 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePGVMS: A Prompt-Guided Unified Framework for Virtual Multiplex IHC Staining with Pathological Semantic Learning
Feb 26, 2026Immunohistochemical (IHC) staining enables precise molecular profiling of protein expression, with over 200 clinically available antibody-based tests in modern pathology. However, comprehensive IHC analysis is frequently limited by insufficient tissue quantities in small biopsies. Therefore, virtual multiplex staining emerges as an innovative solution to digitally transform H&E images into multiple IHC representations, yet current methods still face three critical challenges: (1) inadequate semantic guidance for multi-staining, (2) inconsistent distribution of immunochemistry staining, and (3) spatial misalignment across different stain modalities. To overcome these limitations, we present a prompt-guided framework for virtual multiplex IHC staining using only uniplex training data (PGVMS). Our framework introduces three key innovations corresponding to each challenge: First, an adaptive prompt guidance mechanism employing a pathological visual language model dynamically adjusts staining prompts to resolve semantic guidance limitations (Challenge 1). Second, our protein-aware learning strategy (PALS) maintains precise protein expression patterns by direct quantification and constraint of protein distributions (Challenge 2). Third, the prototype-consistent learning strategy (PCLS) establishes cross-image semantic interaction to correct spatial misalignments (Challenge 3).
* Accepted by TMI
A Semantically Enhanced Generative Foundation Model Improves Pathological Image Synthesis
