 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue-oriented forecast reconciliation for renewables in electricity markets
Jan 27, 2025Forecast reconciliation is considered an effective method for achieving coherence and improving forecast accuracy. However, the value of reconciled forecasts in downstream decision-making tasks has been mostly overlooked. In a multi-agent setup with heterogeneous loss functions, this oversight may lead to unfair outcomes, hence resulting in conflicts during the reconciliation process. To address this, we propose a value-oriented forecast reconciliation approach that focuses on the forecast value for individual agents. Fairness is ensured through the use of a Nash bargaining framework. Specifically, we model this problem as a cooperative bargaining game, where each agent aims to optimize their own gain while contributing to the overall reconciliation process. We then present a primal-dual algorithm for parameter estimation based on empirical risk minimization. From an application perspective, we consider an aggregated wind energy trading problem, where profits are distributed using a weighted allocation rule. We demonstrate the effectiveness of our approach through several numerical experiments, showing that it consistently results in increased profits for all agents involved.
Evolving Multi-Scale Normalization for Time Series Forecasting under Distribution Shifts
Sep 29, 2024



Complex distribution shifts are the main obstacle to achieving accurate long-term time series forecasting. Several efforts have been conducted to capture the distribution characteristics and propose adaptive normalization techniques to alleviate the influence of distribution shifts. However, these methods neglect the intricate distribution dynamics observed from various scales and the evolving functions of distribution dynamics and normalized mapping relationships. To this end, we propose a novel model-agnostic Evolving Multi-Scale Normalization (EvoMSN) framework to tackle the distribution shift problem. Flexible normalization and denormalization are proposed based on the multi-scale statistics prediction module and adaptive ensembling. An evolving optimization strategy is designed to update the forecasting model and statistics prediction module collaboratively to track the shifting distributions. We evaluate the effectiveness of EvoMSN in improving the performance of five mainstream forecasting methods on benchmark datasets and also show its superiority compared to existing advanced normalization and online learning approaches. The code is publicly available at https://github.com/qindalin/EvoMSN.
Data is missing again -- Reconstruction of power generation data using $k$-Nearest Neighbors and spectral graph theory
Aug 30, 2024
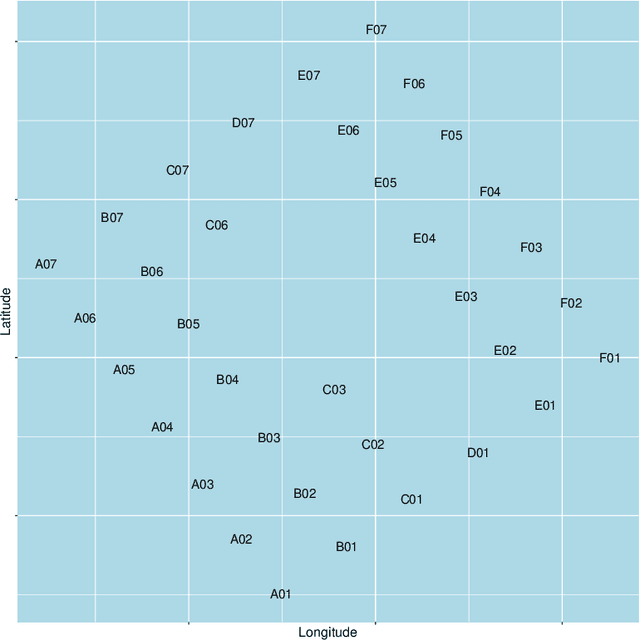


The risk of missing data and subsequent incomplete data records at wind farms increases with the number of turbines and sensors. We propose here an imputation method that blends data-driven concepts with expert knowledge, by using the geometry of the wind farm in order to provide better estimates when performing Nearest Neighbor imputation. Our method relies on learning Laplacian eigenmaps out of the graph of the wind farm through spectral graph theory. These learned representations can be based on the wind farm layout only, or additionally account for information provided by collected data. The related weighted graph is allowed to change with time and can be tracked in an online fashion. Application to the Westermost Rough offshore wind farm shows significant improvement over approaches that do not account for the wind farm layout information.
Clustering of timed sequences -- Application to the analysis of care pathways
Apr 23, 2024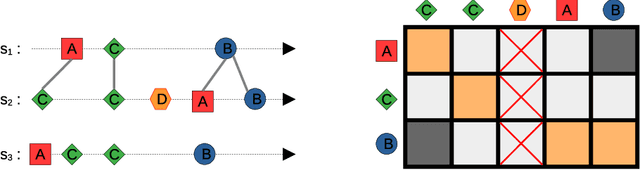

