 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSC-180: A Benchmark for Automated Formal Theorem Proving from Mathematical Subject Classification
Dec 20, 2025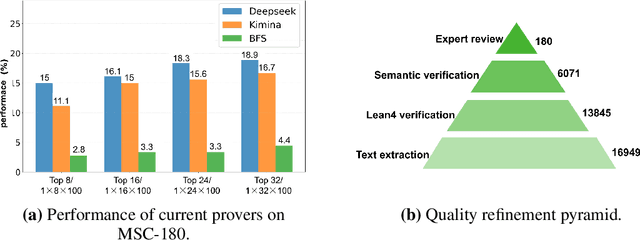



Automated Theorem Proving (ATP) represents a core research direction in artificial intelligence for achieving formal reasoning and verification, playing a significant role in advancing machine intelligence. However, current large language model (LLM)-based theorem provers suffer from limitations such as restricted domain coverage and weak generalization in mathematical reasoning. To address these issues, we propose MSC-180, a benchmark for evaluation based on the MSC2020 mathematical subject classification. It comprises 180 formal verification problems, 3 advanced problems from each of 60 mathematical branches, spanning from undergraduate to graduate levels. Each problem has undergone multiple rounds of verification and refinement by domain experts to ensure formal accuracy. Evaluations of state-of-the-art LLM-based theorem provers under the pass@32 setting reveal that the best model achieves only an 18.89% overall pass rate, with prominent issues including significant domain bias (maximum domain coverage 41.7%) and a difficulty gap (significantly lower pass rates on graduate-level problems). To further quantify performance variability across mathematical domains, we introduce the coefficient of variation (CV) as an evaluation metric. The observed CV values are 4-6 times higher than the statistical high-variability threshold, indicating that the models still rely on pattern matching from training corpora rather than possessing transferable reasoning mechanisms and systematic generalization capabilities. MSC-180, together with its multi-dimensional evaluation framework, provides a discriminative and systematic benchmark for driving the development of next-generation AI systems with genuine mathematical reasoning abilities.
Automated Formalization via Conceptual Retrieval-Augmented LLMs
Aug 09, 2025



Interactive theorem provers (ITPs) require manual formalization, which is labor-intensive and demands expert knowledge. While automated formalization offers a potential solution, it faces two major challenges: model hallucination (e.g., undefined predicates, symbol misuse, and version incompatibility) and the semantic gap caused by ambiguous or missing premises in natural language descriptions. To address these issues, we propose CRAMF, a Concept-driven Retrieval-Augmented Mathematical Formalization framework. CRAMF enhances LLM-based autoformalization by retrieving formal definitions of core mathematical concepts, providing contextual grounding during code generation. However, applying retrieval-augmented generation (RAG) in this setting is non-trivial due to the lack of structured knowledge bases, the polymorphic nature of mathematical concepts, and the high precision required in formal retrieval. We introduce a framework for automatically constructing a concept-definition knowledge base from Mathlib4, the standard mathematical library for the Lean 4 theorem prover, indexing over 26,000 formal definitions and 1,000+ core mathematical concepts. To address conceptual polymorphism, we propose contextual query augmentation with domain- and application-level signals. In addition, we design a dual-channel hybrid retrieval strategy with reranking to ensure accurate and relevant definition retrieval. Experiments on miniF2F, ProofNet, and our newly proposed AdvancedMath benchmark show that CRAMF can be seamlessly integrated into LLM-based autoformalizers, yielding consistent improvements in translation accuracy, achieving up to 62.1% and an average of 29.9% relative improvement.
Autoformalization in the Era of Large Language Models: A Survey
May 29, 2025Autoformalization, the process of transforming informal mathematical propositions into verifiable formal representations, is a foundational task in automated theorem proving, offering a new perspective on the use of mathematics in both theoretical and applied domains. Driven by the rapid progress in artificial intelligence, particularly large language models (LLMs), this field has witnessed substantial growth, bringing both new opportunities and unique challenges. In this survey, we provide a comprehensive overview of recent advances in autoformalization from both mathematical and LLM-centric perspectives. We examine how autoformalization is applied across various mathematical domains and levels of difficulty, and analyze the end-to-end workflow from data preprocessing to model design and evaluation. We further explore the emerging role of autoformalization in enhancing the verifiability of LLM-generated outputs, highlighting its potential to improve both the trustworthiness and reasoning capabilities of LLMs. Finally, we summarize key open-source models and datasets supporting current research, and discuss open challenges and promising future directions for the field.
RRR-Net: Reusing, Reducing, and Recycling a Deep Backbone Network
Oct 02, 2023



