 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing Knowledge Gaps in LLM Tool Use: An Agentic Benchmark for Novel API Acquisition
Jun 02, 2026Large language models for code generation often need to use APIs that are absent from their pretraining data. This requires more than recalling a function name: models must coordinate signatures, module paths, input-output contracts, semantics, and executable usage patterns. Existing novel-API benchmarks are typically static, rely on coarse pass/fail metrics, or use synthetic APIs that may not reflect real library evolution. We introduce NovelAPIBench, a fully automated dynamic benchmark that, for any base model and target library, discovers novel APIs, extracts decomposed knowledge bundles, generates executable coding tasks, and assigns failed samples to six diagnostic categories. Across about 1.9K tasks, four base models, and five domains, we compare knowledge injected through retrieval with knowledge internalized through parametric adaptation. We find that knowledge components are not interchangeable: usage examples are the strongest standalone signal, while the best two-component setting pairs signatures with either mechanisms or examples depending on the domain and backbone. Adding more context, especially source code, can hurt by increasing import-path errors. Parametric adaptation also does not replace retrieval once external knowledge is removed; rather, fine-tuning mainly teaches models how to use provided bundles, and this ability transfers to held-out libraries. These results suggest that retrieval and tuning play complementary roles: retrieval supplies volatile API content, while tuning improves procedural integration.
PGVMS: A Prompt-Guided Unified Framework for Virtual Multiplex IHC Staining with Pathological Semantic Learning
Feb 26, 2026Immunohistochemical (IHC) staining enables precise molecular profiling of protein expression, with over 200 clinically available antibody-based tests in modern pathology. However, comprehensive IHC analysis is frequently limited by insufficient tissue quantities in small biopsies. Therefore, virtual multiplex staining emerges as an innovative solution to digitally transform H&E images into multiple IHC representations, yet current methods still face three critical challenges: (1) inadequate semantic guidance for multi-staining, (2) inconsistent distribution of immunochemistry staining, and (3) spatial misalignment across different stain modalities. To overcome these limitations, we present a prompt-guided framework for virtual multiplex IHC staining using only uniplex training data (PGVMS). Our framework introduces three key innovations corresponding to each challenge: First, an adaptive prompt guidance mechanism employing a pathological visual language model dynamically adjusts staining prompts to resolve semantic guidance limitations (Challenge 1). Second, our protein-aware learning strategy (PALS) maintains precise protein expression patterns by direct quantification and constraint of protein distributions (Challenge 2). Third, the prototype-consistent learning strategy (PCLS) establishes cross-image semantic interaction to correct spatial misalignments (Challenge 3).
* Accepted by TMI
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
Jan 09, 2026We introduce Parallel Coordinated Reasoning (PaCoRe), a training-and-inference framework designed to overcome a central limitation of contemporary language models: their inability to scale test-time compute (TTC) far beyond sequential reasoning under a fixed context window. PaCoRe departs from the traditional sequential paradigm by driving TTC through massive parallel exploration coordinated via a message-passing architecture in multiple rounds. Each round launches many parallel reasoning trajectories, compacts their findings into context-bounded messages, and synthesizes these messages to guide the next round and ultimately produce the final answer. Trained end-to-end with large-scale, outcome-based reinforcement learning, the model masters the synthesis abilities required by PaCoRe and scales to multi-million-token effective TTC without exceeding context limits. The approach yields strong improvements across diverse domains, and notably pushes reasoning beyond frontier systems in mathematics: an 8B model reaches 94.5% on HMMT 2025, surpassing GPT-5's 93.2% by scaling effective TTC to roughly two million tokens. We open-source model checkpoints, training data, and the full inference pipeline to accelerate follow-up work.
StepFun-Prover Preview: Let's Think and Verify Step by Step
Jul 27, 2025We present StepFun-Prover Preview, a large language model designed for formal theorem proving through tool-integrated reasoning. Using a reinforcement learning pipeline that incorporates tool-based interactions, StepFun-Prover can achieve strong performance in generating Lean 4 proofs with minimal sampling. Our approach enables the model to emulate human-like problem-solving strategies by iteratively refining proofs based on real-time environment feedback. On the miniF2F-test benchmark, StepFun-Prover achieves a pass@1 success rate of $70.0\%$. Beyond advancing benchmark performance, we introduce an end-to-end training framework for developing tool-integrated reasoning models, offering a promising direction for automated theorem proving and Math AI assistant.
