 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Self-play Methods in Reinforcement Learning
Aug 02, 2024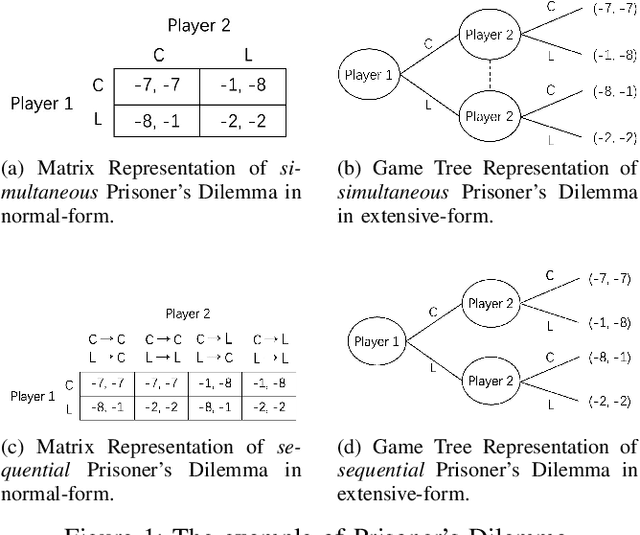
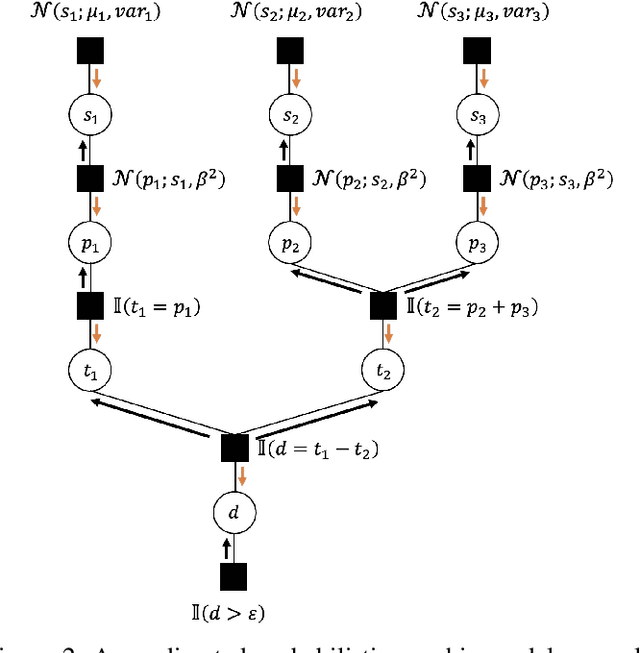
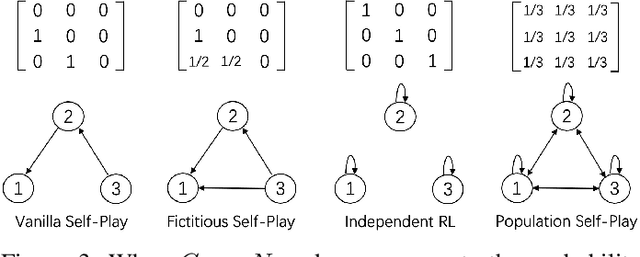
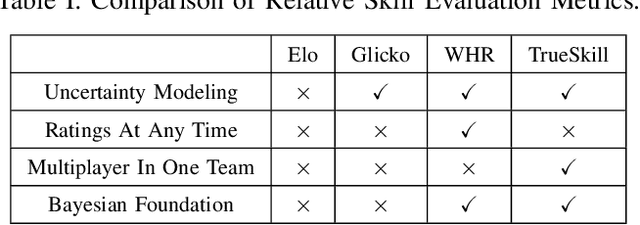
Self-play, characterized by agents' interactions with copies or past versions of itself, has recently gained prominence in reinforcement learning. This paper first clarifies the preliminaries of self-play, including the multi-agent reinforcement learning framework and basic game theory concepts. Then it provides a unified framework and classifies existing self-play algorithms within this framework. Moreover, the paper bridges the gap between the algorithms and their practical implications by illustrating the role of self-play in different scenarios. Finally, the survey highlights open challenges and future research directions in self-play. This paper is an essential guide map for understanding the multifaceted landscape of self-play in RL.
