 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgREE: Agentic Reasoning for Knowledge Graph Completion on Emerging Entities
Aug 06, 2025Open-domain Knowledge Graph Completion (KGC) faces significant challenges in an ever-changing world, especially when considering the continual emergence of new entities in daily news. Existing approaches for KGC mainly rely on pretrained language models' parametric knowledge, pre-constructed queries, or single-step retrieval, typically requiring substantial supervision and training data. Even so, they often fail to capture comprehensive and up-to-date information about unpopular and/or emerging entities. To this end, we introduce Agentic Reasoning for Emerging Entities (AgREE), a novel agent-based framework that combines iterative retrieval actions and multi-step reasoning to dynamically construct rich knowledge graph triplets. Experiments show that, despite requiring zero training efforts, AgREE significantly outperforms existing methods in constructing knowledge graph triplets, especially for emerging entities that were not seen during language models' training processes, outperforming previous methods by up to 13.7%. Moreover, we propose a new evaluation methodology that addresses a fundamental weakness of existing setups and a new benchmark for KGC on emerging entities. Our work demonstrates the effectiveness of combining agent-based reasoning with strategic information retrieval for maintaining up-to-date knowledge graphs in dynamic information environments.
Interleaved Reasoning for Large Language Models via Reinforcement Learning
May 26, 2025Long chain-of-thought (CoT) significantly enhances large language models' (LLM) reasoning capabilities. However, the extensive reasoning traces lead to inefficiencies and an increased time-to-first-token (TTFT). We propose a novel training paradigm that uses reinforcement learning (RL) to guide reasoning LLMs to interleave thinking and answering for multi-hop questions. We observe that models inherently possess the ability to perform interleaved reasoning, which can be further enhanced through RL. We introduce a simple yet effective rule-based reward to incentivize correct intermediate steps, which guides the policy model toward correct reasoning paths by leveraging intermediate signals generated during interleaved reasoning. Extensive experiments conducted across five diverse datasets and three RL algorithms (PPO, GRPO, and REINFORCE++) demonstrate consistent improvements over traditional think-answer reasoning, without requiring external tools. Specifically, our approach reduces TTFT by over 80% on average and improves up to 19.3% in Pass@1 accuracy. Furthermore, our method, trained solely on question answering and logical reasoning datasets, exhibits strong generalization ability to complex reasoning datasets such as MATH, GPQA, and MMLU. Additionally, we conduct in-depth analysis to reveal several valuable insights into conditional reward modeling.
Comprehensive Evaluation for a Large Scale Knowledge Graph Question Answering Service
Jan 28, 2025



Question answering systems for knowledge graph (KGQA), answer factoid questions based on the data in the knowledge graph. KGQA systems are complex because the system has to understand the relations and entities in the knowledge-seeking natural language queries and map them to structured queries against the KG to answer them. In this paper, we introduce Chronos, a comprehensive evaluation framework for KGQA at industry scale. It is designed to evaluate such a multi-component system comprehensively, focusing on (1) end-to-end and component-level metrics, (2) scalable to diverse datasets and (3) a scalable approach to measure the performance of the system prior to release. In this paper, we discuss the unique challenges associated with evaluating KGQA systems at industry scale, review the design of Chronos, and how it addresses these challenges. We will demonstrate how it provides a base for data-driven decisions and discuss the challenges of using it to measure and improve a real-world KGQA system.
KG-TRICK: Unifying Textual and Relational Information Completion of Knowledge for Multilingual Knowledge Graphs
Jan 07, 2025



Multilingual knowledge graphs (KGs) provide high-quality relational and textual information for various NLP applications, but they are often incomplete, especially in non-English languages. Previous research has shown that combining information from KGs in different languages aids either Knowledge Graph Completion (KGC), the task of predicting missing relations between entities, or Knowledge Graph Enhancement (KGE), the task of predicting missing textual information for entities. Although previous efforts have considered KGC and KGE as independent tasks, we hypothesize that they are interdependent and mutually beneficial. To this end, we introduce KG-TRICK, a novel sequence-to-sequence framework that unifies the tasks of textual and relational information completion for multilingual KGs. KG-TRICK demonstrates that: i) it is possible to unify the tasks of KGC and KGE into a single framework, and ii) combining textual information from multiple languages is beneficial to improve the completeness of a KG. As part of our contributions, we also introduce WikiKGE10++, the largest manually-curated benchmark for textual information completion of KGs, which features over 25,000 entities across 10 diverse languages.
Do Large Language Models Have an English Accent? Evaluating and Improving the Naturalness of Multilingual LLMs
Oct 21, 2024