Unpaired Multi-Domain Histopathology Virtual Staining using Dual Path Prompted Inversion
Dec 15, 2024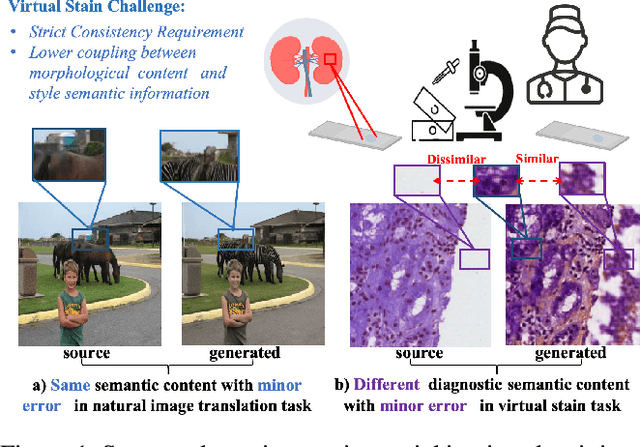
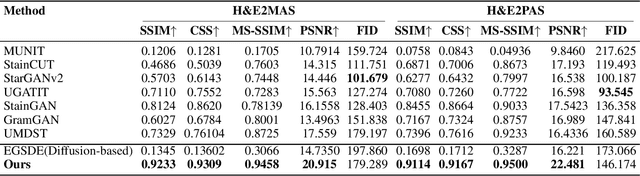


Virtual staining leverages computer-aided techniques to transfer the style of histochemically stained tissue samples to other staining types. In virtual staining of pathological images, maintaining strict structural consistency is crucial, as these images emphasize structural integrity more than natural images. Even slight structural alterations can lead to deviations in diagnostic semantic information. Furthermore, the unpaired characteristic of virtual staining data may compromise the preservation of pathological diagnostic content. To address these challenges, we propose a dual-path inversion virtual staining method using prompt learning, which optimizes visual prompts to control content and style, while preserving complete pathological diagnostic content. Our proposed inversion technique comprises two key components: (1) Dual Path Prompted Strategy, we utilize a feature adapter function to generate reference images for inversion, providing style templates for input image inversion, called Style Target Path. We utilize the inversion of the input image as the Structural Target path, employing visual prompt images to maintain structural consistency in this path while preserving style information from the style Target path. During the deterministic sampling process, we achieve complete content-style disentanglement through a plug-and-play embedding visual prompt approach. (2) StainPrompt Optimization, where we only optimize the null visual prompt as ``operator'' for dual path inversion, rather than fine-tune pre-trained model. We optimize null visual prompt for structual and style trajectory around pivotal noise on each timestep, ensuring accurate dual-path inversion reconstruction. Extensive evaluations on publicly available multi-domain unpaired staining datasets demonstrate high structural consistency and accurate style transfer results.
ReconfigISP: Reconfigurable Camera Image Processing Pipeline
Sep 10, 2021

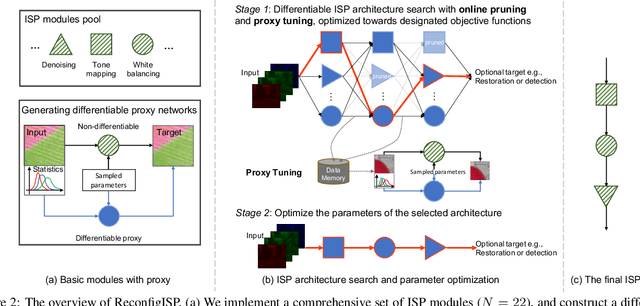
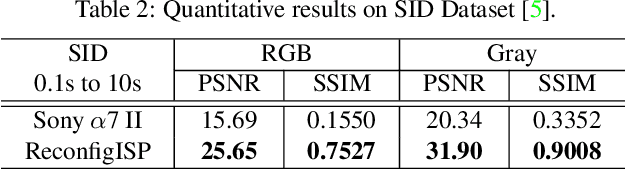
Image Signal Processor (ISP) is a crucial component in digital cameras that transforms sensor signals into images for us to perceive and understand. Existing ISP designs always adopt a fixed architecture, e.g., several sequential modules connected in a rigid order. Such a fixed ISP architecture may be suboptimal for real-world applications, where camera sensors, scenes and tasks are diverse. In this study, we propose a novel Reconfigurable ISP (ReconfigISP) whose architecture and parameters can be automatically tailored to specific data and tasks. In particular, we implement several ISP modules, and enable backpropagation for each module by training a differentiable proxy, hence allowing us to leverage the popular differentiable neural architecture search and effectively search for the optimal ISP architecture. A proxy tuning mechanism is adopted to maintain the accuracy of proxy networks in all cases. Extensive experiments conducted on image restoration and object detection, with different sensors, light conditions and efficiency constraints, validate the effectiveness of ReconfigISP. Only hundreds of parameters need tuning for every task.