Dec 16, 2025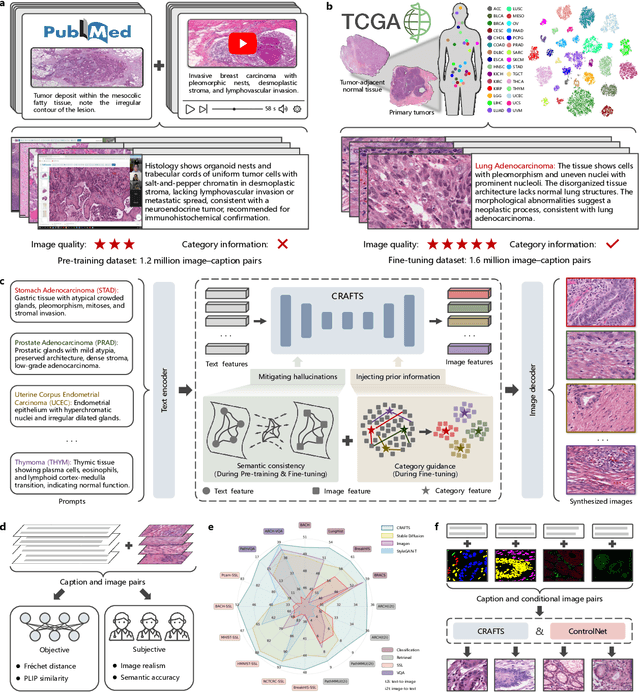
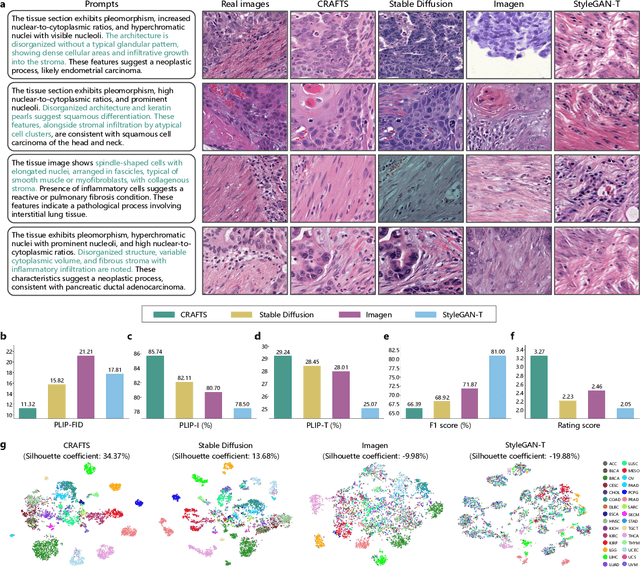
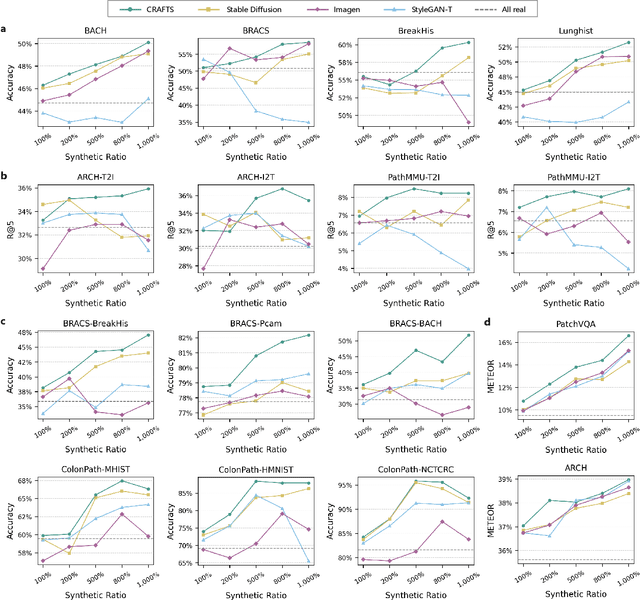
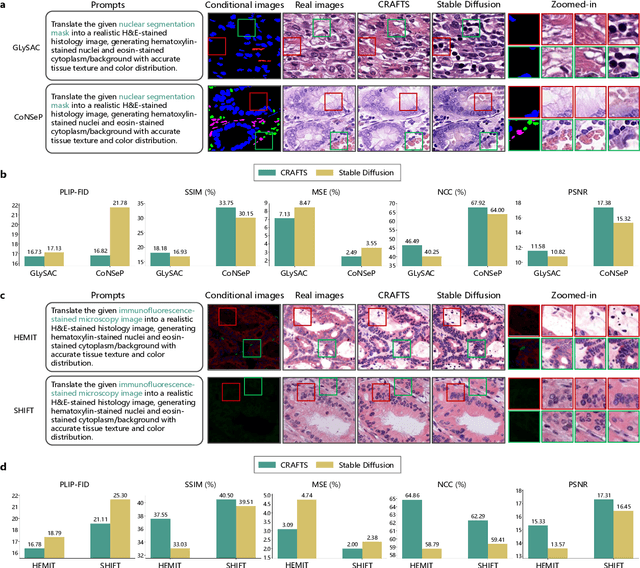
The development of clinical-grade artificial intelligence in pathology is limited by the scarcity of diverse, high-quality annotated datasets. Generative models offer a potential solution but suffer from semantic instability and morphological hallucinations that compromise diagnostic reliability. To address this challenge, we introduce a Correlation-Regulated Alignment Framework for Tissue Synthesis (CRAFTS), the first generative foundation model for pathology-specific text-to-image synthesis. By leveraging a dual-stage training strategy on approximately 2.8 million image-caption pairs, CRAFTS incorporates a novel alignment mechanism that suppresses semantic drift to ensure biological accuracy. This model generates diverse pathological images spanning 30 cancer types, with quality rigorously validated by objective metrics and pathologist evaluations. Furthermore, CRAFTS-augmented datasets enhance the performance across various clinical tasks, including classification, cross-modal retrieval, self-supervised learning, and visual question answering. In addition, coupling CRAFTS with ControlNet enables precise control over tissue architecture from inputs such as nuclear segmentation masks and fluorescence images. By overcoming the critical barriers of data scarcity and privacy concerns, CRAFTS provides a limitless source of diverse, annotated histology data, effectively unlocking the creation of robust diagnostic tools for rare and complex cancer phenotypes.
