 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreekMMLU: A Native-Sourced Multitask Benchmark for Evaluating Language Models in Greek
Feb 05, 2026Large Language Models (LLMs) are commonly trained on multilingual corpora that include Greek, yet reliable evaluation benchmarks for Greek-particularly those based on authentic, native-sourced content-remain limited. Existing datasets are often machine-translated from English, failing to capture Greek linguistic and cultural characteristics. We introduce GreekMMLU, a native-sourced benchmark for massive multitask language understanding in Greek, comprising 21,805 multiple-choice questions across 45 subject areas, organized under a newly defined subject taxonomy and annotated with educational difficulty levels spanning primary to professional examinations. All questions are sourced or authored in Greek from academic, professional, and governmental exams. We publicly release 16,857 samples and reserve 4,948 samples for a private leaderboard to enable robust and contamination-resistant evaluation. Evaluations of over 80 open- and closed-source LLMs reveal substantial performance gaps between frontier and open-weight models, as well as between Greek-adapted models and general multilingual ones. Finally, we provide a systematic analysis of factors influencing performance-including model scale, adaptation, and prompting-and derive insights for improving LLM capabilities in Greek.
On the Lipschitz Continuity of Set Aggregation Functions and Neural Networks for Sets
May 30, 2025The Lipschitz constant of a neural network is connected to several important properties of the network such as its robustness and generalization. It is thus useful in many settings to estimate the Lipschitz constant of a model. Prior work has focused mainly on estimating the Lipschitz constant of multi-layer perceptrons and convolutional neural networks. Here we focus on data modeled as sets or multisets of vectors and on neural networks that can handle such data. These models typically apply some permutation invariant aggregation function, such as the sum, mean or max operator, to the input multisets to produce a single vector for each input sample. In this paper, we investigate whether these aggregation functions are Lipschitz continuous with respect to three distance functions for unordered multisets, and we compute their Lipschitz constants. In the general case, we find that each aggregation function is Lipschitz continuous with respect to only one of the three distance functions. Then, we build on these results to derive upper bounds on the Lipschitz constant of neural networks that can process multisets of vectors, while we also study their stability to perturbations and generalization under distribution shifts. To empirically verify our theoretical analysis, we conduct a series of experiments on datasets from different domains.
Graph Linearization Methods for Reasoning on Graphs with Large Language Models
Oct 25, 2024



