 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Linguistic Diversity of Large Language Models
Dec 13, 2024



The development and evaluation of Large Language Models (LLMs) has primarily focused on their task-solving capabilities, with recent models even surpassing human performance in some areas. However, this focus often neglects whether machine-generated language matches the human level of diversity, in terms of vocabulary choice, syntactic construction, and expression of meaning, raising questions about whether the fundamentals of language generation have been fully addressed. This paper emphasizes the importance of examining the preservation of human linguistic richness by language models, given the concerning surge in online content produced or aided by LLMs. We propose a comprehensive framework for evaluating LLMs from various linguistic diversity perspectives including lexical, syntactic, and semantic dimensions. Using this framework, we benchmark several state-of-the-art LLMs across all diversity dimensions, and conduct an in-depth case study for syntactic diversity. Finally, we analyze how different development and deployment choices impact the linguistic diversity of LLM outputs.
Do Large Language Models Have an English Accent? Evaluating and Improving the Naturalness of Multilingual LLMs
Oct 21, 2024



Current Large Language Models (LLMs) are predominantly designed with English as the primary language, and even the few that are multilingual tend to exhibit strong English-centric biases. Much like speakers who might produce awkward expressions when learning a second language, LLMs often generate unnatural outputs in non-English languages, reflecting English-centric patterns in both vocabulary and grammar. Despite the importance of this issue, the naturalness of multilingual LLM outputs has received limited attention. In this paper, we address this gap by introducing novel automatic corpus-level metrics to assess the lexical and syntactic naturalness of LLM outputs in a multilingual context. Using our new metrics, we evaluate state-of-the-art LLMs on a curated benchmark in French and Chinese, revealing a tendency towards English-influenced patterns. To mitigate this issue, we also propose a simple and effective alignment method to improve the naturalness of an LLM in a target language and domain, achieving consistent improvements in naturalness without compromising the performance on general-purpose benchmarks. Our work highlights the importance of developing multilingual metrics, resources and methods for the new wave of multilingual LLMs.
Automatic Analysis of Substantiation in Scientific Peer Reviews
Nov 20, 2023With the increasing amount of problematic peer reviews in top AI conferences, the community is urgently in need of automatic quality control measures. In this paper, we restrict our attention to substantiation -- one popular quality aspect indicating whether the claims in a review are sufficiently supported by evidence -- and provide a solution automatizing this evaluation process. To achieve this goal, we first formulate the problem as claim-evidence pair extraction in scientific peer reviews, and collect SubstanReview, the first annotated dataset for this task. SubstanReview consists of 550 reviews from NLP conferences annotated by domain experts. On the basis of this dataset, we train an argument mining system to automatically analyze the level of substantiation in peer reviews. We also perform data analysis on the SubstanReview dataset to obtain meaningful insights on peer reviewing quality in NLP conferences over recent years.
The Curious Decline of Linguistic Diversity: Training Language Models on Synthetic Text
Nov 16, 2023This study investigates the consequences of training large language models (LLMs) on synthetic data generated by their predecessors, an increasingly prevalent practice aimed at addressing the limited supply of human-generated training data. Diverging from the usual emphasis on performance metrics, we focus on the impact of this training methodology on linguistic diversity, especially when conducted recursively over time. To assess this, we developed a set of novel metrics targeting lexical, syntactic, and semantic diversity, applying them in recursive fine-tuning experiments across various natural language generation tasks. Our findings reveal a marked decrease in the diversity of the models' outputs through successive iterations. This trend underscores the potential risks of training LLMs on predecessor-generated text, particularly concerning the preservation of linguistic richness. Our study highlights the need for careful consideration of the long-term effects of such training approaches on the linguistic capabilities of LLMs.
Questioning the Validity of Summarization Datasets and Improving Their Factual Consistency
Oct 31, 2022The topic of summarization evaluation has recently attracted a surge of attention due to the rapid development of abstractive summarization systems. However, the formulation of the task is rather ambiguous, neither the linguistic nor the natural language processing community has succeeded in giving a mutually agreed-upon definition. Due to this lack of well-defined formulation, a large number of popular abstractive summarization datasets are constructed in a manner that neither guarantees validity nor meets one of the most essential criteria of summarization: factual consistency. In this paper, we address this issue by combining state-of-the-art factual consistency models to identify the problematic instances present in popular summarization datasets. We release SummFC, a filtered summarization dataset with improved factual consistency, and demonstrate that models trained on this dataset achieve improved performance in nearly all quality aspects. We argue that our dataset should become a valid benchmark for developing and evaluating summarization systems.
