 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePGVMS: A Prompt-Guided Unified Framework for Virtual Multiplex IHC Staining with Pathological Semantic Learning
Feb 26, 2026Immunohistochemical (IHC) staining enables precise molecular profiling of protein expression, with over 200 clinically available antibody-based tests in modern pathology. However, comprehensive IHC analysis is frequently limited by insufficient tissue quantities in small biopsies. Therefore, virtual multiplex staining emerges as an innovative solution to digitally transform H&E images into multiple IHC representations, yet current methods still face three critical challenges: (1) inadequate semantic guidance for multi-staining, (2) inconsistent distribution of immunochemistry staining, and (3) spatial misalignment across different stain modalities. To overcome these limitations, we present a prompt-guided framework for virtual multiplex IHC staining using only uniplex training data (PGVMS). Our framework introduces three key innovations corresponding to each challenge: First, an adaptive prompt guidance mechanism employing a pathological visual language model dynamically adjusts staining prompts to resolve semantic guidance limitations (Challenge 1). Second, our protein-aware learning strategy (PALS) maintains precise protein expression patterns by direct quantification and constraint of protein distributions (Challenge 2). Third, the prototype-consistent learning strategy (PCLS) establishes cross-image semantic interaction to correct spatial misalignments (Challenge 3).
* Accepted by TMI
Adaptive Value Decomposition: Coordinating a Varying Number of Agents in Urban Systems
Feb 10, 2026Multi-agent reinforcement learning (MARL) provides a promising paradigm for coordinating multi-agent systems (MAS). However, most existing methods rely on restrictive assumptions, such as a fixed number of agents and fully synchronous action execution. These assumptions are often violated in urban systems, where the number of active agents varies over time, and actions may have heterogeneous durations, resulting in a semi-MARL setting. Moreover, while sharing policy parameters among agents is commonly adopted to improve learning efficiency, it can lead to highly homogeneous actions when a subset of agents make decisions concurrently under similar observations, potentially degrading coordination quality. To address these challenges, we propose Adaptive Value Decomposition (AVD), a cooperative MARL framework that adapts to a dynamically changing agent population. AVD further incorporates a lightweight mechanism to mitigate action homogenization induced by shared policies, thereby encouraging behavioral diversity and maintaining effective cooperation among agents. In addition, we design a training-execution strategy tailored to the semi-MARL setting that accommodates asynchronous decision-making when some agents act at different times. Experiments on real-world bike-sharing redistribution tasks in two major cities, London and Washington, D.C., demonstrate that AVD outperforms state-of-the-art baselines, confirming its effectiveness and generalizability.
AutoPBO: LLM-powered Optimization for Local Search PBO Solvers
Sep 04, 2025Pseudo-Boolean Optimization (PBO) provides a powerful framework for modeling combinatorial problems through pseudo-Boolean (PB) constraints. Local search solvers have shown excellent performance in PBO solving, and their efficiency is highly dependent on their internal heuristics to guide the search. Still, their design often requires significant expert effort and manual tuning in practice. While Large Language Models (LLMs) have demonstrated potential in automating algorithm design, their application to optimizing PBO solvers remains unexplored. In this work, we introduce AutoPBO, a novel LLM-powered framework to automatically enhance PBO local search solvers. We conduct experiments on a broad range of four public benchmarks, including one real-world benchmark, a benchmark from PB competition, an integer linear programming optimization benchmark, and a crafted combinatorial benchmark, to evaluate the performance improvement achieved by AutoPBO and compare it with six state-of-the-art competitors, including two local search PBO solvers NuPBO and OraSLS, two complete PB solvers PBO-IHS and RoundingSat, and two mixed integer programming (MIP) solvers Gurobi and SCIP. AutoPBO demonstrates significant improvements over previous local search approaches, while maintaining competitive performance compared to state-of-the-art competitors. The results suggest that AutoPBO offers a promising approach to automating local search solver design.
