 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Signed Two-Space Proximity Model for Learning Representations in Protein-Protein Interaction Networks
Mar 05, 2025Accurately predicting complex protein-protein interactions (PPIs) is crucial for decoding biological processes, from cellular functioning to disease mechanisms. However, experimental methods for determining PPIs are computationally expensive. Thus, attention has been recently drawn to machine learning approaches. Furthermore, insufficient effort has been made toward analyzing signed PPI networks, which capture both activating (positive) and inhibitory (negative) interactions. To accurately represent biological relationships, we present the Signed Two-Space Proximity Model (S2-SPM) for signed PPI networks, which explicitly incorporates both types of interactions, reflecting the complex regulatory mechanisms within biological systems. This is achieved by leveraging two independent latent spaces to differentiate between positive and negative interactions while representing protein similarity through proximity in these spaces. Our approach also enables the identification of archetypes representing extreme protein profiles. S2-SPM's superior performance in predicting the presence and sign of interactions in SPPI networks is demonstrated in link prediction tasks against relevant baseline methods. Additionally, the biological prevalence of the identified archetypes is confirmed by an enrichment analysis of Gene Ontology (GO) terms, which reveals that distinct biological tasks are associated with archetypal groups formed by both interactions. This study is also validated regarding statistical significance and sensitivity analysis, providing insights into the functional roles of different interaction types. Finally, the robustness and consistency of the extracted archetype structures are confirmed using the Bayesian Normalized Mutual Information (BNMI) metric, proving the model's reliability in capturing meaningful SPPI patterns.
A Graph Neural Architecture Search Approach for Identifying Bots in Social Media
Nov 25, 2024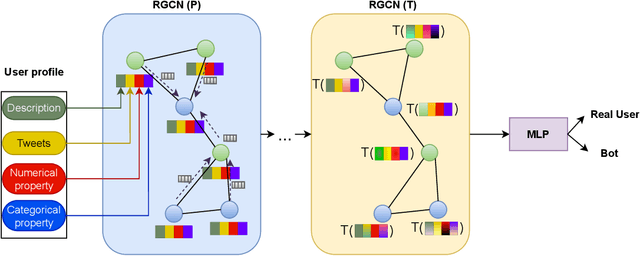
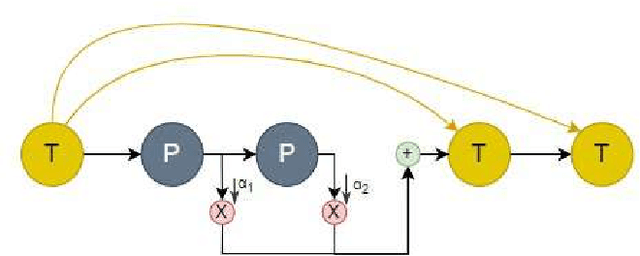
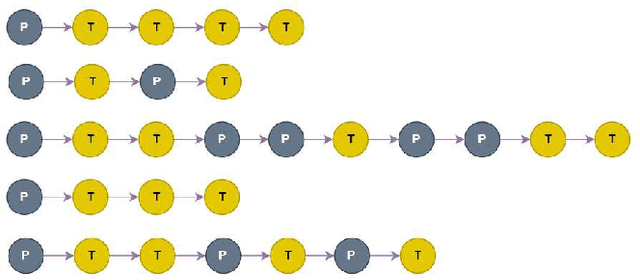

Social media platforms, including X, Facebook, and Instagram, host millions of daily users, giving rise to bots-automated programs disseminating misinformation and ideologies with tangible real-world consequences. While bot detection in platform X has been the area of many deep learning models with adequate results, most approaches neglect the graph structure of social media relationships and often rely on hand-engineered architectures. Our work introduces the implementation of a Neural Architecture Search (NAS) technique, namely Deep and Flexible Graph Neural Architecture Search (DFG-NAS), tailored to Relational Graph Convolutional Neural Networks (RGCNs) in the task of bot detection in platform X. Our model constructs a graph that incorporates both the user relationships and their metadata. Then, DFG-NAS is adapted to automatically search for the optimal configuration of Propagation and Transformation functions in the RGCNs. Our experiments are conducted on the TwiBot-20 dataset, constructing a graph with 229,580 nodes and 227,979 edges. We study the five architectures with the highest performance during the search and achieve an accuracy of 85.7%, surpassing state-of-the-art models. Our approach not only addresses the bot detection challenge but also advocates for the broader implementation of NAS models in neural network design automation.
Graph Linearization Methods for Reasoning on Graphs with Large Language Models
Oct 25, 2024



