 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHonkaiChat: Companions from Anime that feel alive!
Jan 05, 2025


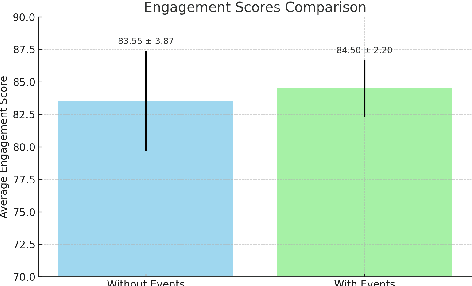
Modern conversational agents, including anime-themed chatbots, are frequently reactive and personality-driven but fail to capture the dynamic nature of human interactions. We propose an event-driven dialogue framework to address these limitations by embedding dynamic events in conversation prompts and fine-tuning models on character-specific data. Evaluations on GPT-4 and comparisons with industry-leading baselines demonstrate that event-driven prompts significantly improve conversational engagement and naturalness while reducing hallucinations. This paper explores the application of this approach in creating lifelike chatbot interactions within the context of Honkai: Star Rail, showcasing the potential for dynamic event-based systems to transform role-playing and interactive dialogue.
Evolving Multi-Scale Normalization for Time Series Forecasting under Distribution Shifts
Sep 29, 2024



Complex distribution shifts are the main obstacle to achieving accurate long-term time series forecasting. Several efforts have been conducted to capture the distribution characteristics and propose adaptive normalization techniques to alleviate the influence of distribution shifts. However, these methods neglect the intricate distribution dynamics observed from various scales and the evolving functions of distribution dynamics and normalized mapping relationships. To this end, we propose a novel model-agnostic Evolving Multi-Scale Normalization (EvoMSN) framework to tackle the distribution shift problem. Flexible normalization and denormalization are proposed based on the multi-scale statistics prediction module and adaptive ensembling. An evolving optimization strategy is designed to update the forecasting model and statistics prediction module collaboratively to track the shifting distributions. We evaluate the effectiveness of EvoMSN in improving the performance of five mainstream forecasting methods on benchmark datasets and also show its superiority compared to existing advanced normalization and online learning approaches. The code is publicly available at https://github.com/qindalin/EvoMSN.
Addressing Concept Shift in Online Time Series Forecasting: Detect-then-Adapt
Mar 22, 2024



Online updating of time series forecasting models aims to tackle the challenge of concept drifting by adjusting forecasting models based on streaming data. While numerous algorithms have been developed, most of them focus on model design and updating. In practice, many of these methods struggle with continuous performance regression in the face of accumulated concept drifts over time. To address this limitation, we present a novel approach, Concept \textbf{D}rift \textbf{D}etection an\textbf{D} \textbf{A}daptation (D3A), that first detects drifting conception and then aggressively adapts the current model to the drifted concepts after the detection for rapid adaption. To best harness the utility of historical data for model adaptation, we propose a data augmentation strategy introducing Gaussian noise into existing training instances. It helps mitigate the data distribution gap, a critical factor contributing to train-test performance inconsistency. The significance of our data augmentation process is verified by our theoretical analysis. Our empirical studies across six datasets demonstrate the effectiveness of D3A in improving model adaptation capability. Notably, compared to a simple Temporal Convolutional Network (TCN) baseline, D3A reduces the average Mean Squared Error (MSE) by $43.9\%$. For the state-of-the-art (SOTA) model, the MSE is reduced by $33.3\%$.
Effectiveness of Optimization Algorithms in Deep Image Classification
Oct 04, 2021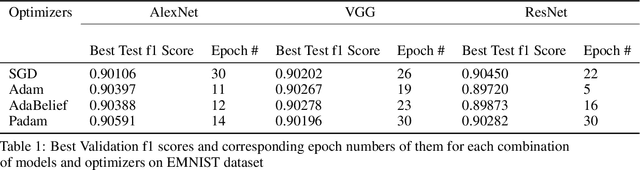
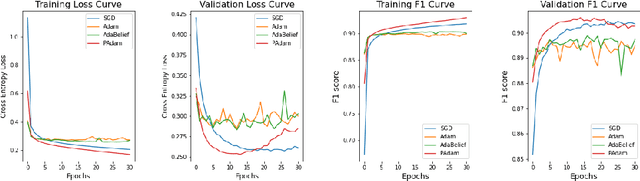
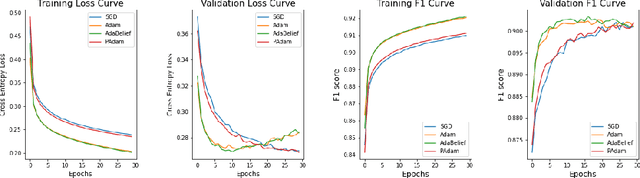
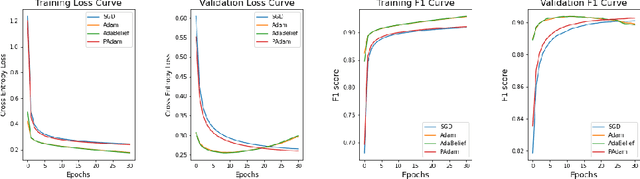
Adam is applied widely to train neural networks. Different kinds of Adam methods with different features pop out. Recently two new adam optimizers, AdaBelief and Padam are introduced among the community. We analyze these two adam optimizers and compare them with other conventional optimizers (Adam, SGD + Momentum) in the scenario of image classification. We evaluate the performance of these optimization algorithms on AlexNet and simplified versions of VGGNet, ResNet using the EMNIST dataset. (Benchmark algorithm is available at \hyperref[https://github.com/chuiyunjun/projectCSC413]{https://github.com/chuiyunjun/projectCSC413}).