Large language models have evolved to process multiple modalities beyond text, such as images and audio, which motivates us to explore how to effectively leverage them for graph machine learning tasks. The key question, therefore, is how to transform graphs into linear sequences of tokens, a process we term graph linearization, so that LLMs can handle graphs naturally. We consider that graphs should be linearized meaningfully to reflect certain properties of natural language text, such as local dependency and global alignment, in order to ease contemporary LLMs, trained on trillions of textual tokens, better understand graphs. To achieve this, we developed several graph linearization methods based on graph centrality, degeneracy, and node relabeling schemes. We then investigated their effect on LLM performance in graph reasoning tasks. Experimental results on synthetic graphs demonstrate the effectiveness of our methods compared to random linearization baselines. Our work introduces novel graph representations suitable for LLMs, contributing to the potential integration of graph machine learning with the trend of multi-modal processing using a unified transformer model.
Graph Reasoning with Large Language Models via Pseudo-code Prompting
Sep 26, 2024
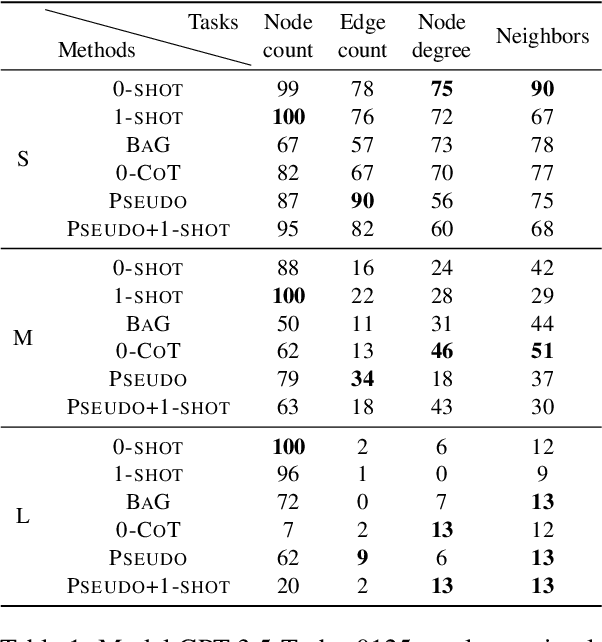
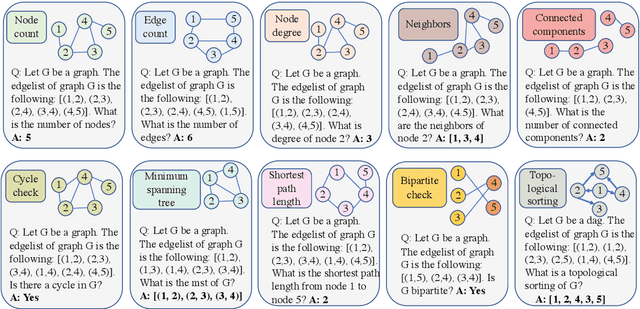
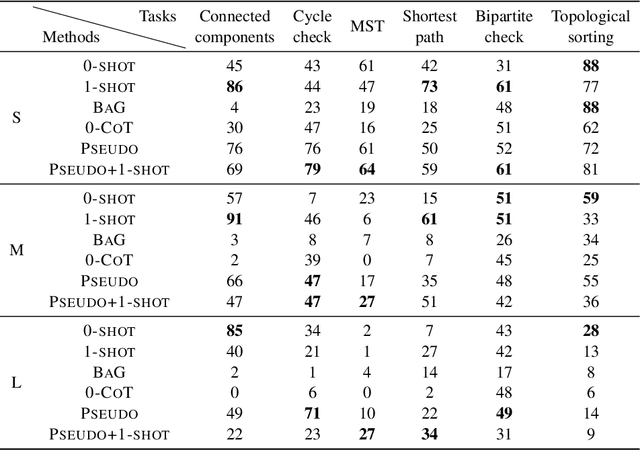
Large language models (LLMs) have recently achieved remarkable success in various reasoning tasks in the field of natural language processing. This success of LLMs has also motivated their use in graph-related tasks. Among others, recent work has explored whether LLMs can solve graph problems such as counting the number of connected components of a graph or computing the shortest path distance between two nodes. Although LLMs possess preliminary graph reasoning abilities, they might still struggle to solve some seemingly simple problems. In this paper, we investigate whether prompting via pseudo-code instructions can improve the performance of LLMs in solving graph problems. Our experiments demonstrate that using pseudo-code instructions generally improves the performance of all considered LLMs. The graphs, pseudo-code prompts, and evaluation code are publicly available.
Signed Graph Autoencoder for Explainable and Polarization-Aware Network Embeddings
Sep 16, 2024



Autoencoders based on Graph Neural Networks (GNNs) have garnered significant attention in recent years for their ability to extract informative latent representations, characterizing the structure of complex topologies, such as graphs. Despite the prevalence of Graph Autoencoders, there has been limited focus on developing and evaluating explainable neural-based graph generative models specifically designed for signed networks. To address this gap, we propose the Signed Graph Archetypal Autoencoder (SGAAE) framework. SGAAE extracts node-level representations that express node memberships over distinct extreme profiles, referred to as archetypes, within the network. This is achieved by projecting the graph onto a learned polytope, which governs its polarization. The framework employs a recently proposed likelihood for analyzing signed networks based on the Skellam distribution, combined with relational archetypal analysis and GNNs. Our experimental evaluation demonstrates the SGAAEs' capability to successfully infer node memberships over the different underlying latent structures while extracting competing communities formed through the participation of the opposing views in the network. Additionally, we introduce the 2-level network polarization problem and show how SGAAE is able to characterize such a setting. The proposed model achieves high performance in different tasks of signed link prediction across four real-world datasets, outperforming several baseline models.
KAGNNs: Kolmogorov-Arnold Networks meet Graph Learning
Jun 26, 2024