Large language models have evolved to process multiple modalities beyond text, such as images and audio, which motivates us to explore how to effectively leverage them for graph machine learning tasks. The key question, therefore, is how to transform graphs into linear sequences of tokens, a process we term graph linearization, so that LLMs can handle graphs naturally. We consider that graphs should be linearized meaningfully to reflect certain properties of natural language text, such as local dependency and global alignment, in order to ease contemporary LLMs, trained on trillions of textual tokens, better understand graphs. To achieve this, we developed several graph linearization methods based on graph centrality, degeneracy, and node relabeling schemes. We then investigated their effect on LLM performance in graph reasoning tasks. Experimental results on synthetic graphs demonstrate the effectiveness of our methods compared to random linearization baselines. Our work introduces novel graph representations suitable for LLMs, contributing to the potential integration of graph machine learning with the trend of multi-modal processing using a unified transformer model.
KAGNNs: Kolmogorov-Arnold Networks meet Graph Learning
Jun 26, 2024



In recent years, Graph Neural Networks (GNNs) have become the de facto tool for learning node and graph representations. Most GNNs typically consist of a sequence of neighborhood aggregation (a.k.a., message passing) layers. Within each of these layers, the representation of each node is updated from an aggregation and transformation of its neighbours representations at the previous layer. The upper bound for the expressive power of message passing GNNs was reached through the use of MLPs as a transformation, due to their universal approximation capabilities. However, MLPs suffer from well-known limitations, which recently motivated the introduction of Kolmogorov-Arnold Networks (KANs). KANs rely on the Kolmogorov-Arnold representation theorem, rendering them a promising alternative to MLPs. In this work, we compare the performance of KANs against that of MLPs in graph learning tasks. We perform extensive experiments on node classification, graph classification and graph regression datasets. Our preliminary results indicate that while KANs are on-par with MLPs in classification tasks, they seem to have a clear advantage in the graph regression tasks.
Geometric Self-Supervised Pretraining on 3D Protein Structures using Subgraphs
Jun 20, 2024
Protein representation learning aims to learn informative protein embeddings capable of addressing crucial biological questions, such as protein function prediction. Although sequence-based transformer models have shown promising results by leveraging the vast amount of protein sequence data in a self-supervised way, there is still a gap in applying these methods to 3D protein structures. In this work, we propose a pre-training scheme going beyond trivial masking methods leveraging 3D and hierarchical structures of proteins. We propose a novel self-supervised method to pretrain 3D graph neural networks on 3D protein structures, by predicting the distances between local geometric centroids of protein subgraphs and the global geometric centroid of the protein. The motivation for this method is twofold. First, the relative spatial arrangements and geometric relationships among different regions of a protein are crucial for its function. Moreover, proteins are often organized in a hierarchical manner, where smaller substructures, such as secondary structure elements, assemble into larger domains. By considering subgraphs and their relationships to the global protein structure, the model can learn to reason about these hierarchical levels of organization. We experimentally show that our proposed pertaining strategy leads to significant improvements in the performance of 3D GNNs in various protein classification tasks.
Neural Graph Generator: Feature-Conditioned Graph Generation using Latent Diffusion Models
Mar 03, 2024Graph generation has emerged as a crucial task in machine learning, with significant challenges in generating graphs that accurately reflect specific properties. Existing methods often fall short in efficiently addressing this need as they struggle with the high-dimensional complexity and varied nature of graph properties. In this paper, we introduce the Neural Graph Generator (NGG), a novel approach which utilizes conditioned latent diffusion models for graph generation. NGG demonstrates a remarkable capacity to model complex graph patterns, offering control over the graph generation process. NGG employs a variational graph autoencoder for graph compression and a diffusion process in the latent vector space, guided by vectors summarizing graph statistics. We demonstrate NGG's versatility across various graph generation tasks, showing its capability to capture desired graph properties and generalize to unseen graphs. This work signifies a significant shift in graph generation methodologies, offering a more practical and efficient solution for generating diverse types of graphs with specific characteristics.
Prot2Text: Multimodal Protein's Function Generation with GNNs and Transformers
Jul 25, 2023The complex nature of big biological systems pushed some scientists to classify its understanding under the inconceivable missions. Different leveled challenges complicated this task, one of is the prediction of a protein's function. In recent years, significant progress has been made in this field through the development of various machine learning approaches. However, most existing methods formulate the task as a multi-classification problem, i.e assigning predefined labels to proteins. In this work, we propose a novel approach, \textbf{Prot2Text}, which predicts a protein function's in a free text style, moving beyond the conventional binary or categorical classifications. By combining Graph Neural Networks(GNNs) and Large Language Models(LLMs), in an encoder-decoder framework, our model effectively integrates diverse data types including proteins' sequences, structures, and textual annotations. This multimodal approach allows for a holistic representation of proteins' functions, enabling the generation of detailed and accurate descriptions. To evaluate our model, we extracted a multimodal protein dataset from SwissProt, and demonstrate empirically the effectiveness of Prot2Text. These results highlight the transformative impact of multimodal models, specifically the fusion of GNNs and LLMs, empowering researchers with powerful tools for more accurate prediction of proteins' functions. The code, the models and a demo will be publicly released.
Supervised Attention Using Homophily in Graph Neural Networks
Jul 15, 2023