Current Large Language Models (LLMs) are predominantly designed with English as the primary language, and even the few that are multilingual tend to exhibit strong English-centric biases. Much like speakers who might produce awkward expressions when learning a second language, LLMs often generate unnatural outputs in non-English languages, reflecting English-centric patterns in both vocabulary and grammar. Despite the importance of this issue, the naturalness of multilingual LLM outputs has received limited attention. In this paper, we address this gap by introducing novel automatic corpus-level metrics to assess the lexical and syntactic naturalness of LLM outputs in a multilingual context. Using our new metrics, we evaluate state-of-the-art LLMs on a curated benchmark in French and Chinese, revealing a tendency towards English-influenced patterns. To mitigate this issue, we also propose a simple and effective alignment method to improve the naturalness of an LLM in a target language and domain, achieving consistent improvements in naturalness without compromising the performance on general-purpose benchmarks. Our work highlights the importance of developing multilingual metrics, resources and methods for the new wave of multilingual LLMs.
Towards Cross-Cultural Machine Translation with Retrieval-Augmented Generation from Multilingual Knowledge Graphs
Oct 17, 2024



Translating text that contains entity names is a challenging task, as cultural-related references can vary significantly across languages. These variations may also be caused by transcreation, an adaptation process that entails more than transliteration and word-for-word translation. In this paper, we address the problem of cross-cultural translation on two fronts: (i) we introduce XC-Translate, the first large-scale, manually-created benchmark for machine translation that focuses on text that contains potentially culturally-nuanced entity names, and (ii) we propose KG-MT, a novel end-to-end method to integrate information from a multilingual knowledge graph into a neural machine translation model by leveraging a dense retrieval mechanism. Our experiments and analyses show that current machine translation systems and large language models still struggle to translate texts containing entity names, whereas KG-MT outperforms state-of-the-art approaches by a large margin, obtaining a 129% and 62% relative improvement compared to NLLB-200 and GPT-4, respectively.
ConvKGYarn: Spinning Configurable and Scalable Conversational Knowledge Graph QA datasets with Large Language Models
Aug 12, 2024



The rapid advancement of Large Language Models (LLMs) and conversational assistants necessitates dynamic, scalable, and configurable conversational datasets for training and evaluation. These datasets must accommodate diverse user interaction modes, including text and voice, each presenting unique modeling challenges. Knowledge Graphs (KGs), with their structured and evolving nature, offer an ideal foundation for current and precise knowledge. Although human-curated KG-based conversational datasets exist, they struggle to keep pace with the rapidly changing user information needs. We present ConvKGYarn, a scalable method for generating up-to-date and configurable conversational KGQA datasets. Qualitative psychometric analyses confirm our method can generate high-quality datasets rivaling a popular conversational KGQA dataset while offering it at scale and covering a wide range of human-interaction configurations. We showcase its utility by testing LLMs on diverse conversations - exploring model behavior on conversational KGQA sets with different configurations grounded in the same KG fact set. Our results highlight the ability of ConvKGYarn to improve KGQA foundations and evaluate parametric knowledge of LLMs, thus offering a robust solution to the constantly evolving landscape of conversational assistants.
AGRaME: Any-Granularity Ranking with Multi-Vector Embeddings
May 23, 2024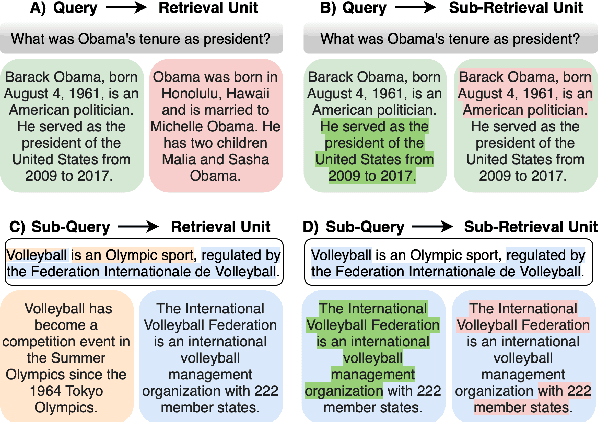


