 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgREE: Agentic Reasoning for Knowledge Graph Completion on Emerging Entities
Aug 06, 2025Open-domain Knowledge Graph Completion (KGC) faces significant challenges in an ever-changing world, especially when considering the continual emergence of new entities in daily news. Existing approaches for KGC mainly rely on pretrained language models' parametric knowledge, pre-constructed queries, or single-step retrieval, typically requiring substantial supervision and training data. Even so, they often fail to capture comprehensive and up-to-date information about unpopular and/or emerging entities. To this end, we introduce Agentic Reasoning for Emerging Entities (AgREE), a novel agent-based framework that combines iterative retrieval actions and multi-step reasoning to dynamically construct rich knowledge graph triplets. Experiments show that, despite requiring zero training efforts, AgREE significantly outperforms existing methods in constructing knowledge graph triplets, especially for emerging entities that were not seen during language models' training processes, outperforming previous methods by up to 13.7%. Moreover, we propose a new evaluation methodology that addresses a fundamental weakness of existing setups and a new benchmark for KGC on emerging entities. Our work demonstrates the effectiveness of combining agent-based reasoning with strategic information retrieval for maintaining up-to-date knowledge graphs in dynamic information environments.
Right Answer, Wrong Score: Uncovering the Inconsistencies of LLM Evaluation in Multiple-Choice Question Answering
Mar 19, 2025



One of the most widely used tasks to evaluate Large Language Models (LLMs) is Multiple-Choice Question Answering (MCQA). While open-ended question answering tasks are more challenging to evaluate, MCQA tasks are, in principle, easier to assess, as the model's answer is thought to be simple to extract and is directly compared to a set of predefined choices. However, recent studies have started to question the reliability of MCQA evaluation, showing that multiple factors can significantly impact the reported performance of LLMs, especially when the model generates free-form text before selecting one of the answer choices. In this work, we shed light on the inconsistencies of MCQA evaluation strategies, which can lead to inaccurate and misleading model comparisons. We systematically analyze whether existing answer extraction methods are aligned with human judgment, and how they are influenced by answer constraints in the prompt across different domains. Our experiments demonstrate that traditional evaluation strategies often underestimate LLM capabilities, while LLM-based answer extractors are prone to systematic errors. Moreover, we reveal a fundamental trade-off between including format constraints in the prompt to simplify answer extraction and allowing models to generate free-form text to improve reasoning. Our findings call for standardized evaluation methodologies and highlight the need for more reliable and consistent MCQA evaluation practices.
KG-TRICK: Unifying Textual and Relational Information Completion of Knowledge for Multilingual Knowledge Graphs
Jan 07, 2025



Multilingual knowledge graphs (KGs) provide high-quality relational and textual information for various NLP applications, but they are often incomplete, especially in non-English languages. Previous research has shown that combining information from KGs in different languages aids either Knowledge Graph Completion (KGC), the task of predicting missing relations between entities, or Knowledge Graph Enhancement (KGE), the task of predicting missing textual information for entities. Although previous efforts have considered KGC and KGE as independent tasks, we hypothesize that they are interdependent and mutually beneficial. To this end, we introduce KG-TRICK, a novel sequence-to-sequence framework that unifies the tasks of textual and relational information completion for multilingual KGs. KG-TRICK demonstrates that: i) it is possible to unify the tasks of KGC and KGE into a single framework, and ii) combining textual information from multiple languages is beneficial to improve the completeness of a KG. As part of our contributions, we also introduce WikiKGE10++, the largest manually-curated benchmark for textual information completion of KGs, which features over 25,000 entities across 10 diverse languages.
Do Large Language Models Have an English Accent? Evaluating and Improving the Naturalness of Multilingual LLMs
Oct 21, 2024



Current Large Language Models (LLMs) are predominantly designed with English as the primary language, and even the few that are multilingual tend to exhibit strong English-centric biases. Much like speakers who might produce awkward expressions when learning a second language, LLMs often generate unnatural outputs in non-English languages, reflecting English-centric patterns in both vocabulary and grammar. Despite the importance of this issue, the naturalness of multilingual LLM outputs has received limited attention. In this paper, we address this gap by introducing novel automatic corpus-level metrics to assess the lexical and syntactic naturalness of LLM outputs in a multilingual context. Using our new metrics, we evaluate state-of-the-art LLMs on a curated benchmark in French and Chinese, revealing a tendency towards English-influenced patterns. To mitigate this issue, we also propose a simple and effective alignment method to improve the naturalness of an LLM in a target language and domain, achieving consistent improvements in naturalness without compromising the performance on general-purpose benchmarks. Our work highlights the importance of developing multilingual metrics, resources and methods for the new wave of multilingual LLMs.