Political Communities on Twitter: Case Study of the 2022 French Presidential Election
Apr 15, 2022
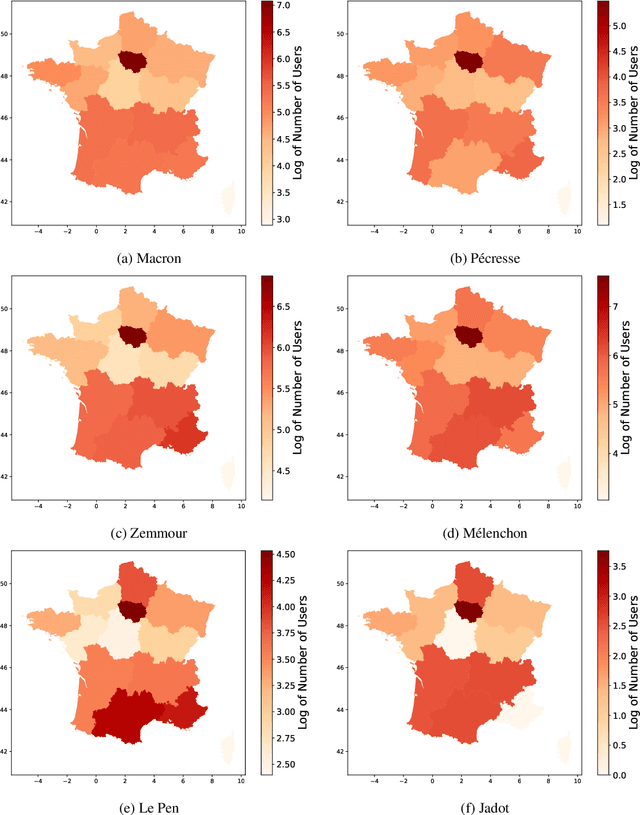
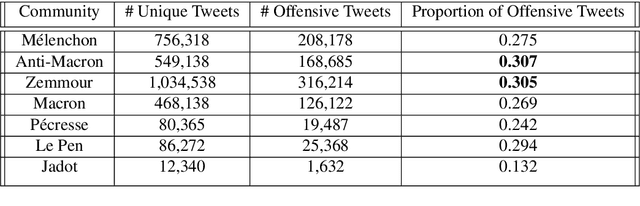
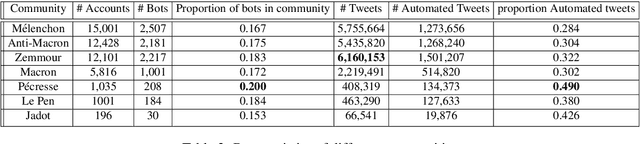
With the significant increase in users on social media platforms, a new means of political campaigning has appeared. Twitter and Facebook are now notable campaigning tools during elections. Indeed, the candidates and their parties now take to the internet to interact and spread their ideas. In this paper, we aim to identify political communities formed on Twitter during the 2022 French presidential election and analyze each respective community. We create a large-scale Twitter dataset containing 1.2 million users and 62.6 million tweets that mention keywords relevant to the election. We perform community detection on a retweet graph of users and propose an in-depth analysis of the stance of each community. Finally, we attempt to detect offensive tweets and automatic bots, comparing across communities in order to gain insight into each candidate's supporter demographics and online campaign strategy.
NLP Research and Resources at DaSciM, Ecole Polytechnique
Dec 01, 2021DaSciM (Data Science and Mining) part of LIX at Ecole Polytechnique, established in 2013 and since then producing research results in the area of large scale data analysis via methods of machine and deep learning. The group has been specifically active in the area of NLP and text mining with interesting results at methodological and resources level. Here follow our different contributions of interest to the AFIA community.