Automatically discovering heuristics in a complex SAT solver with large language models
Jul 30, 2025Satisfiability problem (SAT) is a cornerstone of computational complexity with broad industrial applications, and it remains challenging to optimize modern SAT solvers in real-world settings due to their intricate architectures. While automatic configuration frameworks have been developed, they rely on manually constrained search spaces and yield limited performance gains. This work introduces a novel paradigm which effectively optimizes complex SAT solvers via Large Language Models (LLMs), and a tool called AutoModSAT is developed. Three fundamental challenges are addressed in order to achieve superior performance: (1) LLM-friendly solver: Systematic guidelines are proposed for developing a modularized solver to meet LLMs' compatibility, emphasizing code simplification, information share and bug reduction; (2) Automatic prompt optimization: An unsupervised automatic prompt optimization method is introduced to advance the diversity of LLMs' output; (3) Efficient search strategy: We design a presearch strategy and an EA evolutionary algorithm for the final efficient and effective discovery of heuristics. Extensive experiments across a wide range of datasets demonstrate that AutoModSAT achieves 50% performance improvement over the baseline solver and achieves 30% superiority against the state-of-the-art (SOTA) solvers. Moreover, AutoModSAT attains a 20% speedup on average compared to parameter-tuned alternatives of the SOTA solvers, showcasing the enhanced capability in handling complex problem instances. This work bridges the gap between AI-driven heuristics discovery and mission-critical system optimization, and provides both methodological advancements and empirically validated results for next-generation complex solver development.
Comprehensive Evaluation for a Large Scale Knowledge Graph Question Answering Service
Jan 28, 2025



Question answering systems for knowledge graph (KGQA), answer factoid questions based on the data in the knowledge graph. KGQA systems are complex because the system has to understand the relations and entities in the knowledge-seeking natural language queries and map them to structured queries against the KG to answer them. In this paper, we introduce Chronos, a comprehensive evaluation framework for KGQA at industry scale. It is designed to evaluate such a multi-component system comprehensively, focusing on (1) end-to-end and component-level metrics, (2) scalable to diverse datasets and (3) a scalable approach to measure the performance of the system prior to release. In this paper, we discuss the unique challenges associated with evaluating KGQA systems at industry scale, review the design of Chronos, and how it addresses these challenges. We will demonstrate how it provides a base for data-driven decisions and discuss the challenges of using it to measure and improve a real-world KGQA system.
Improving Multi-Step Reasoning Abilities of Large Language Models with Direct Advantage Policy Optimization
Dec 24, 2024



The role of reinforcement learning (RL) in enhancing the reasoning of large language models (LLMs) is becoming increasingly significant. Despite the success of RL in many scenarios, there are still many challenges in improving the reasoning of LLMs. One challenge is the sparse reward, which makes optimization difficult for RL and necessitates a large amount of data samples. Another challenge stems from the inherent instability of RL, particularly when using Actor-Critic (AC) methods to derive optimal policies, which often leads to unstable training processes. To address these issues, we introduce Direct Advantage Policy Optimization (DAPO), an novel step-level offline RL algorithm. Unlike standard alignment that rely solely outcome rewards to optimize policies (such as DPO), DAPO employs a critic function to predict the reasoning accuracy at each step, thereby generating dense signals to refine the generation strategy. Additionally, the Actor and Critic components in DAPO are trained independently, avoiding the co-training instability observed in standard AC algorithms like PPO. We train DAPO on mathematical and code query datasets and then evaluate its performance on multiple benchmarks. Our results show that DAPO can effectively enhance the mathematical and code capabilities on both SFT models and RL models, demonstrating the effectiveness of DAPO.
