 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Linearization Methods for Reasoning on Graphs with Large Language Models
Oct 25, 2024



Large language models have evolved to process multiple modalities beyond text, such as images and audio, which motivates us to explore how to effectively leverage them for graph machine learning tasks. The key question, therefore, is how to transform graphs into linear sequences of tokens, a process we term graph linearization, so that LLMs can handle graphs naturally. We consider that graphs should be linearized meaningfully to reflect certain properties of natural language text, such as local dependency and global alignment, in order to ease contemporary LLMs, trained on trillions of textual tokens, better understand graphs. To achieve this, we developed several graph linearization methods based on graph centrality, degeneracy, and node relabeling schemes. We then investigated their effect on LLM performance in graph reasoning tasks. Experimental results on synthetic graphs demonstrate the effectiveness of our methods compared to random linearization baselines. Our work introduces novel graph representations suitable for LLMs, contributing to the potential integration of graph machine learning with the trend of multi-modal processing using a unified transformer model.
Real-time Traffic Classification for 5G NSA Encrypted Data Flows With Physical Channel Records
Jul 15, 2023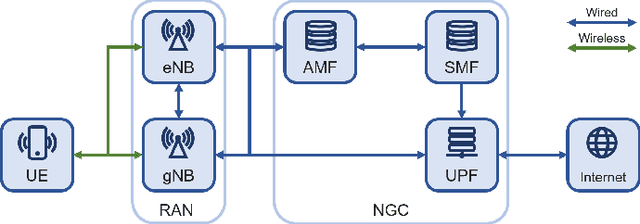
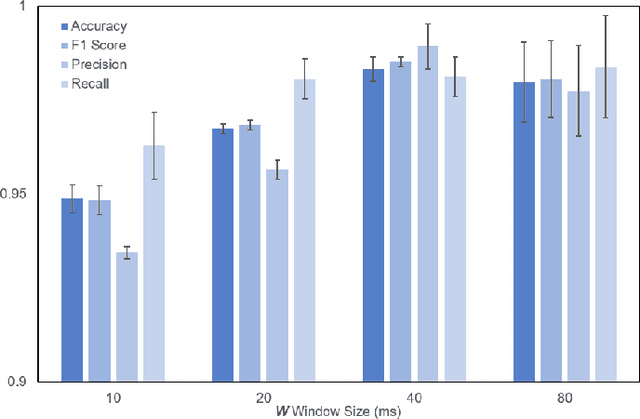
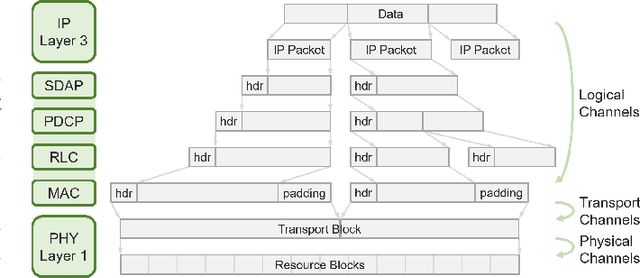
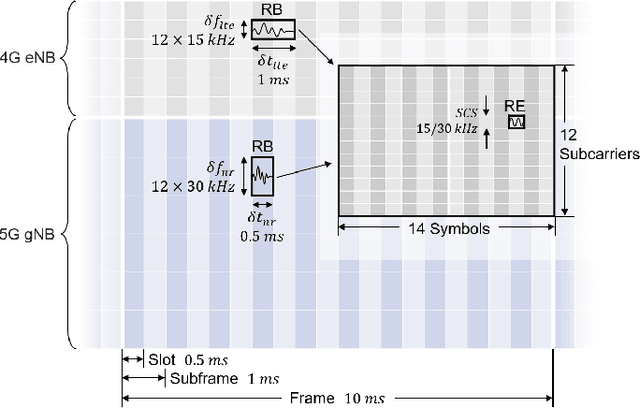
The classification of fifth-generation New-Radio (5G-NR) mobile network traffic is an emerging topic in the field of telecommunications. It can be utilized for quality of service (QoS) management and dynamic resource allocation. However, traditional approaches such as Deep Packet Inspection (DPI) can not be directly applied to encrypted data flows. Therefore, new real-time encrypted traffic classification algorithms need to be investigated to handle dynamic transmission. In this study, we examine the real-time encrypted 5G Non-Standalone (NSA) application-level traffic classification using physical channel records. Due to the vastness of their features, decision-tree-based gradient boosting algorithms are a viable approach for classification. We generate a noise-limited 5G NSA trace dataset with traffic from multiple applications. We develop a new pipeline to convert sequences of physical channel records into numerical vectors. A set of machine learning models are tested, and we propose our solution based on Light Gradient Boosting Machine (LGBM) due to its advantages in fast parallel training and low computational burden in practical scenarios. Our experiments demonstrate that our algorithm can achieve 95% accuracy on the classification task with a state-of-the-art response time as quick as 10ms.