Towards Cross-Cultural Machine Translation with Retrieval-Augmented Generation from Multilingual Knowledge Graphs
Oct 17, 2024



Translating text that contains entity names is a challenging task, as cultural-related references can vary significantly across languages. These variations may also be caused by transcreation, an adaptation process that entails more than transliteration and word-for-word translation. In this paper, we address the problem of cross-cultural translation on two fronts: (i) we introduce XC-Translate, the first large-scale, manually-created benchmark for machine translation that focuses on text that contains potentially culturally-nuanced entity names, and (ii) we propose KG-MT, a novel end-to-end method to integrate information from a multilingual knowledge graph into a neural machine translation model by leveraging a dense retrieval mechanism. Our experiments and analyses show that current machine translation systems and large language models still struggle to translate texts containing entity names, whereas KG-MT outperforms state-of-the-art approaches by a large margin, obtaining a 129% and 62% relative improvement compared to NLLB-200 and GPT-4, respectively.
ZEBRA: Zero-Shot Example-Based Retrieval Augmentation for Commonsense Question Answering
Oct 07, 2024Current Large Language Models (LLMs) have shown strong reasoning capabilities in commonsense question answering benchmarks, but the process underlying their success remains largely opaque. As a consequence, recent approaches have equipped LLMs with mechanisms for knowledge retrieval, reasoning and introspection, not only to improve their capabilities but also to enhance the interpretability of their outputs. However, these methods require additional training, hand-crafted templates or human-written explanations. To address these issues, we introduce ZEBRA, a zero-shot question answering framework that combines retrieval, case-based reasoning and introspection and dispenses with the need for additional training of the LLM. Given an input question, ZEBRA retrieves relevant question-knowledge pairs from a knowledge base and generates new knowledge by reasoning over the relationships in these pairs. This generated knowledge is then used to answer the input question, improving the model's performance and interpretability. We evaluate our approach across 8 well-established commonsense reasoning benchmarks, demonstrating that ZEBRA consistently outperforms strong LLMs and previous knowledge integration approaches, achieving an average accuracy improvement of up to 4.5 points.
Increasing Coverage and Precision of Textual Information in Multilingual Knowledge Graphs
Nov 27, 2023



Recent work in Natural Language Processing and Computer Vision has been using textual information -- e.g., entity names and descriptions -- available in knowledge graphs to ground neural models to high-quality structured data. However, when it comes to non-English languages, the quantity and quality of textual information are comparatively scarce. To address this issue, we introduce the novel task of automatic Knowledge Graph Enhancement (KGE) and perform a thorough investigation on bridging the gap in both the quantity and quality of textual information between English and non-English languages. More specifically, we: i) bring to light the problem of increasing multilingual coverage and precision of entity names and descriptions in Wikidata; ii) demonstrate that state-of-the-art methods, namely, Machine Translation (MT), Web Search (WS), and Large Language Models (LLMs), struggle with this task; iii) present M-NTA, a novel unsupervised approach that combines MT, WS, and LLMs to generate high-quality textual information; and, iv) study the impact of increasing multilingual coverage and precision of non-English textual information in Entity Linking, Knowledge Graph Completion, and Question Answering. As part of our effort towards better multilingual knowledge graphs, we also introduce WikiKGE-10, the first human-curated benchmark to evaluate KGE approaches in 10 languages across 7 language families.