Graph neural networks have become the standard approach for dealing with learning problems on graphs. Among the different variants of graph neural networks, graph attention networks (GATs) have been applied with great success to different tasks. In the GAT model, each node assigns an importance score to its neighbors using an attention mechanism. However, similar to other graph neural networks, GATs aggregate messages from nodes that belong to different classes, and therefore produce node representations that are not well separated with respect to the different classes, which might hurt their performance. In this work, to alleviate this problem, we propose a new technique that can be incorporated into any graph attention model to encourage higher attention scores between nodes that share the same class label. We evaluate the proposed method on several node classification datasets demonstrating increased performance over standard baseline models.
What Do GNNs Actually Learn? Towards Understanding their Representations
Apr 21, 2023


In recent years, graph neural networks (GNNs) have achieved great success in the field of graph representation learning. Although prior work has shed light into the expressiveness of those models (\ie whether they can distinguish pairs of non-isomorphic graphs), it is still not clear what structural information is encoded into the node representations that are learned by those models. In this paper, we investigate which properties of graphs are captured purely by these models, when no node attributes are available. Specifically, we study four popular GNN models, and we show that two of them embed all nodes into the same feature vector, while the other two models generate representations that are related to the number of walks over the input graph. Strikingly, structurally dissimilar nodes can have similar representations at some layer $k>1$, if they have the same number of walks of length $k$. We empirically verify our theoretical findings on real datasets.
Neural Architecture Search with Multimodal Fusion Methods for Diagnosing Dementia
Feb 12, 2023


Alzheimer's dementia (AD) affects memory, thinking, and language, deteriorating person's life. An early diagnosis is very important as it enables the person to receive medical help and ensure quality of life. Therefore, leveraging spontaneous speech in conjunction with machine learning methods for recognizing AD patients has emerged into a hot topic. Most of the previous works employ Convolutional Neural Networks (CNNs), to process the input signal. However, finding a CNN architecture is a time-consuming process and requires domain expertise. Moreover, the researchers introduce early and late fusion approaches for fusing different modalities or concatenate the representations of the different modalities during training, thus the inter-modal interactions are not captured. To tackle these limitations, first we exploit a Neural Architecture Search (NAS) method to automatically find a high performing CNN architecture. Next, we exploit several fusion methods, including Multimodal Factorized Bilinear Pooling and Tucker Decomposition, to combine both speech and text modalities. To the best of our knowledge, there is no prior work exploiting a NAS approach and these fusion methods in the task of dementia detection from spontaneous speech. We perform extensive experiments on the ADReSS Challenge dataset and show the effectiveness of our approach over state-of-the-art methods.