MQE: Unleashing the Power of Interaction with Multi-agent Quadruped Environment
Mar 24, 2024The advent of deep reinforcement learning (DRL) has significantly advanced the field of robotics, particularly in the control and coordination of quadruped robots. However, the complexity of real-world tasks often necessitates the deployment of multi-robot systems capable of sophisticated interaction and collaboration. To address this need, we introduce the Multi-agent Quadruped Environment (MQE), a novel platform designed to facilitate the development and evaluation of multi-agent reinforcement learning (MARL) algorithms in realistic and dynamic scenarios. MQE emphasizes complex interactions between robots and objects, hierarchical policy structures, and challenging evaluation scenarios that reflect real-world applications. We present a series of collaborative and competitive tasks within MQE, ranging from simple coordination to complex adversarial interactions, and benchmark state-of-the-art MARL algorithms. Our findings indicate that hierarchical reinforcement learning can simplify task learning, but also highlight the need for advanced algorithms capable of handling the intricate dynamics of multi-agent interactions. MQE serves as a stepping stone towards bridging the gap between simulation and practical deployment, offering a rich environment for future research in multi-agent systems and robot learning. For open-sourced code and more details of MQE, please refer to https://ziyanx02.github.io/multiagent-quadruped-environment/ .
LLMArena: Assessing Capabilities of Large Language Models in Dynamic Multi-Agent Environments
Feb 26, 2024Recent advancements in large language models (LLMs) have revealed their potential for achieving autonomous agents possessing human-level intelligence. However, existing benchmarks for evaluating LLM Agents either use static datasets, potentially leading to data leakage or focus only on single-agent scenarios, overlooking the complexities of multi-agent interactions. There is a lack of a benchmark that evaluates the diverse capabilities of LLM agents in multi-agent, dynamic environments. To this end, we introduce LLMArena, a novel and easily extensible framework for evaluating the diverse capabilities of LLM in multi-agent dynamic environments. LLMArena encompasses seven distinct gaming environments, employing Trueskill scoring to assess crucial abilities in LLM agents, including spatial reasoning, strategic planning, numerical reasoning, risk assessment, communication, opponent modeling, and team collaboration. We conduct an extensive experiment and human evaluation among different sizes and types of LLMs, showing that LLMs still have a significant journey ahead in their development towards becoming fully autonomous agents, especially in opponent modeling and team collaboration. We hope LLMArena could guide future research towards enhancing these capabilities in LLMs, ultimately leading to more sophisticated and practical applications in dynamic, multi-agent settings. The code and data will be available.
OpenRL: A Unified Reinforcement Learning Framework
Dec 20, 2023We present OpenRL, an advanced reinforcement learning (RL) framework designed to accommodate a diverse array of tasks, from single-agent challenges to complex multi-agent systems. OpenRL's robust support for self-play training empowers agents to develop advanced strategies in competitive settings. Notably, OpenRL integrates Natural Language Processing (NLP) with RL, enabling researchers to address a combination of RL training and language-centric tasks effectively. Leveraging PyTorch's robust capabilities, OpenRL exemplifies modularity and a user-centric approach. It offers a universal interface that simplifies the user experience for beginners while maintaining the flexibility experts require for innovation and algorithm development. This equilibrium enhances the framework's practicality, adaptability, and scalability, establishing a new standard in RL research. To delve into OpenRL's features, we invite researchers and enthusiasts to explore our GitHub repository at https://github.com/OpenRL-Lab/openrl and access our comprehensive documentation at https://openrl-docs.readthedocs.io.
Robustness and Generalizability of Deepfake Detection: A Study with Diffusion Models
Sep 05, 2023The rise of deepfake images, especially of well-known personalities, poses a serious threat to the dissemination of authentic information. To tackle this, we present a thorough investigation into how deepfakes are produced and how they can be identified. The cornerstone of our research is a rich collection of artificial celebrity faces, titled DeepFakeFace (DFF). We crafted the DFF dataset using advanced diffusion models and have shared it with the community through online platforms. This data serves as a robust foundation to train and test algorithms designed to spot deepfakes. We carried out a thorough review of the DFF dataset and suggest two evaluation methods to gauge the strength and adaptability of deepfake recognition tools. The first method tests whether an algorithm trained on one type of fake images can recognize those produced by other methods. The second evaluates the algorithm's performance with imperfect images, like those that are blurry, of low quality, or compressed. Given varied results across deepfake methods and image changes, our findings stress the need for better deepfake detectors. Our DFF dataset and tests aim to boost the development of more effective tools against deepfakes.