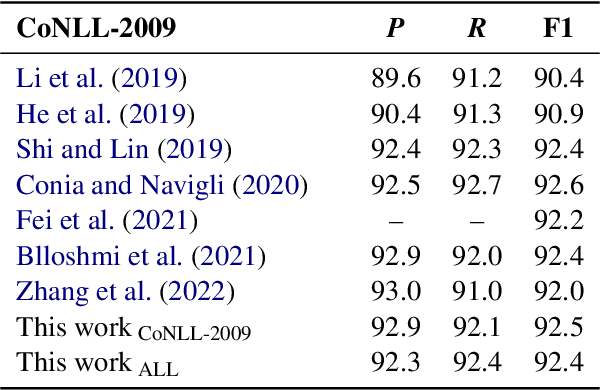
Exploring Non-Verbal Predicates in Semantic Role Labeling: Challenges and Opportunities
Jul 04, 2023

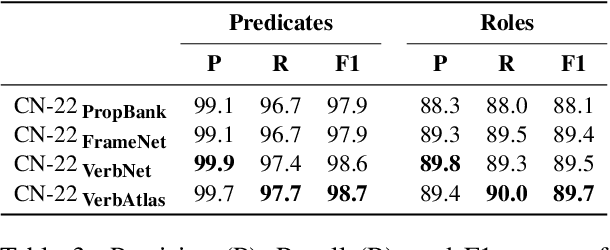
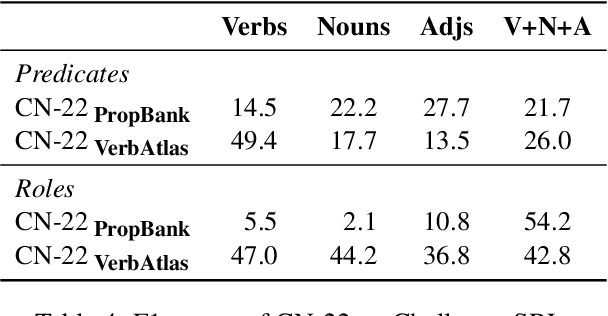
Although we have witnessed impressive progress in Semantic Role Labeling (SRL), most of the research in the area is carried out assuming that the majority of predicates are verbs. Conversely, predicates can also be expressed using other parts of speech, e.g., nouns and adjectives. However, non-verbal predicates appear in the benchmarks we commonly use to measure progress in SRL less frequently than in some real-world settings -- newspaper headlines, dialogues, and tweets, among others. In this paper, we put forward a new PropBank dataset which boasts wide coverage of multiple predicate types. Thanks to it, we demonstrate empirically that standard benchmarks do not provide an accurate picture of the current situation in SRL and that state-of-the-art systems are still incapable of transferring knowledge across different predicate types. Having observed these issues, we also present a novel, manually-annotated challenge set designed to give equal importance to verbal, nominal, and adjectival predicate-argument structures. We use such dataset to investigate whether we can leverage different linguistic resources to promote knowledge transfer. In conclusion, we claim that SRL is far from "solved", and its integration with other semantic tasks might enable significant improvements in the future, especially for the long tail of non-verbal predicates, thereby facilitating further research on SRL for non-verbal predicates.
Echoes from Alexandria: A Large Resource for Multilingual Book Summarization
Jun 07, 2023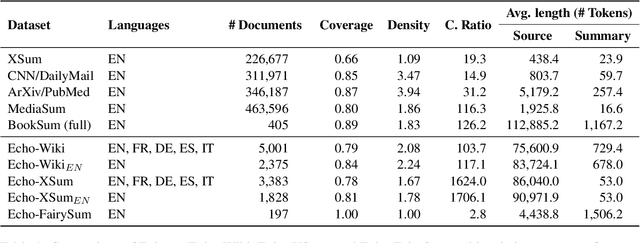
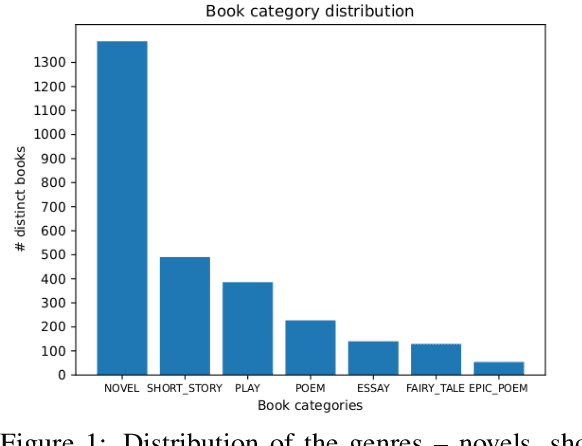
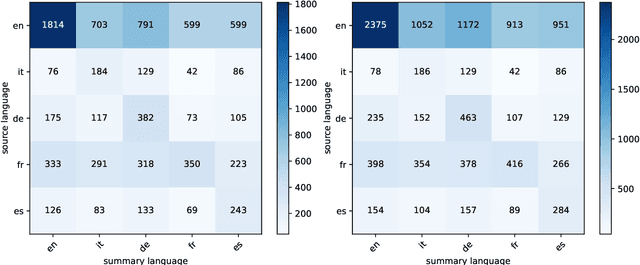
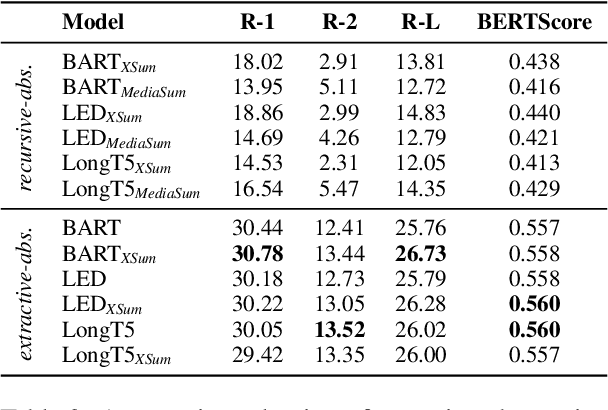
In recent years, research in text summarization has mainly focused on the news domain, where texts are typically short and have strong layout features. The task of full-book summarization presents additional challenges which are hard to tackle with current resources, due to their limited size and availability in English only. To overcome these limitations, we present "Echoes from Alexandria", or in shortened form, "Echoes", a large resource for multilingual book summarization. Echoes features three novel datasets: i) Echo-Wiki, for multilingual book summarization, ii) Echo-XSum, for extremely-compressive multilingual book summarization, and iii) Echo-FairySum, for extractive book summarization. To the best of our knowledge, Echoes, with its thousands of books and summaries, is the largest resource, and the first to be multilingual, featuring 5 languages and 25 language pairs. In addition to Echoes, we also introduce a new extractive-then-abstractive baseline, and, supported by our experimental results and manual analysis of the summaries generated, we argue that this baseline is more suitable for book summarization than purely-abstractive approaches. We release our resource and software at https://github.com/Babelscape/echoes-from-alexandria in the hope of fostering innovative research in multilingual book summarization.