Pathological Semantics-Preserving Learning for H&E-to-IHC Virtual Staining
Jul 04, 2024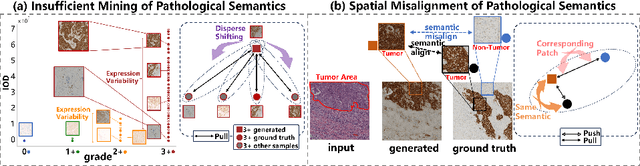

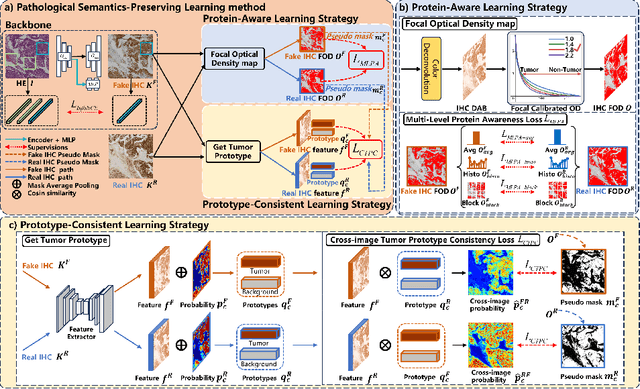
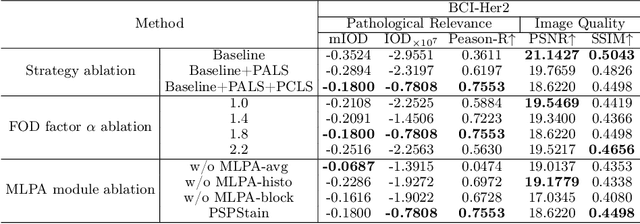
Conventional hematoxylin-eosin (H&E) staining is limited to revealing cell morphology and distribution, whereas immunohistochemical (IHC) staining provides precise and specific visualization of protein activation at the molecular level. Virtual staining technology has emerged as a solution for highly efficient IHC examination, which directly transforms H&E-stained images to IHC-stained images. However, virtual staining is challenged by the insufficient mining of pathological semantics and the spatial misalignment of pathological semantics. To address these issues, we propose the Pathological Semantics-Preserving Learning method for Virtual Staining (PSPStain), which directly incorporates the molecular-level semantic information and enhances semantics interaction despite any spatial inconsistency. Specifically, PSPStain comprises two novel learning strategies: 1) Protein-Aware Learning Strategy (PALS) with Focal Optical Density (FOD) map maintains the coherence of protein expression level, which represents molecular-level semantic information; 2) Prototype-Consistent Learning Strategy (PCLS), which enhances cross-image semantic interaction by prototypical consistency learning. We evaluate PSPStain on two public datasets using five metrics: three clinically relevant metrics and two for image quality. Extensive experiments indicate that PSPStain outperforms current state-of-the-art H&E-to-IHC virtual staining methods and demonstrates a high pathological correlation between the staging of real and virtual stains.
