 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRight Answer, Wrong Score: Uncovering the Inconsistencies of LLM Evaluation in Multiple-Choice Question Answering
Mar 19, 2025



One of the most widely used tasks to evaluate Large Language Models (LLMs) is Multiple-Choice Question Answering (MCQA). While open-ended question answering tasks are more challenging to evaluate, MCQA tasks are, in principle, easier to assess, as the model's answer is thought to be simple to extract and is directly compared to a set of predefined choices. However, recent studies have started to question the reliability of MCQA evaluation, showing that multiple factors can significantly impact the reported performance of LLMs, especially when the model generates free-form text before selecting one of the answer choices. In this work, we shed light on the inconsistencies of MCQA evaluation strategies, which can lead to inaccurate and misleading model comparisons. We systematically analyze whether existing answer extraction methods are aligned with human judgment, and how they are influenced by answer constraints in the prompt across different domains. Our experiments demonstrate that traditional evaluation strategies often underestimate LLM capabilities, while LLM-based answer extractors are prone to systematic errors. Moreover, we reveal a fundamental trade-off between including format constraints in the prompt to simplify answer extraction and allowing models to generate free-form text to improve reasoning. Our findings call for standardized evaluation methodologies and highlight the need for more reliable and consistent MCQA evaluation practices.
Truth or Mirage? Towards End-to-End Factuality Evaluation with LLM-Oasis
Dec 02, 2024After the introduction of Large Language Models (LLMs), there have been substantial improvements in the performance of Natural Language Generation (NLG) tasks, including Text Summarization and Machine Translation. However, LLMs still produce outputs containing hallucinations, that is, content not grounded in factual information. Therefore, developing methods to assess the factuality of LLMs has become urgent. Indeed, resources for factuality evaluation have recently emerged. Although challenging, these resources face one or more of the following limitations: (i) they are tailored to a specific task or domain; (ii) they are limited in size, thereby preventing the training of new factuality evaluators; (iii) they are designed for simpler verification tasks, such as claim verification. To address these issues, we introduce LLM-Oasis, to the best of our knowledge the largest resource for training end-to-end factuality evaluators. LLM-Oasis is constructed by extracting claims from Wikipedia, falsifying a subset of these claims, and generating pairs of factual and unfactual texts. We then rely on human annotators to both validate the quality of our dataset and to create a gold standard test set for benchmarking factuality evaluation systems. Our experiments demonstrate that LLM-Oasis presents a significant challenge for state-of-the-art LLMs, with GPT-4o achieving up to 60% accuracy in our proposed end-to-end factuality evaluation task, highlighting its potential to drive future research in the field.