Unpaired Multi-Domain Histopathology Virtual Staining using Dual Path Prompted Inversion
Dec 15, 2024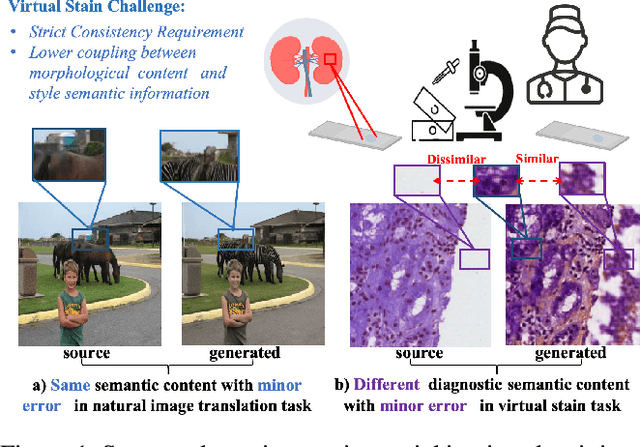


Virtual staining leverages computer-aided techniques to transfer the style of histochemically stained tissue samples to other staining types. In virtual staining of pathological images, maintaining strict structural consistency is crucial, as these images emphasize structural integrity more than natural images. Even slight structural alterations can lead to deviations in diagnostic semantic information. Furthermore, the unpaired characteristic of virtual staining data may compromise the preservation of pathological diagnostic content. To address these challenges, we propose a dual-path inversion virtual staining method using prompt learning, which optimizes visual prompts to control content and style, while preserving complete pathological diagnostic content. Our proposed inversion technique comprises two key components: (1) Dual Path Prompted Strategy, we utilize a feature adapter function to generate reference images for inversion, providing style templates for input image inversion, called Style Target Path. We utilize the inversion of the input image as the Structural Target path, employing visual prompt images to maintain structural consistency in this path while preserving style information from the style Target path. During the deterministic sampling process, we achieve complete content-style disentanglement through a plug-and-play embedding visual prompt approach. (2) StainPrompt Optimization, where we only optimize the null visual prompt as ``operator'' for dual path inversion, rather than fine-tune pre-trained model. We optimize null visual prompt for structual and style trajectory around pivotal noise on each timestep, ensuring accurate dual-path inversion reconstruction. Extensive evaluations on publicly available multi-domain unpaired staining datasets demonstrate high structural consistency and accurate style transfer results.
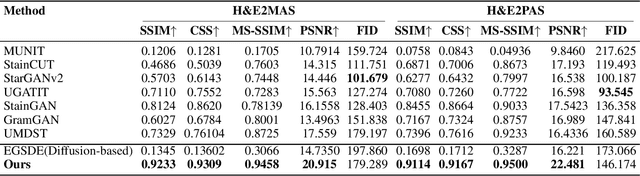
Pathological Semantics-Preserving Learning for H&E-to-IHC Virtual Staining
Jul 04, 2024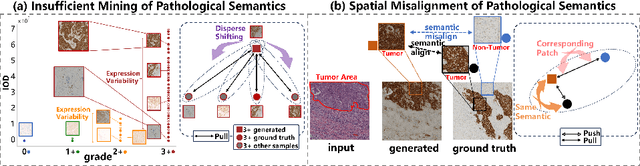

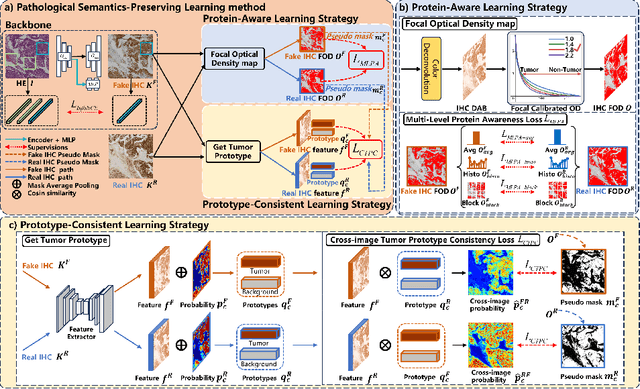
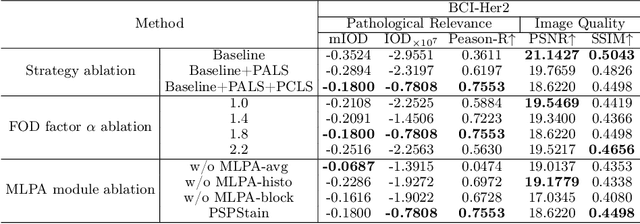
Conventional hematoxylin-eosin (H&E) staining is limited to revealing cell morphology and distribution, whereas immunohistochemical (IHC) staining provides precise and specific visualization of protein activation at the molecular level. Virtual staining technology has emerged as a solution for highly efficient IHC examination, which directly transforms H&E-stained images to IHC-stained images. However, virtual staining is challenged by the insufficient mining of pathological semantics and the spatial misalignment of pathological semantics. To address these issues, we propose the Pathological Semantics-Preserving Learning method for Virtual Staining (PSPStain), which directly incorporates the molecular-level semantic information and enhances semantics interaction despite any spatial inconsistency. Specifically, PSPStain comprises two novel learning strategies: 1) Protein-Aware Learning Strategy (PALS) with Focal Optical Density (FOD) map maintains the coherence of protein expression level, which represents molecular-level semantic information; 2) Prototype-Consistent Learning Strategy (PCLS), which enhances cross-image semantic interaction by prototypical consistency learning. We evaluate PSPStain on two public datasets using five metrics: three clinically relevant metrics and two for image quality. Extensive experiments indicate that PSPStain outperforms current state-of-the-art H&E-to-IHC virtual staining methods and demonstrates a high pathological correlation between the staging of real and virtual stains.