It has become mainstream in computer vision and other machine learning domains to reuse backbone networks pre-trained on large datasets as preprocessors. Typically, the last layer is replaced by a shallow learning machine of sorts; the newly-added classification head and (optionally) deeper layers are fine-tuned on a new task. Due to its strong performance and simplicity, a common pre-trained backbone network is ResNet152.However, ResNet152 is relatively large and induces inference latency. In many cases, a compact and efficient backbone with similar performance would be preferable over a larger, slower one. This paper investigates techniques to reuse a pre-trained backbone with the objective of creating a smaller and faster model. Starting from a large ResNet152 backbone pre-trained on ImageNet, we first reduce it from 51 blocks to 5 blocks, reducing its number of parameters and FLOPs by more than 6 times, without significant performance degradation. Then, we split the model after 3 blocks into several branches, while preserving the same number of parameters and FLOPs, to create an ensemble of sub-networks to improve performance. Our experiments on a large benchmark of $40$ image classification datasets from various domains suggest that our techniques match the performance (if not better) of ``classical backbone fine-tuning'' while achieving a smaller model size and faster inference speed.
Modularity in Deep Learning: A Survey
Oct 02, 2023Modularity is a general principle present in many fields. It offers attractive advantages, including, among others, ease of conceptualization, interpretability, scalability, module combinability, and module reusability. The deep learning community has long sought to take inspiration from the modularity principle, either implicitly or explicitly. This interest has been increasing over recent years. We review the notion of modularity in deep learning around three axes: data, task, and model, which characterize the life cycle of deep learning. Data modularity refers to the observation or creation of data groups for various purposes. Task modularity refers to the decomposition of tasks into sub-tasks. Model modularity means that the architecture of a neural network system can be decomposed into identifiable modules. We describe different instantiations of the modularity principle, and we contextualize their advantages in different deep learning sub-fields. Finally, we conclude the paper with a discussion of the definition of modularity and directions for future research.
Meta-Album: Multi-domain Meta-Dataset for Few-Shot Image Classification
Feb 16, 2023We introduce Meta-Album, an image classification meta-dataset designed to facilitate few-shot learning, transfer learning, meta-learning, among other tasks. It includes 40 open datasets, each having at least 20 classes with 40 examples per class, with verified licences. They stem from diverse domains, such as ecology (fauna and flora), manufacturing (textures, vehicles), human actions, and optical character recognition, featuring various image scales (microscopic, human scales, remote sensing). All datasets are preprocessed, annotated, and formatted uniformly, and come in 3 versions (Micro $\subset$ Mini $\subset$ Extended) to match users' computational resources. We showcase the utility of the first 30 datasets on few-shot learning problems. The other 10 will be released shortly after. Meta-Album is already more diverse and larger (in number of datasets) than similar efforts, and we are committed to keep enlarging it via a series of competitions. As competitions terminate, their test data are released, thus creating a rolling benchmark, available through OpenML.org. Our website https://meta-album.github.io/ contains the source code of challenge winning methods, baseline methods, data loaders, and instructions for contributing either new datasets or algorithms to our expandable meta-dataset.
LTU Attacker for Membership Inference
Feb 04, 2022
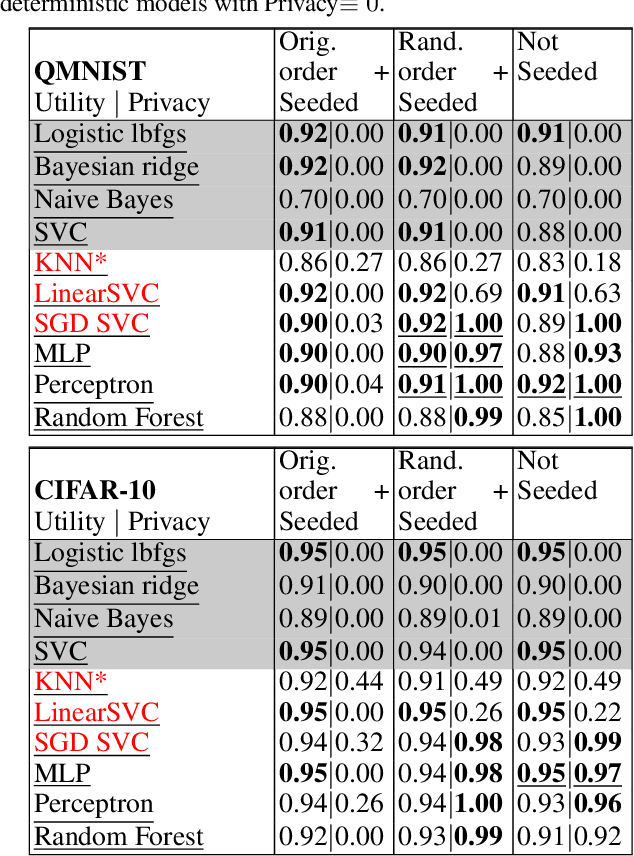


