (PConv), has further reduced the MSE by 20-30% than 2D-CNN and stands out among all models.
Gradient boosting machines and careful pre-processing work best: ASHRAE Great Energy Predictor III lessons learned
Feb 07, 2022
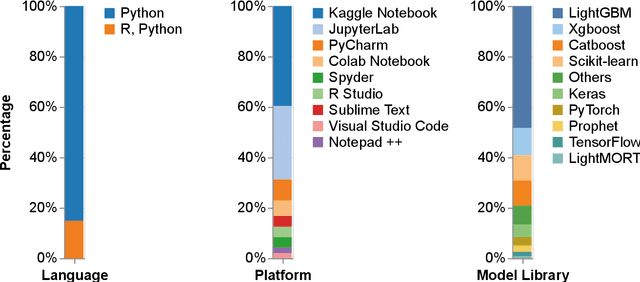
The ASHRAE Great Energy Predictor III (GEPIII) competition was held in late 2019 as one of the largest machine learning competitions ever held focused on building performance. It was hosted on the Kaggle platform and resulted in 39,402 prediction submissions, with the top five teams splitting $25,000 in prize money. This paper outlines lessons learned from participants, mainly from teams who scored in the top 5% of the competition. Various insights were gained from their experience through an online survey, analysis of publicly shared submissions and notebooks, and the documentation of the winning teams. The top-performing solutions mostly used ensembles of Gradient Boosting Machine (GBM) tree-based models, with the LightGBM package being the most popular. The survey participants indicated that the preprocessing and feature extraction phases were the most important aspects of creating the best modeling approach. All the survey respondents used Python as their primary modeling tool, and it was common to use Jupyter-style Notebooks as development environments. These conclusions are essential to help steer the research and practical implementation of building energy meter prediction in the future.
Using Google Trends as a proxy for occupant behavior to predict building energy consumption
Oct 31, 2021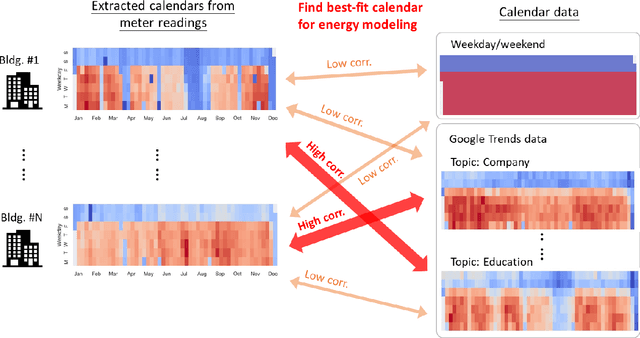
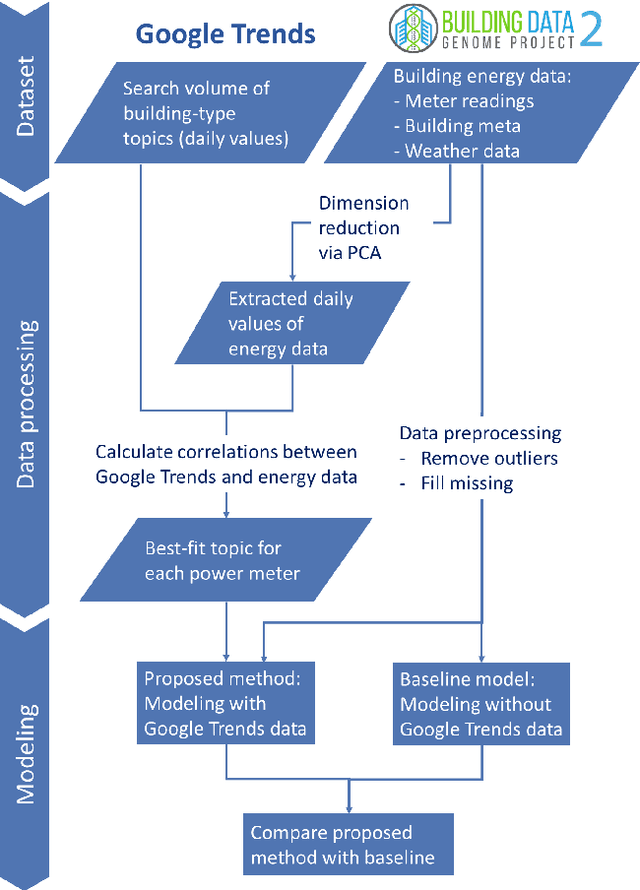