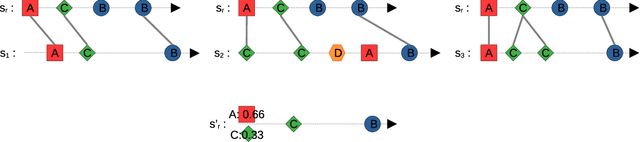

Improving the future of healthcare starts by better understanding the current actual practices in hospitals. This motivates the objective of discovering typical care pathways from patient data. Revealing homogeneous groups of care pathways can be achieved through clustering. The difficulty in clustering care pathways, represented by sequences of timestamped events, lies in defining a semantically appropriate metric and clustering algorithms. In this article, we adapt two methods developed for time series to time sequences: the drop-DTW metric and the DBA approach for the construction of averaged time sequences. These methods are then applied in clustering algorithms to propose original and sound clustering algorithms for timed sequences. This approach is experimented with and evaluated on synthetic and real use cases.
Tackling Missing Values in Probabilistic Wind Power Forecasting: A Generative Approach
Mar 06, 2024Machine learning techniques have been successfully used in probabilistic wind power forecasting. However, the issue of missing values within datasets due to sensor failure, for instance, has been overlooked for a long time. Although it is natural to consider addressing this issue by imputing missing values before model estimation and forecasting, we suggest treating missing values and forecasting targets indifferently and predicting all unknown values simultaneously based on observations. In this paper, we offer an efficient probabilistic forecasting approach by estimating the joint distribution of features and targets based on a generative model. It is free of preprocessing, and thus avoids introducing potential errors. Compared with the traditional "impute, then predict" pipeline, the proposed approach achieves better performance in terms of continuous ranked probability score.
Seamless and multi-resolution energy forecasting
Dec 28, 2023



Energy forecasting is pivotal in energy systems, by providing fundamentals for operation, with different horizons and resolutions. Though energy forecasting has been widely studied for capturing temporal information, very few works concentrate on the frequency information provided by forecasts. They are consequently often limited to single-resolution applications (e.g., hourly). Here, we propose a unified energy forecasting framework based on Laplace transform in the multi-resolution context. The forecasts can be seamlessly produced at different desired resolutions without re-training or post-processing. Case studies on both energy demand and supply data show that the forecasts from our proposed method can provide accurate information in both time and frequency domains. Across the resolutions, the forecasts also demonstrate high consistency. More importantly, we explore the operational effects of our produced forecasts in the day-ahead and intra-day energy scheduling. The relationship between (i) errors in both time and frequency domains and (ii) operational value of the forecasts is analysed. Significant operational benefits are obtained.
Privacy-Aware Data Acquisition under Data Similarity in Regression Markets
Dec 05, 2023Data markets facilitate decentralized data exchange for applications such as prediction, learning, or inference. The design of these markets is challenged by varying privacy preferences as well as data similarity among data owners. Related works have often overlooked how data similarity impacts pricing and data value through statistical information leakage. We demonstrate that data similarity and privacy preferences are integral to market design and propose a query-response protocol using local differential privacy for a two-party data acquisition mechanism. In our regression data market model, we analyze strategic interactions between privacy-aware owners and the learner as a Stackelberg game over the asked price and privacy factor. Finally, we numerically evaluate how data similarity affects market participation and traded data value.
Bayesian Regression Markets
Oct 23, 2023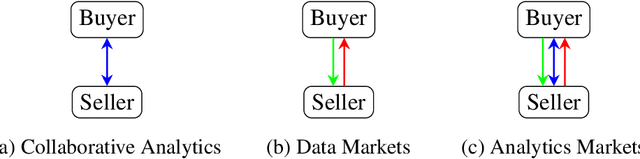
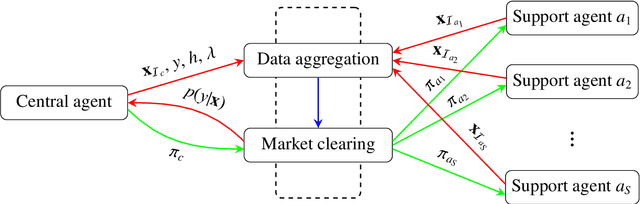
Machine learning tasks are vulnerable to the quality of data used as input. Yet, it is often challenging for firms to obtain adequate datasets, with them being naturally distributed amongst owners, that in practice, may be competitors in a downstream market and reluctant to share information. Focusing on supervised learning for regression tasks, we develop a \textit{regression market} to provide a monetary incentive for data sharing. Our proposed mechanism adopts a Bayesian framework, allowing us to consider a more general class of regression tasks. We present a thorough exploration of the market properties, and show that similar proposals in current literature expose the market agents to sizeable financial risks, which can be mitigated in our probabilistic setting.
On tracking varying bounds when forecasting bounded time series
Jun 23, 2023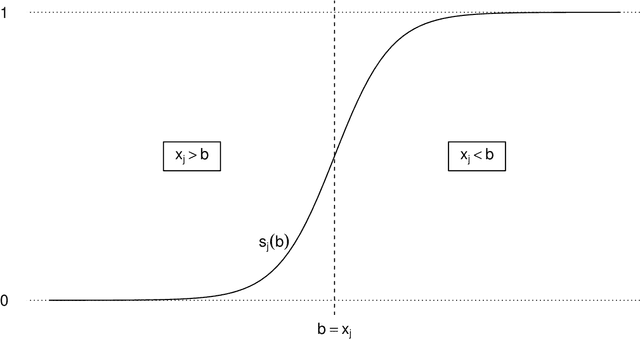