We address the problem of defending predictive models, such as machine learning classifiers (Defender models), against membership inference attacks, in both the black-box and white-box setting, when the trainer and the trained model are publicly released. The Defender aims at optimizing a dual objective: utility and privacy. Both utility and privacy are evaluated with an external apparatus including an Attacker and an Evaluator. On one hand, Reserved data, distributed similarly to the Defender training data, is used to evaluate Utility; on the other hand, Reserved data, mixed with Defender training data, is used to evaluate membership inference attack robustness. In both cases classification accuracy or error rate are used as the metric: Utility is evaluated with the classification accuracy of the Defender model; Privacy is evaluated with the membership prediction error of a so-called "Leave-Two-Unlabeled" LTU Attacker, having access to all of the Defender and Reserved data, except for the membership label of one sample from each. We prove that, under certain conditions, even a "na\"ive" LTU Attacker can achieve lower bounds on privacy loss with simple attack strategies, leading to concrete necessary conditions to protect privacy, including: preventing over-fitting and adding some amount of randomness. However, we also show that such a na\"ive LTU Attacker can fail to attack the privacy of models known to be vulnerable in the literature, demonstrating that knowledge must be complemented with strong attack strategies to turn the LTU Attacker into a powerful means of evaluating privacy. Our experiments on the QMNIST and CIFAR-10 datasets validate our theoretical results and confirm the roles of over-fitting prevention and randomness in the algorithms to protect against privacy attacks.
OmniPrint: A Configurable Printed Character Synthesizer
Jan 17, 2022

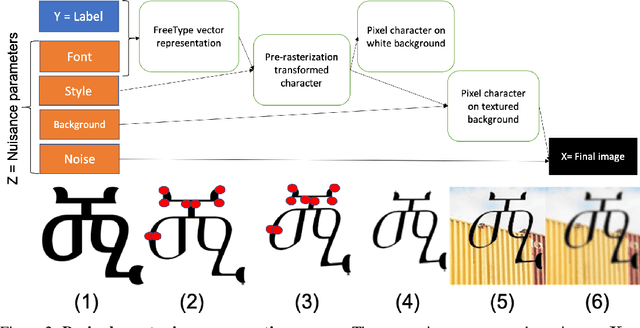

We introduce OmniPrint, a synthetic data generator of isolated printed characters, geared toward machine learning research. It draws inspiration from famous datasets such as MNIST, SVHN and Omniglot, but offers the capability of generating a wide variety of printed characters from various languages, fonts and styles, with customized distortions. We include 935 fonts from 27 scripts and many types of distortions. As a proof of concept, we show various use cases, including an example of meta-learning dataset designed for the upcoming MetaDL NeurIPS 2021 competition. OmniPrint is available at https://github.com/SunHaozhe/OmniPrint.
* Accepted at 35th Conference on Neural Information Processing Systems (NeurIPS 2021) Track on Datasets and Benchmarks. https://openreview.net/forum?id=R07XwJPmgpl
Effectiveness of Optimization Algorithms in Deep Image Classification
Oct 04, 2021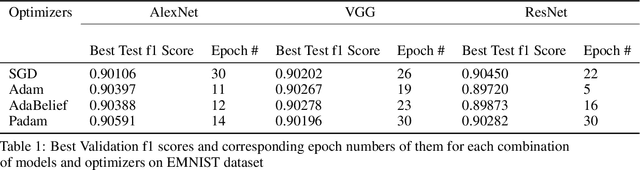
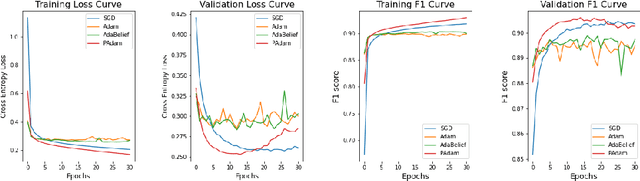
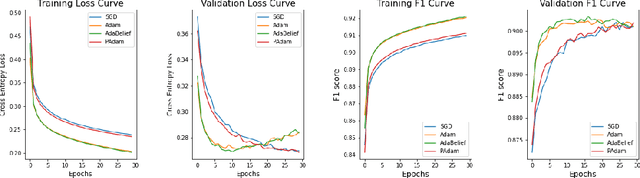
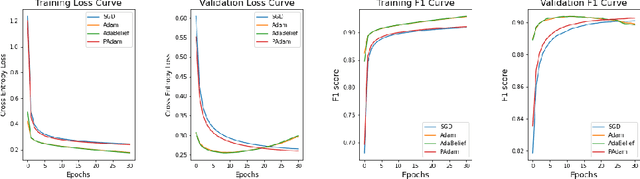
Adam is applied widely to train neural networks. Different kinds of Adam methods with different features pop out. Recently two new adam optimizers, AdaBelief and Padam are introduced among the community. We analyze these two adam optimizers and compare them with other conventional optimizers (Adam, SGD + Momentum) in the scenario of image classification. We evaluate the performance of these optimization algorithms on AlexNet and simplified versions of VGGNet, ResNet using the EMNIST dataset. (Benchmark algorithm is available at \hyperref[https://github.com/chuiyunjun/projectCSC413]{https://github.com/chuiyunjun/projectCSC413}).