Guardians of the Machine Translation Meta-Evaluation: Sentinel Metrics Fall In!
Aug 25, 2024
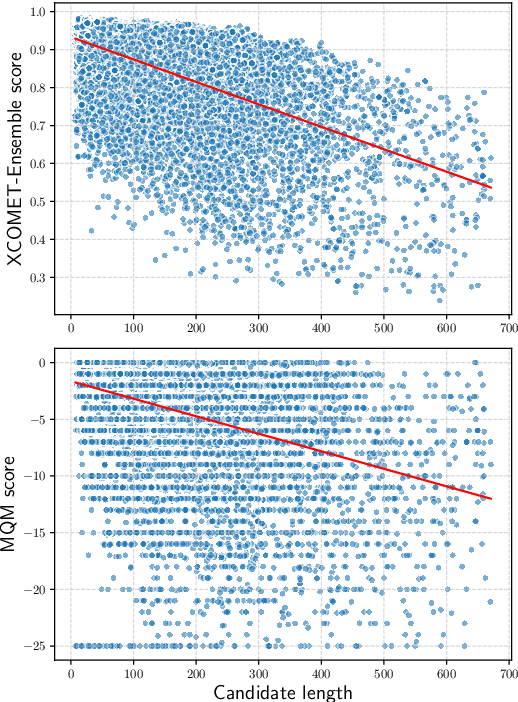

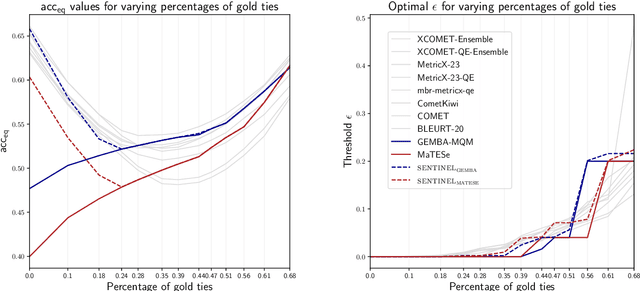
Annually, at the Conference of Machine Translation (WMT), the Metrics Shared Task organizers conduct the meta-evaluation of Machine Translation (MT) metrics, ranking them according to their correlation with human judgments. Their results guide researchers toward enhancing the next generation of metrics and MT systems. With the recent introduction of neural metrics, the field has witnessed notable advancements. Nevertheless, the inherent opacity of these metrics has posed substantial challenges to the meta-evaluation process. This work highlights two issues with the meta-evaluation framework currently employed in WMT, and assesses their impact on the metrics rankings. To do this, we introduce the concept of sentinel metrics, which are designed explicitly to scrutinize the meta-evaluation process's accuracy, robustness, and fairness. By employing sentinel metrics, we aim to validate our findings, and shed light on and monitor the potential biases or inconsistencies in the rankings. We discover that the present meta-evaluation framework favors two categories of metrics: i) those explicitly trained to mimic human quality assessments, and ii) continuous metrics. Finally, we raise concerns regarding the evaluation capabilities of state-of-the-art metrics, emphasizing that they might be basing their assessments on spurious correlations found in their training data.
FENICE: Factuality Evaluation of summarization based on Natural language Inference and Claim Extraction
Mar 04, 2024

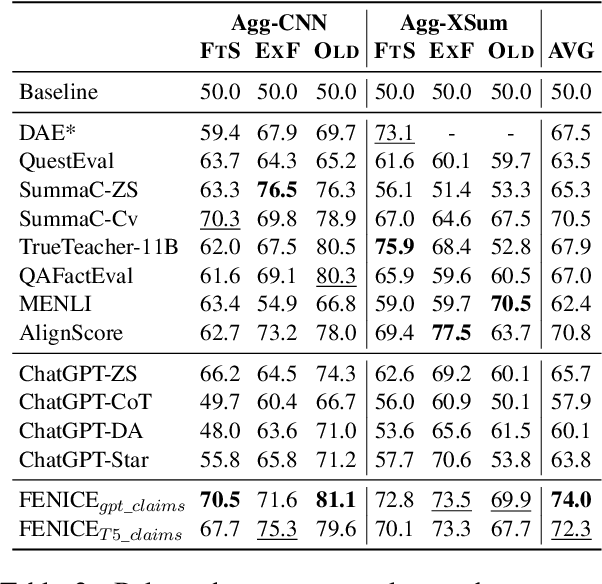

Recent advancements in text summarization, particularly with the advent of Large Language Models (LLMs), have shown remarkable performance. However, a notable challenge persists as a substantial number of automatically-generated summaries exhibit factual inconsistencies, such as hallucinations. In response to this issue, various approaches for the evaluation of consistency for summarization have emerged. Yet, these newly-introduced metrics face several limitations, including lack of interpretability, focus on short document summaries (e.g., news articles), and computational impracticality, especially for LLM-based metrics. To address these shortcomings, we propose Factuality Evaluation of summarization based on Natural language Inference and Claim Extraction (FENICE), a more interpretable and efficient factuality-oriented metric. FENICE leverages an NLI-based alignment between information in the source document and a set of atomic facts, referred to as claims, extracted from the summary. Our metric sets a new state of the art on AGGREFACT, the de-facto benchmark for factuality evaluation. Moreover, we extend our evaluation to a more challenging setting by conducting a human annotation process of long-form summarization.