Efficient Stochastic Approximation of Minimax Excess Risk Optimization
May 31, 2023While traditional distributionally robust optimization (DRO) aims to minimize the maximal risk over a set of distributions, Agarwal and Zhang (2022) recently proposed a variant that replaces risk with excess risk. Compared to DRO, the new formulation -- minimax excess risk optimization (MERO) has the advantage of suppressing the effect of heterogeneous noise in different distributions. However, the choice of excess risk leads to a very challenging minimax optimization problem, and currently there exists only an inefficient algorithm for empirical MERO. In this paper, we develop efficient stochastic approximation approaches which directly target MERO. Specifically, we leverage techniques from stochastic convex optimization to estimate the minimal risk of every distribution, and solve MERO as a stochastic convex-concave optimization (SCCO) problem with biased gradients. The presence of bias makes existing theoretical guarantees of SCCO inapplicable, and fortunately, we demonstrate that the bias, caused by the estimation error of the minimal risk, is under-control. Thus, MERO can still be optimized with a nearly optimal convergence rate. Moreover, we investigate a practical scenario where the quantity of samples drawn from each distribution may differ, and propose a stochastic approach that delivers distribution-dependent convergence rates.
TiZero: Mastering Multi-Agent Football with Curriculum Learning and Self-Play
Feb 21, 2023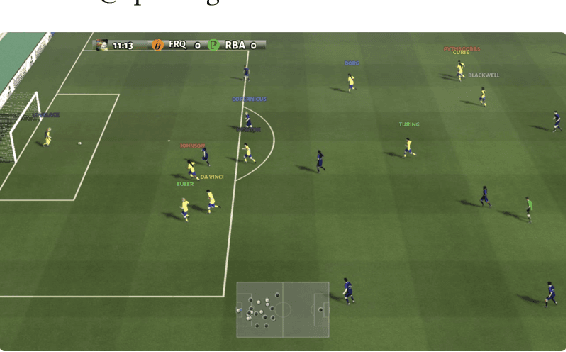

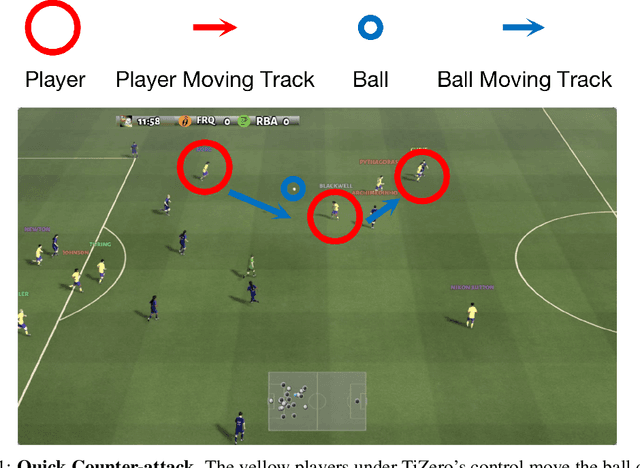

Multi-agent football poses an unsolved challenge in AI research. Existing work has focused on tackling simplified scenarios of the game, or else leveraging expert demonstrations. In this paper, we develop a multi-agent system to play the full 11 vs. 11 game mode, without demonstrations. This game mode contains aspects that present major challenges to modern reinforcement learning algorithms; multi-agent coordination, long-term planning, and non-transitivity. To address these challenges, we present TiZero; a self-evolving, multi-agent system that learns from scratch. TiZero introduces several innovations, including adaptive curriculum learning, a novel self-play strategy, and an objective that optimizes the policies of multiple agents jointly. Experimentally, it outperforms previous systems by a large margin on the Google Research Football environment, increasing win rates by over 30%. To demonstrate the generality of TiZero's innovations, they are assessed on several environments beyond football; Overcooked, Multi-agent Particle-Environment, Tic-Tac-Toe and Connect-Four.
