 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayes Adaptive Monte Carlo Tree Search for Offline Model-based Reinforcement Learning
Oct 15, 2024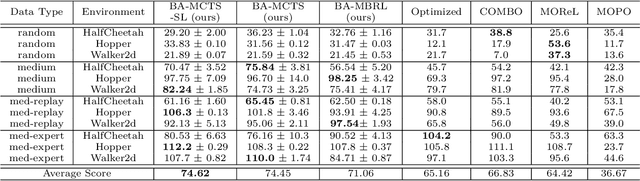
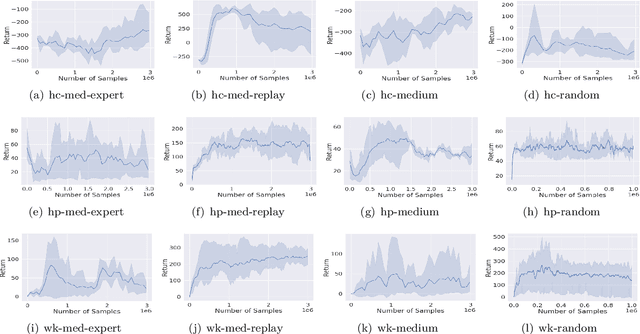
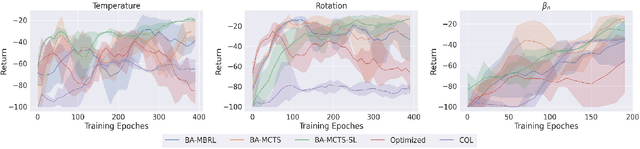
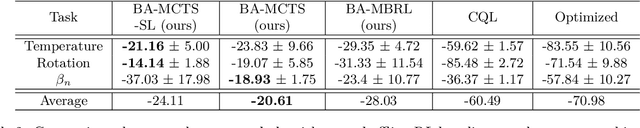
Offline reinforcement learning (RL) is a powerful approach for data-driven decision-making and control. Compared to model-free methods, offline model-based reinforcement learning (MBRL) explicitly learns world models from a static dataset and uses them as surrogate simulators, improving the data efficiency and enabling the learned policy to potentially generalize beyond the dataset support. However, there could be various MDPs that behave identically on the offline dataset and so dealing with the uncertainty about the true MDP can be challenging. In this paper, we propose modeling offline MBRL as a Bayes Adaptive Markov Decision Process (BAMDP), which is a principled framework for addressing model uncertainty. We further introduce a novel Bayes Adaptive Monte-Carlo planning algorithm capable of solving BAMDPs in continuous state and action spaces with stochastic transitions. This planning process is based on Monte Carlo Tree Search and can be integrated into offline MBRL as a policy improvement operator in policy iteration. Our ``RL + Search" framework follows in the footsteps of superhuman AIs like AlphaZero, improving on current offline MBRL methods by incorporating more computation input. The proposed algorithm significantly outperforms state-of-the-art model-based and model-free offline RL methods on twelve D4RL MuJoCo benchmark tasks and three target tracking tasks in a challenging, stochastic tokamak control simulator.
Soft-QMIX: Integrating Maximum Entropy For Monotonic Value Function Factorization
Jun 20, 2024



Multi-agent reinforcement learning (MARL) tasks often utilize a centralized training with decentralized execution (CTDE) framework. QMIX is a successful CTDE method that learns a credit assignment function to derive local value functions from a global value function, defining a deterministic local policy. However, QMIX is hindered by its poor exploration strategy. While maximum entropy reinforcement learning (RL) promotes better exploration through stochastic policies, QMIX's process of credit assignment conflicts with the maximum entropy objective and the decentralized execution requirement, making it unsuitable for maximum entropy RL. In this paper, we propose an enhancement to QMIX by incorporating an additional local Q-value learning method within the maximum entropy RL framework. Our approach constrains the local Q-value estimates to maintain the correct ordering of all actions. Due to the monotonicity of the QMIX value function, these updates ensure that locally optimal actions align with globally optimal actions. We theoretically prove the monotonic improvement and convergence of our method to an optimal solution. Experimentally, we validate our algorithm in matrix games, Multi-Agent Particle Environment and demonstrate state-of-the-art performance in SMAC-v2.
OpenRL: A Unified Reinforcement Learning Framework
Dec 20, 2023We present OpenRL, an advanced reinforcement learning (RL) framework designed to accommodate a diverse array of tasks, from single-agent challenges to complex multi-agent systems. OpenRL's robust support for self-play training empowers agents to develop advanced strategies in competitive settings. Notably, OpenRL integrates Natural Language Processing (NLP) with RL, enabling researchers to address a combination of RL training and language-centric tasks effectively. Leveraging PyTorch's robust capabilities, OpenRL exemplifies modularity and a user-centric approach. It offers a universal interface that simplifies the user experience for beginners while maintaining the flexibility experts require for innovation and algorithm development. This equilibrium enhances the framework's practicality, adaptability, and scalability, establishing a new standard in RL research. To delve into OpenRL's features, we invite researchers and enthusiasts to explore our GitHub repository at https://github.com/OpenRL-Lab/openrl and access our comprehensive documentation at https://openrl-docs.readthedocs.io.