In recent years, the availability of larger amounts of energy data and advanced machine learning algorithms has created a surge in building energy prediction research. However, one of the variables in energy prediction models, occupant behavior, is crucial for prediction performance but hard-to-measure or time-consuming to collect from each building. This study proposes an approach that utilizes the search volume of topics (e.g., education} or Microsoft Excel) on the Google Trends platform as a proxy of occupant behavior and use of buildings. Linear correlations were first examined to explore the relationship between energy meter data and Google Trends search terms to infer building occupancy. Prediction errors before and after the inclusion of the trends of these terms were compared and analyzed based on the ASHRAE Great Energy Predictor III (GEPIII) competition dataset. The results show that highly correlated Google Trends data can effectively reduce the overall RMSLE error for a subset of the buildings to the level of the GEPIII competition's top five winning teams' performance. In particular, the RMSLE error reduction during public holidays and days with site-specific schedules are respectively reduced by 20-30% and 2-5%. These results show the potential of using Google Trends to improve energy prediction for a portion of the building stock by automatically identifying site-specific and holiday schedules.
Limitations of machine learning for building energy prediction: ASHRAE Great Energy Predictor III Kaggle competition error analysis
Jun 25, 2021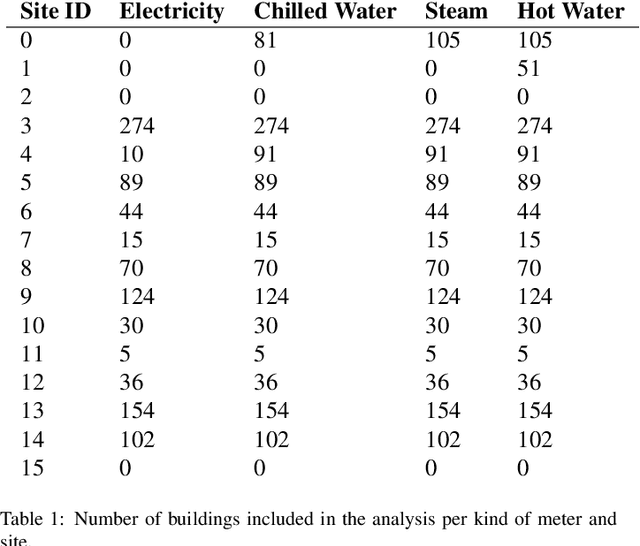

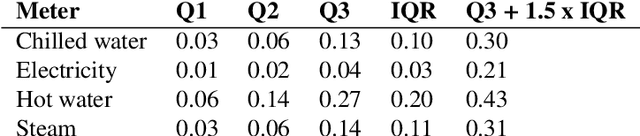

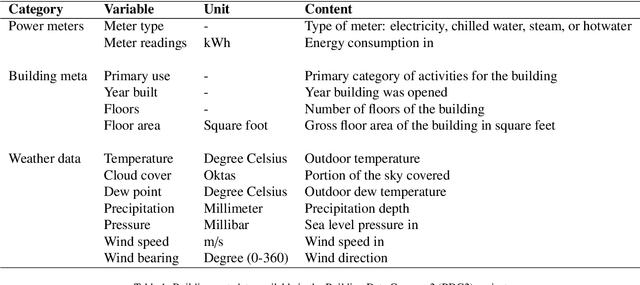
Machine learning for building energy prediction has exploded in popularity in recent years, yet understanding its limitations and potential for improvement are lacking. The ASHRAE Great Energy Predictor III (GEPIII) Kaggle competition was the largest building energy meter machine learning competition ever held with 4,370 participants who submitted 39,403 predictions. The test data set included two years of hourly electricity, hot water, chilled water, and steam readings from 2,380 meters in 1,448 buildings at 16 locations. This paper analyzes the various sources and types of residual model error from an aggregation of the competition's top 50 solutions. This analysis reveals the limitations for machine learning using the standard model inputs of historical meter, weather, and basic building metadata. The types of error are classified according to the amount of time errors occur in each instance, abrupt versus gradual behavior, the magnitude of error, and whether the error existed on single buildings or several buildings at once from a single location. The results show machine learning models have errors within a range of acceptability on 79.1% of the test data. Lower magnitude model errors occur in 16.1% of the test data. These discrepancies can likely be addressed through additional training data sources or innovations in machine learning. Higher magnitude errors occur in 4.8% of the test data and are unlikely to be accurately predicted regardless of innovation. There is a diversity of error behavior depending on the energy meter type (electricity prediction models have unacceptable error in under 10% of test data, while hot water is over 60%) and building use type (public service less than 14%, while technology/science is just over 46%).