In recent years, Graph Neural Networks (GNNs) have become the de facto tool for learning node and graph representations. Most GNNs typically consist of a sequence of neighborhood aggregation (a.k.a., message passing) layers. Within each of these layers, the representation of each node is updated from an aggregation and transformation of its neighbours representations at the previous layer. The upper bound for the expressive power of message passing GNNs was reached through the use of MLPs as a transformation, due to their universal approximation capabilities. However, MLPs suffer from well-known limitations, which recently motivated the introduction of Kolmogorov-Arnold Networks (KANs). KANs rely on the Kolmogorov-Arnold representation theorem, rendering them a promising alternative to MLPs. In this work, we compare the performance of KANs against that of MLPs in graph learning tasks. We perform extensive experiments on node classification, graph classification and graph regression datasets. Our preliminary results indicate that while KANs are on-par with MLPs in classification tasks, they seem to have a clear advantage in the graph regression tasks.
Neural Graph Generator: Feature-Conditioned Graph Generation using Latent Diffusion Models
Mar 03, 2024Graph generation has emerged as a crucial task in machine learning, with significant challenges in generating graphs that accurately reflect specific properties. Existing methods often fall short in efficiently addressing this need as they struggle with the high-dimensional complexity and varied nature of graph properties. In this paper, we introduce the Neural Graph Generator (NGG), a novel approach which utilizes conditioned latent diffusion models for graph generation. NGG demonstrates a remarkable capacity to model complex graph patterns, offering control over the graph generation process. NGG employs a variational graph autoencoder for graph compression and a diffusion process in the latent vector space, guided by vectors summarizing graph statistics. We demonstrate NGG's versatility across various graph generation tasks, showing its capability to capture desired graph properties and generalize to unseen graphs. This work signifies a significant shift in graph generation methodologies, offering a more practical and efficient solution for generating diverse types of graphs with specific characteristics.
Graph Neural Machine: A New Model for Learning with Tabular Data
Feb 05, 2024



In recent years, there has been a growing interest in mapping data from different domains to graph structures. Among others, neural network models such as the multi-layer perceptron (MLP) can be modeled as graphs. In fact, MLPs can be represented as directed acyclic graphs. Graph neural networks (GNNs) have recently become the standard tool for performing machine learning tasks on graphs. In this work, we show that an MLP is equivalent to an asynchronous message passing GNN model which operates on the MLP's graph representation. We then propose a new machine learning model for tabular data, the so-called Graph Neural Machine (GNM), which replaces the MLP's directed acyclic graph with a nearly complete graph and which employs a synchronous message passing scheme. We show that a single GNM model can simulate multiple MLP models. We evaluate the proposed model in several classification and regression datasets. In most cases, the GNM model outperforms the MLP architecture.
Time-Parameterized Convolutional Neural Networks for Irregularly Sampled Time Series
Aug 09, 2023



Irregularly sampled multivariate time series are ubiquitous in several application domains, leading to sparse, not fully-observed and non-aligned observations across different variables. Standard sequential neural network architectures, such as recurrent neural networks (RNNs) and convolutional neural networks (CNNs), consider regular spacing between observation times, posing significant challenges to irregular time series modeling. While most of the proposed architectures incorporate RNN variants to handle irregular time intervals, convolutional neural networks have not been adequately studied in the irregular sampling setting. In this paper, we parameterize convolutional layers by employing time-explicitly initialized kernels. Such general functions of time enhance the learning process of continuous-time hidden dynamics and can be efficiently incorporated into convolutional kernel weights. We, thus, propose the time-parameterized convolutional neural network (TPCNN), which shares similar properties with vanilla convolutions but is carefully designed for irregularly sampled time series. We evaluate TPCNN on both interpolation and classification tasks involving real-world irregularly sampled multivariate time series datasets. Our experimental results indicate the competitive performance of the proposed TPCNN model which is also significantly more efficient than other state-of-the-art methods. At the same time, the proposed architecture allows the interpretability of the input series by leveraging the combination of learnable time functions that improve the network performance in subsequent tasks and expedite the inaugural application of convolutions in this field.
Supervised Attention Using Homophily in Graph Neural Networks
Jul 15, 2023



Graph neural networks have become the standard approach for dealing with learning problems on graphs. Among the different variants of graph neural networks, graph attention networks (GATs) have been applied with great success to different tasks. In the GAT model, each node assigns an importance score to its neighbors using an attention mechanism. However, similar to other graph neural networks, GATs aggregate messages from nodes that belong to different classes, and therefore produce node representations that are not well separated with respect to the different classes, which might hurt their performance. In this work, to alleviate this problem, we propose a new technique that can be incorporated into any graph attention model to encourage higher attention scores between nodes that share the same class label. We evaluate the proposed method on several node classification datasets demonstrating increased performance over standard baseline models.