Optimistic Online Mirror Descent for Bridging Stochastic and Adversarial Online Convex Optimization
Feb 09, 2023Stochastically Extended Adversarial (SEA) model is introduced by Sachs et al. [2022] as an interpolation between stochastic and adversarial online convex optimization. Under the smoothness condition, they demonstrate that the expected regret of optimistic follow-the-regularized-leader (FTRL) depends on the cumulative stochastic variance $\sigma_{1:T}^2$ and the cumulative adversarial variation $\Sigma_{1:T}^2$ for convex functions. They also provide a slightly weaker bound based on the maximal stochastic variance $\sigma_{\max}^2$ and the maximal adversarial variation $\Sigma_{\max}^2$ for strongly convex functions. Inspired by their work, we investigate the theoretical guarantees of optimistic online mirror descent (OMD) for the SEA model. For convex and smooth functions, we obtain the same $\mathcal{O}(\sqrt{\sigma_{1:T}^2}+\sqrt{\Sigma_{1:T}^2})$ regret bound, without the convexity requirement of individual functions. For strongly convex and smooth functions, we establish an $\mathcal{O}(\min\{\log (\sigma_{1:T}^2+\Sigma_{1:T}^2), (\sigma_{\max}^2 + \Sigma_{\max}^2) \log T\})$ bound, better than their $\mathcal{O}((\sigma_{\max}^2 + \Sigma_{\max}^2) \log T)$ bound. For \mbox{exp-concave} and smooth functions, we achieve a new $\mathcal{O}(d\log(\sigma_{1:T}^2+\Sigma_{1:T}^2))$ bound. Owing to the OMD framework, we can further extend our result to obtain dynamic regret guarantees, which are more favorable in non-stationary online scenarios. The attained results allow us to recover excess risk bounds of the stochastic setting and regret bounds of the adversarial setting, and derive new guarantees for many intermediate scenarios.
Learning Graph-Enhanced Commander-Executor for Multi-Agent Navigation
Feb 08, 2023This paper investigates the multi-agent navigation problem, which requires multiple agents to reach the target goals in a limited time. Multi-agent reinforcement learning (MARL) has shown promising results for solving this issue. However, it is inefficient for MARL to directly explore the (nearly) optimal policy in the large search space, which is exacerbated as the agent number increases (e.g., 10+ agents) or the environment is more complex (e.g., 3D simulator). Goal-conditioned hierarchical reinforcement learning (HRL) provides a promising direction to tackle this challenge by introducing a hierarchical structure to decompose the search space, where the low-level policy predicts primitive actions in the guidance of the goals derived from the high-level policy. In this paper, we propose Multi-Agent Graph-Enhanced Commander-Executor (MAGE-X), a graph-based goal-conditioned hierarchical method for multi-agent navigation tasks. MAGE-X comprises a high-level Goal Commander and a low-level Action Executor. The Goal Commander predicts the probability distribution of goals and leverages them to assign each agent the most appropriate final target. The Action Executor utilizes graph neural networks (GNN) to construct a subgraph for each agent that only contains crucial partners to improve cooperation. Additionally, the Goal Encoder in the Action Executor captures the relationship between the agent and the designated goal to encourage the agent to reach the final target. The results show that MAGE-X outperforms the state-of-the-art MARL baselines with a 100% success rate with only 3 million training steps in multi-agent particle environments (MPE) with 50 agents, and at least a 12% higher success rate and 2x higher data efficiency in a more complicated quadrotor 3D navigation task.
Transfer and Share: Semi-Supervised Learning from Long-Tailed Data
May 26, 2022
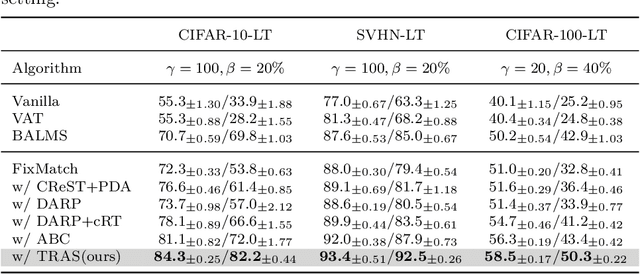


Long-Tailed Semi-Supervised Learning (LTSSL) aims to learn from class-imbalanced data where only a few samples are annotated. Existing solutions typically require substantial cost to solve complex optimization problems, or class-balanced undersampling which can result in information loss. In this paper, we present the TRAS (TRAnsfer and Share) to effectively utilize long-tailed semi-supervised data. TRAS transforms the imbalanced pseudo-label distribution of a traditional SSL model via a delicate function to enhance the supervisory signals for minority classes. It then transfers the distribution to a target model such that the minority class will receive significant attention. Interestingly, TRAS shows that more balanced pseudo-label distribution can substantially benefit minority-class training, instead of seeking to generate accurate pseudo-labels as in previous works. To simplify the approach, TRAS merges the training of the traditional SSL model and the target model into a single procedure by sharing the feature extractor, where both classifiers help improve the representation learning. According to extensive experiments, TRAS delivers much higher accuracy than state-of-the-art methods in the entire set of classes as well as minority classes.