 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZEBRA: Zero-Shot Example-Based Retrieval Augmentation for Commonsense Question Answering
Oct 07, 2024Current Large Language Models (LLMs) have shown strong reasoning capabilities in commonsense question answering benchmarks, but the process underlying their success remains largely opaque. As a consequence, recent approaches have equipped LLMs with mechanisms for knowledge retrieval, reasoning and introspection, not only to improve their capabilities but also to enhance the interpretability of their outputs. However, these methods require additional training, hand-crafted templates or human-written explanations. To address these issues, we introduce ZEBRA, a zero-shot question answering framework that combines retrieval, case-based reasoning and introspection and dispenses with the need for additional training of the LLM. Given an input question, ZEBRA retrieves relevant question-knowledge pairs from a knowledge base and generates new knowledge by reasoning over the relationships in these pairs. This generated knowledge is then used to answer the input question, improving the model's performance and interpretability. We evaluate our approach across 8 well-established commonsense reasoning benchmarks, demonstrating that ZEBRA consistently outperforms strong LLMs and previous knowledge integration approaches, achieving an average accuracy improvement of up to 4.5 points.
ReLiK: Retrieve and LinK, Fast and Accurate Entity Linking and Relation Extraction on an Academic Budget
Jul 31, 2024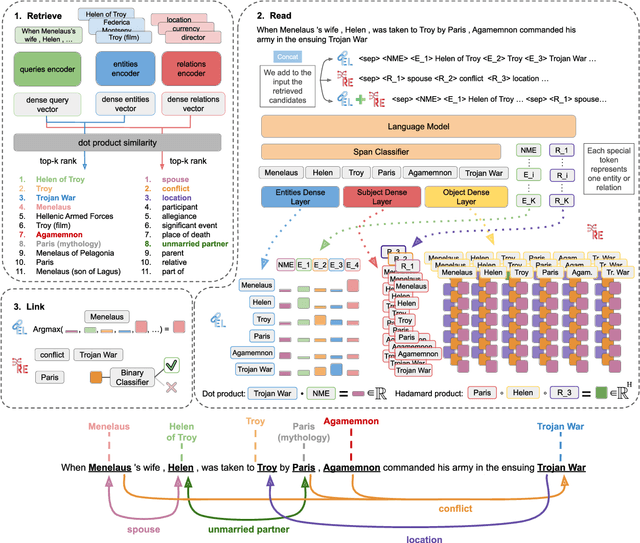
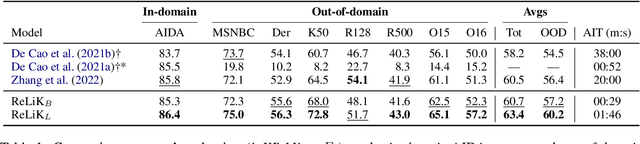
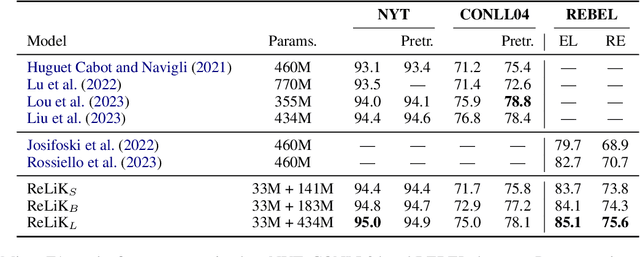
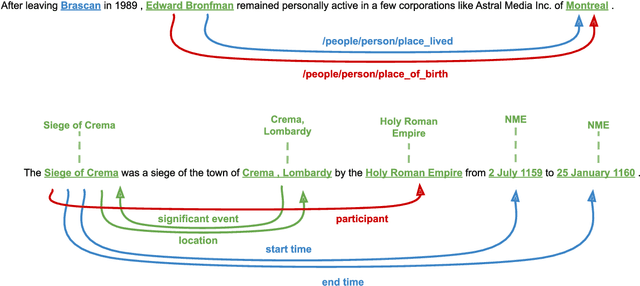
Entity Linking (EL) and Relation Extraction (RE) are fundamental tasks in Natural Language Processing, serving as critical components in a wide range of applications. In this paper, we propose ReLiK, a Retriever-Reader architecture for both EL and RE, where, given an input text, the Retriever module undertakes the identification of candidate entities or relations that could potentially appear within the text. Subsequently, the Reader module is tasked to discern the pertinent retrieved entities or relations and establish their alignment with the corresponding textual spans. Notably, we put forward an innovative input representation that incorporates the candidate entities or relations alongside the text, making it possible to link entities or extract relations in a single forward pass and to fully leverage pre-trained language models contextualization capabilities, in contrast with previous Retriever-Reader-based methods, which require a forward pass for each candidate. Our formulation of EL and RE achieves state-of-the-art performance in both in-domain and out-of-domain benchmarks while using academic budget training and with up to 40x inference speed compared to competitors. Finally, we show how our architecture can be used seamlessly for Information Extraction (cIE), i.e. EL + RE, and setting a new state of the art by employing a shared Reader that simultaneously extracts entities and relations.
Exploring Non-Verbal Predicates in Semantic Role Labeling: Challenges and Opportunities
Jul 04, 2023

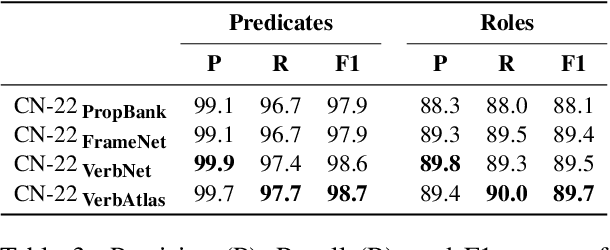
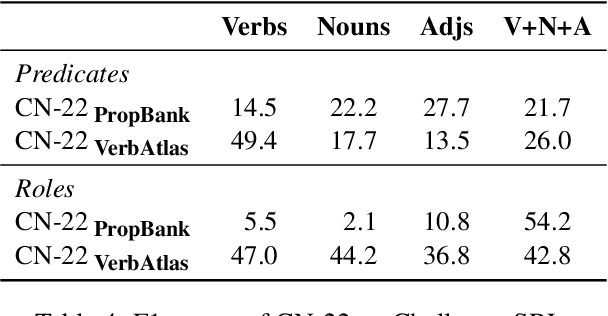
Although we have witnessed impressive progress in Semantic Role Labeling (SRL), most of the research in the area is carried out assuming that the majority of predicates are verbs. Conversely, predicates can also be expressed using other parts of speech, e.g., nouns and adjectives. However, non-verbal predicates appear in the benchmarks we commonly use to measure progress in SRL less frequently than in some real-world settings -- newspaper headlines, dialogues, and tweets, among others. In this paper, we put forward a new PropBank dataset which boasts wide coverage of multiple predicate types. Thanks to it, we demonstrate empirically that standard benchmarks do not provide an accurate picture of the current situation in SRL and that state-of-the-art systems are still incapable of transferring knowledge across different predicate types. Having observed these issues, we also present a novel, manually-annotated challenge set designed to give equal importance to verbal, nominal, and adjectival predicate-argument structures. We use such dataset to investigate whether we can leverage different linguistic resources to promote knowledge transfer. In conclusion, we claim that SRL is far from "solved", and its integration with other semantic tasks might enable significant improvements in the future, especially for the long tail of non-verbal predicates, thereby facilitating further research on SRL for non-verbal predicates.