 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the contribution of pre-trained models to accuracy and utility in modeling distributed energy resources
Paper and Code
Feb 22, 2023
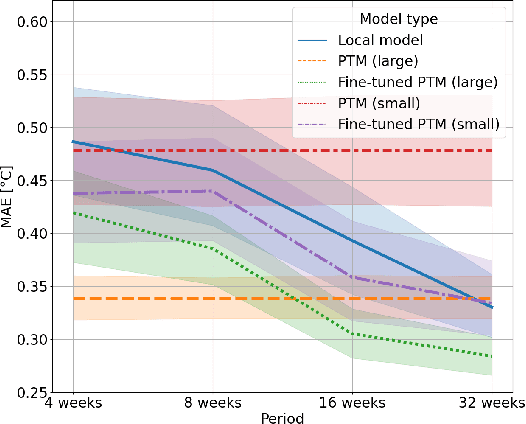

Despite their growing popularity, data-driven models of real-world dynamical systems require lots of data. However, due to sensing limitations as well as privacy concerns, this data is not always available, especially in domains such as energy. Pre-trained models using data gathered in similar contexts have shown enormous potential in addressing these concerns: they can improve predictive accuracy at a much lower observational data expense. Theoretically, due to the risk posed by negative transfer, this improvement is however neither uniform for all agents nor is it guaranteed. In this paper, using data from several distributed energy resources, we investigate and report preliminary findings on several key questions in this regard. First, we evaluate the improvement in predictive accuracy due to pre-trained models, both with and without fine-tuning. Subsequently, we consider the question of fairness: do pre-trained models create equal improvements for heterogeneous agents, and how does this translate to downstream utility? Answering these questions can help enable improvements in the creation, fine-tuning, and adoption of such pre-trained models.