We consider a new framework where a continuous, though bounded, random variable has unobserved bounds that vary over time. In the context of univariate time series, we look at the bounds as parameters of the distribution of the bounded random variable. We introduce an extended log-likelihood estimation and design algorithms to track the bound through online maximum likelihood estimation. Since the resulting optimization problem is not convex, we make use of recent theoretical results on Normalized Gradient Descent (NGD) for quasiconvex optimization, to eventually derive an Online Normalized Gradient Descent algorithm. We illustrate and discuss the workings of our approach based on both simulation studies and a real-world wind power forecasting problem.
On the contribution of pre-trained models to accuracy and utility in modeling distributed energy resources
Feb 22, 2023
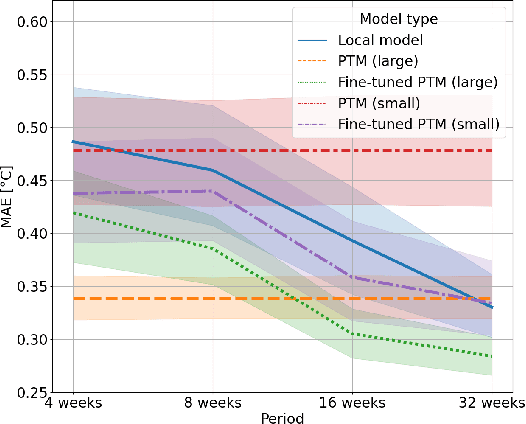

Despite their growing popularity, data-driven models of real-world dynamical systems require lots of data. However, due to sensing limitations as well as privacy concerns, this data is not always available, especially in domains such as energy. Pre-trained models using data gathered in similar contexts have shown enormous potential in addressing these concerns: they can improve predictive accuracy at a much lower observational data expense. Theoretically, due to the risk posed by negative transfer, this improvement is however neither uniform for all agents nor is it guaranteed. In this paper, using data from several distributed energy resources, we investigate and report preliminary findings on several key questions in this regard. First, we evaluate the improvement in predictive accuracy due to pre-trained models, both with and without fine-tuning. Subsequently, we consider the question of fairness: do pre-trained models create equal improvements for heterogeneous agents, and how does this translate to downstream utility? Answering these questions can help enable improvements in the creation, fine-tuning, and adoption of such pre-trained models.