BERTweetFR : Domain Adaptation of Pre-Trained Language Models for French Tweets
Sep 21, 2021

We introduce BERTweetFR, the first large-scale pre-trained language model for French tweets. Our model is initialized using the general-domain French language model CamemBERT which follows the base architecture of RoBERTa. Experiments show that BERTweetFR outperforms all previous general-domain French language models on two downstream Twitter NLP tasks of offensiveness identification and named entity recognition. The dataset used in the offensiveness detection task is first created and annotated by our team, filling in the gap of such analytic datasets in French. We make our model publicly available in the transformers library with the aim of promoting future research in analytic tasks for French tweets.
How COVID-19 Is Changing Our Language : Detecting Semantic Shift in Twitter Word Embeddings
Feb 15, 2021
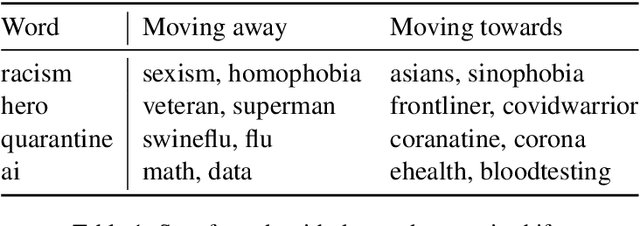
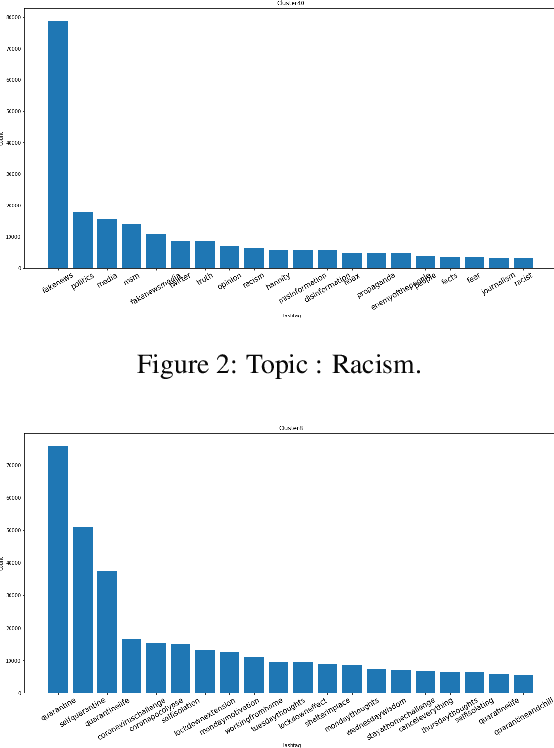
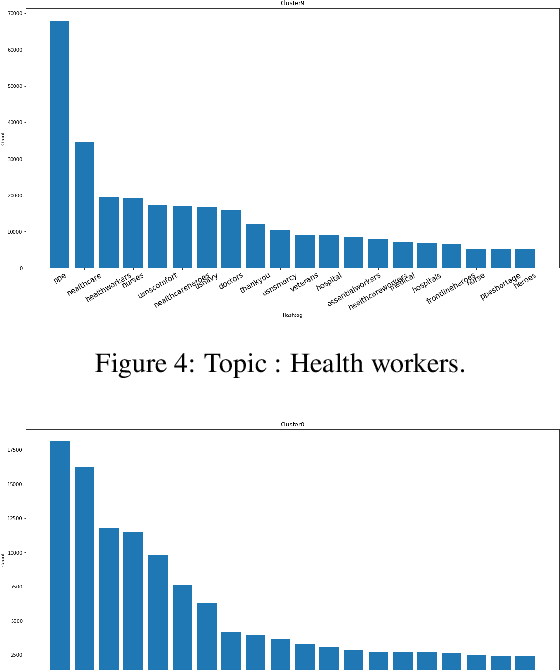
Words are malleable objects, influenced by events that are reflected in written texts. Situated in the global outbreak of COVID-19, our research aims at detecting semantic shifts in social media language triggered by the health crisis. With COVID-19 related big data extracted from Twitter, we train separate word embedding models for different time periods after the outbreak. We employ an alignment-based approach to compare these embeddings with a general-purpose Twitter embedding unrelated to COVID-19. We also compare our trained embeddings among them to observe diachronic evolution. Carrying out case studies on a set of words chosen by topic detection, we verify that our alignment approach is valid. Finally, we quantify the size of global semantic shift by a stability measure based on back-and-forth rotational alignment.