Echoes from Alexandria: A Large Resource for Multilingual Book Summarization
Jun 07, 2023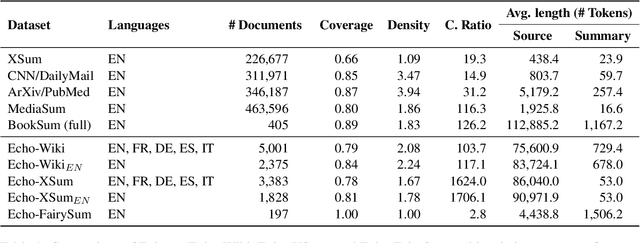
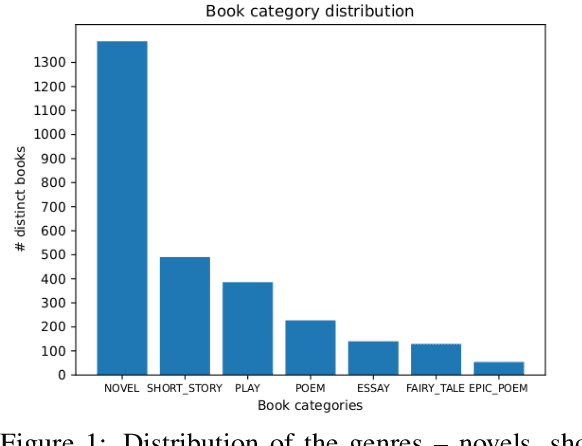
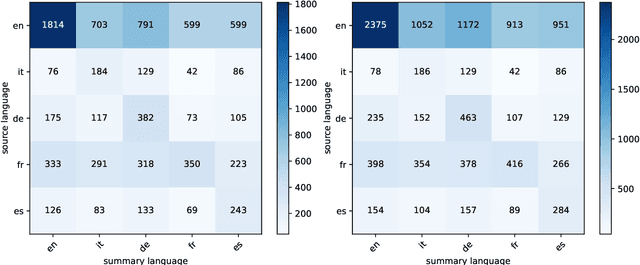
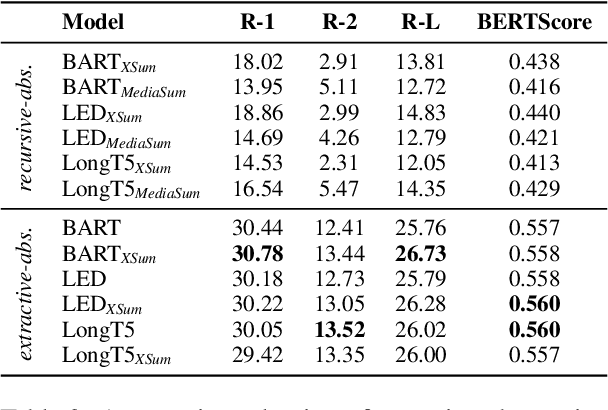
In recent years, research in text summarization has mainly focused on the news domain, where texts are typically short and have strong layout features. The task of full-book summarization presents additional challenges which are hard to tackle with current resources, due to their limited size and availability in English only. To overcome these limitations, we present "Echoes from Alexandria", or in shortened form, "Echoes", a large resource for multilingual book summarization. Echoes features three novel datasets: i) Echo-Wiki, for multilingual book summarization, ii) Echo-XSum, for extremely-compressive multilingual book summarization, and iii) Echo-FairySum, for extractive book summarization. To the best of our knowledge, Echoes, with its thousands of books and summaries, is the largest resource, and the first to be multilingual, featuring 5 languages and 25 language pairs. In addition to Echoes, we also introduce a new extractive-then-abstractive baseline, and, supported by our experimental results and manual analysis of the summaries generated, we argue that this baseline is more suitable for book summarization than purely-abstractive approaches. We release our resource and software at https://github.com/Babelscape/echoes-from-alexandria in the hope of fostering innovative research in multilingual book summarization.