Mix Q-learning for Lane Changing: A Collaborative Decision-Making Method in Multi-Agent Deep Reinforcement Learning
Jun 14, 2024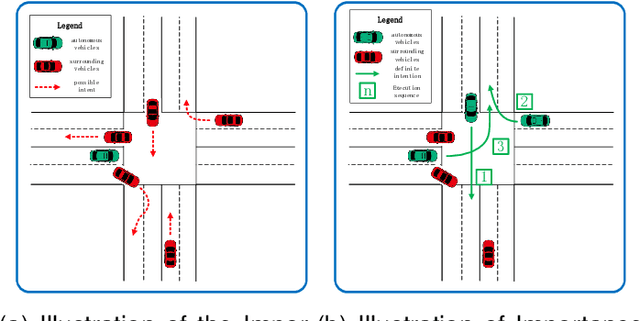

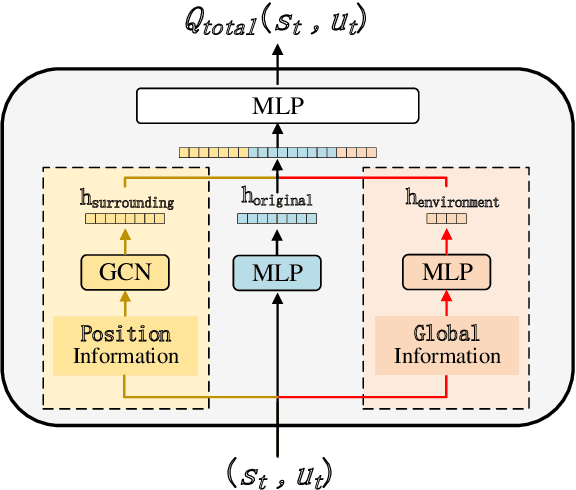

Lane-changing decisions, which are crucial for autonomous vehicle path planning, face practical challenges due to rule-based constraints and limited data. Deep reinforcement learning has become a major research focus due to its advantages in data acquisition and interpretability. However, current models often overlook collaboration, which affects not only impacts overall traffic efficiency but also hinders the vehicle's own normal driving in the long run. To address the aforementioned issue, this paper proposes a method named Mix Q-learning for Lane Changing(MQLC) that integrates a hybrid value Q network, taking into account both collective and individual benefits for the greater good. At the collective level, our method coordinates the individual Q and global Q networks by utilizing global information. This enables agents to effectively balance their individual interests with the collective benefit. At the individual level, we integrated a deep learning-based intent recognition module into our observation and enhanced the decision network. These changes provide agents with richer decision information and more accurate feature extraction for improved lane-changing decisions. This strategy enables the multi-agent system to learn and formulate optimal decision-making strategies effectively. Our MQLC model, through extensive experimental results, impressively outperforms other state-of-the-art multi-agent decision-making methods, achieving significantly safer and faster lane-changing decisions.
OpenTensor: Reproducing Faster Matrix Multiplication Discovering Algorithms
May 31, 2024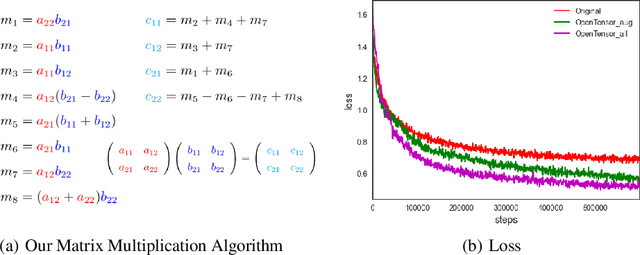
OpenTensor is a reproduction of AlphaTensor, which discovered a new algorithm that outperforms the state-of-the-art methods for matrix multiplication by Deep Reinforcement Learning (DRL). While AlphaTensor provides a promising framework for solving scientific problems, it is really hard to reproduce due to the massive tricks and lack of source codes. In this paper, we clean up the algorithm pipeline, clarify the technical details, and make some improvements to the training process. Computational results show that OpenTensor can successfully find efficient matrix multiplication algorithms.
AutoSAT: Automatically Optimize SAT Solvers via Large Language Models
Feb 16, 2024



Heuristics are crucial in SAT solvers, while no heuristic rules are suitable for all problem instances. Therefore, it typically requires to refine specific solvers for specific problem instances. In this context, we present AutoSAT, a novel framework for automatically optimizing heuristics in SAT solvers. AutoSAT is based on Large Large Models (LLMs) which is able to autonomously generate code, conduct evaluation, then utilize the feedback to further optimize heuristics, thereby reducing human intervention and enhancing solver capabilities. AutoSAT operates on a plug-and-play basis, eliminating the need for extensive preliminary setup and model training, and fosters a Chain of Thought collaborative process with fault-tolerance, ensuring robust heuristic optimization. Extensive experiments on a Conflict-Driven Clause Learning (CDCL) solver demonstrates the overall superior performance of AutoSAT, especially in solving some specific SAT problem instances.