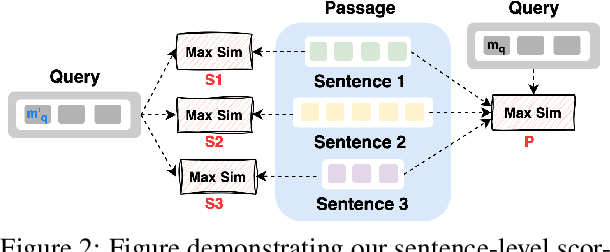
Ranking is a fundamental and popular problem in search. However, existing ranking algorithms usually restrict the granularity of ranking to full passages or require a specific dense index for each desired level of granularity. Such lack of flexibility in granularity negatively affects many applications that can benefit from more granular ranking, such as sentence-level ranking for open-domain question-answering, or proposition-level ranking for attribution. In this work, we introduce the idea of any-granularity ranking, which leverages multi-vector embeddings to rank at varying levels of granularity while maintaining encoding at a single (coarser) level of granularity. We propose a multi-granular contrastive loss for training multi-vector approaches, and validate its utility with both sentences and propositions as ranking units. Finally, we demonstrate the application of proposition-level ranking to post-hoc citation addition in retrieval-augmented generation, surpassing the performance of prompt-driven citation generation.
Entity Disambiguation via Fusion Entity Decoding
Apr 02, 2024
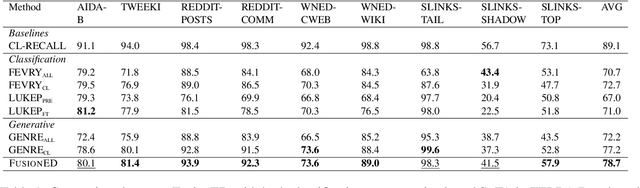


Entity disambiguation (ED), which links the mentions of ambiguous entities to their referent entities in a knowledge base, serves as a core component in entity linking (EL). Existing generative approaches demonstrate improved accuracy compared to classification approaches under the standardized ZELDA benchmark. Nevertheless, generative approaches suffer from the need for large-scale pre-training and inefficient generation. Most importantly, entity descriptions, which could contain crucial information to distinguish similar entities from each other, are often overlooked. We propose an encoder-decoder model to disambiguate entities with more detailed entity descriptions. Given text and candidate entities, the encoder learns interactions between the text and each candidate entity, producing representations for each entity candidate. The decoder then fuses the representations of entity candidates together and selects the correct entity. Our experiments, conducted on various entity disambiguation benchmarks, demonstrate the strong and robust performance of this model, particularly +1.5% in the ZELDA benchmark compared with GENRE. Furthermore, we integrate this approach into the retrieval/reader framework and observe +1.5% improvements in end-to-end entity linking in the GERBIL benchmark compared with EntQA.
Distinguish Sense from Nonsense: Out-of-Scope Detection for Virtual Assistants
Jan 16, 2023Out of Scope (OOS) detection in Conversational AI solutions enables a chatbot to handle a conversation gracefully when it is unable to make sense of the end-user query. Accurately tagging a query as out-of-domain is particularly hard in scenarios when the chatbot is not equipped to handle a topic which has semantic overlap with an existing topic it is trained on. We propose a simple yet effective OOS detection method that outperforms standard OOS detection methods in a real-world deployment of virtual assistants. We discuss the various design and deployment considerations for a cloud platform solution to train virtual assistants and deploy them at scale. Additionally, we propose a collection of datasets that replicates real-world scenarios and show comprehensive results in various settings using both offline and online evaluation metrics.