Semantic Role Labeling Meets Definition Modeling: Using Natural Language to Describe Predicate-Argument Structures
Dec 02, 2022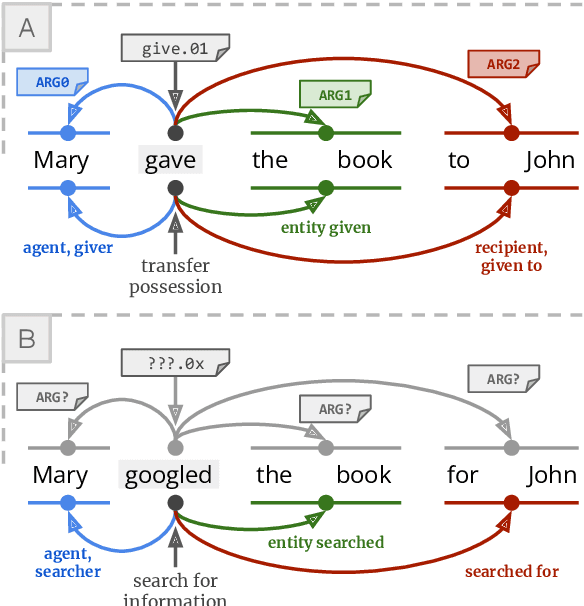
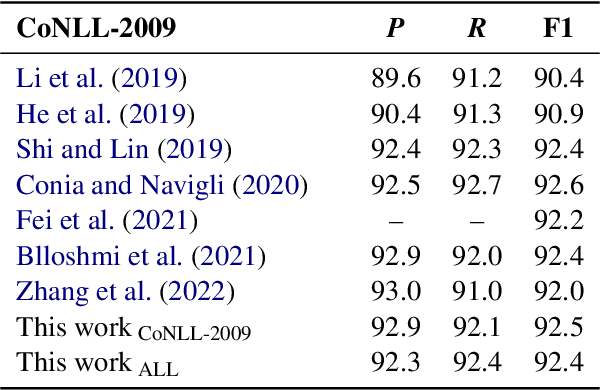
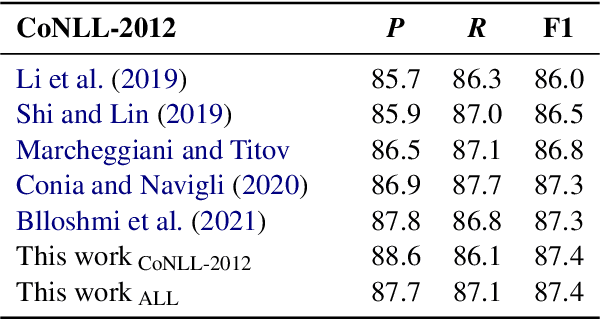
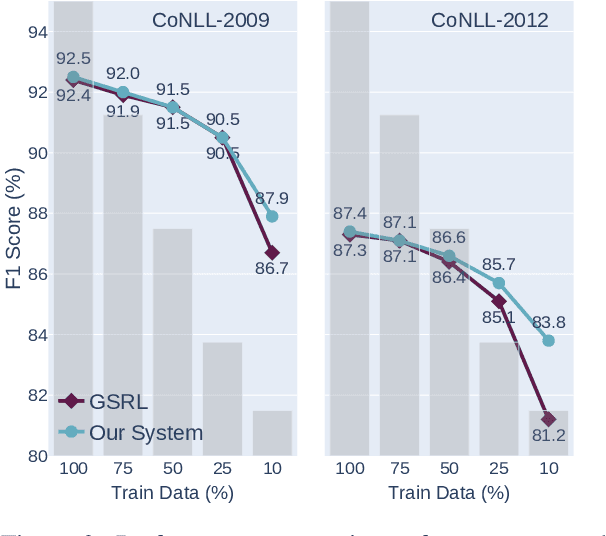
One of the common traits of past and present approaches for Semantic Role Labeling (SRL) is that they rely upon discrete labels drawn from a predefined linguistic inventory to classify predicate senses and their arguments. However, we argue this need not be the case. In this paper, we present an approach that leverages Definition Modeling to introduce a generalized formulation of SRL as the task of describing predicate-argument structures using natural language definitions instead of discrete labels. Our novel formulation takes a first step towards placing interpretability and flexibility foremost, and yet our experiments and analyses on PropBank-style and FrameNet-style, dependency-based and span-based SRL also demonstrate that a flexible model with an interpretable output does not necessarily come at the expense of performance. We release our software for research purposes at https://github.com/SapienzaNLP/dsrl.