Semantic Role Labeling Meets Definition Modeling: Using Natural Language to Describe Predicate-Argument Structures
Dec 02, 2022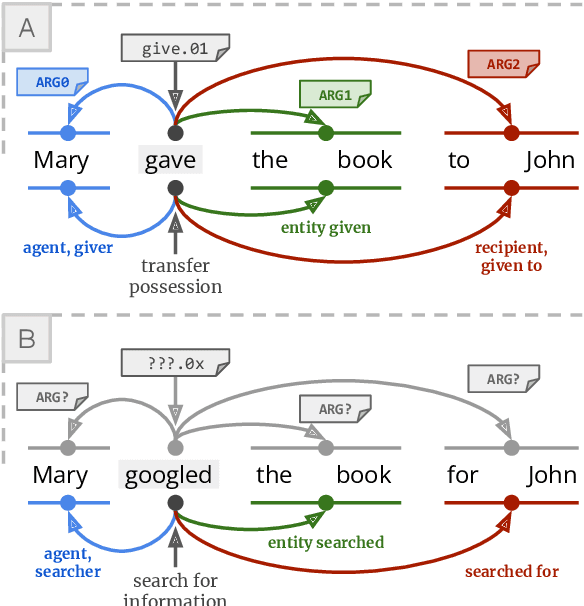
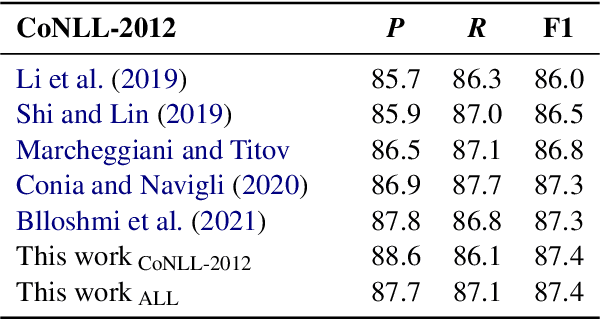
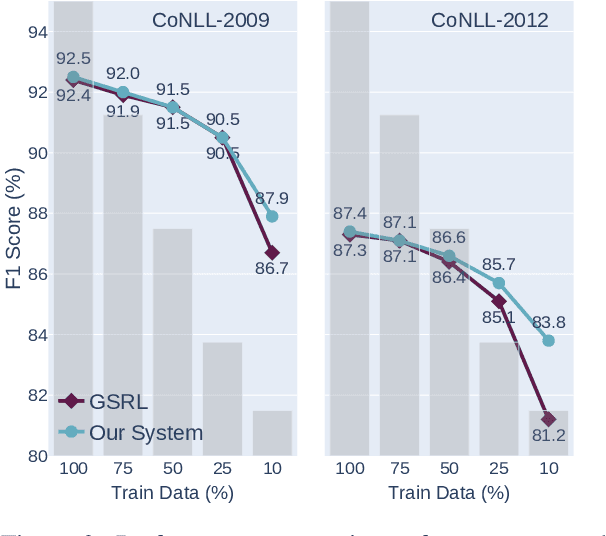
One of the common traits of past and present approaches for Semantic Role Labeling (SRL) is that they rely upon discrete labels drawn from a predefined linguistic inventory to classify predicate senses and their arguments. However, we argue this need not be the case. In this paper, we present an approach that leverages Definition Modeling to introduce a generalized formulation of SRL as the task of describing predicate-argument structures using natural language definitions instead of discrete labels. Our novel formulation takes a first step towards placing interpretability and flexibility foremost, and yet our experiments and analyses on PropBank-style and FrameNet-style, dependency-based and span-based SRL also demonstrate that a flexible model with an interpretable output does not necessarily come at the expense of performance. We release our software for research purposes at https://github.com/SapienzaNLP/dsrl.