Spectral Classification Using Restricted Boltzmann Machine
Oct 13, 2013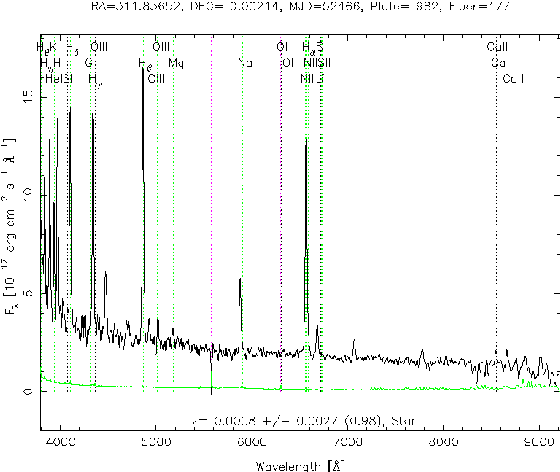
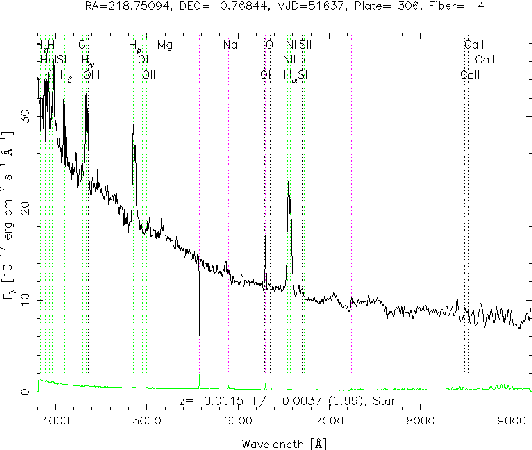

In this study, a novel machine learning algorithm, restricted Boltzmann machine (RBM), is introduced. The algorithm is applied for the spectral classification in astronomy. RBM is a bipartite generative graphical model with two separate layers (one visible layer and one hidden layer), which can extract higher level features to represent the original data. Despite generative, RBM can be used for classification when modified with a free energy and a soft-max function. Before spectral classification, the original data is binarized according to some rule. Then we resort to the binary RBM to classify cataclysmic variables (CVs) and non-CVs (one half of all the given data for training and the other half for testing). The experiment result shows state-of-the-art accuracy of 100%, which indicates the efficiency of the binary RBM algorithm.
An Improved EM algorithm
May 03, 2013In this paper, we firstly give a brief introduction of expectation maximization (EM) algorithm, and then discuss the initial value sensitivity of expectation maximization algorithm. Subsequently, we give a short proof of EM's convergence. Then, we implement experiments with the expectation maximization algorithm (We implement all the experiments on Gaussion mixture model (GMM)). Our experiment with expectation maximization is performed in the following three cases: initialize randomly; initialize with result of K-means; initialize with result of K-medoids. The experiment result shows that expectation maximization algorithm depend on its initial state or parameters. And we found that EM initialized with K-medoids performed better than both the one initialized with K-means and the one initialized randomly.