Fast K-Means Clustering with Anderson Acceleration
May 27, 2018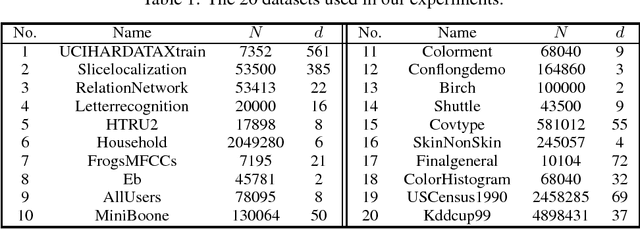
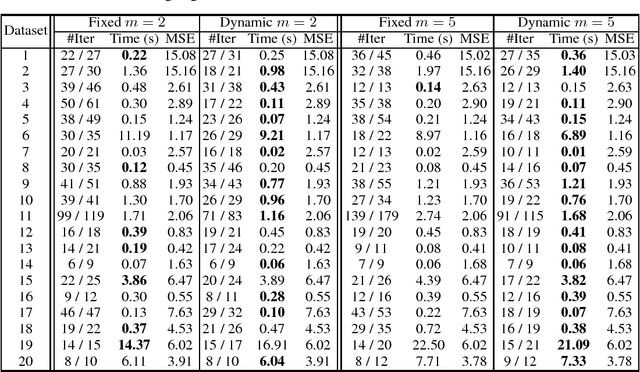
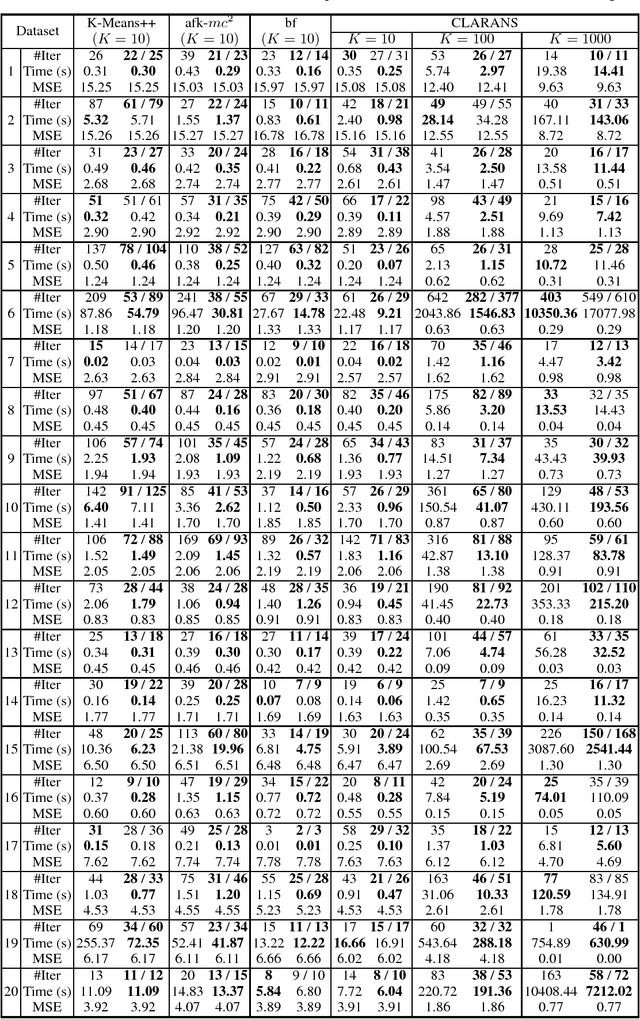
We propose a novel method to accelerate Lloyd's algorithm for K-Means clustering. Unlike previous acceleration approaches that reduce computational cost per iterations or improve initialization, our approach is focused on reducing the number of iterations required for convergence. This is achieved by treating the assignment step and the update step of Lloyd's algorithm as a fixed-point iteration, and applying Anderson acceleration, a well-established technique for accelerating fixed-point solvers. Classical Anderson acceleration utilizes m previous iterates to find an accelerated iterate, and its performance on K-Means clustering can be sensitive to choice of m and the distribution of samples. We propose a new strategy to dynamically adjust the value of m, which achieves robust and consistent speedups across different problem instances. Our method complements existing acceleration techniques, and can be combined with them to achieve state-of-the-art performance. We perform extensive experiments to evaluate the performance of the proposed method, where it outperforms other algorithms in 106 out of 120 test cases, and the mean decrease ratio of computational time is more than 33%.