 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven Day Ahead Market Prices Forecasting: A Focus on Short Training Set Windows
Jun 12, 2025This study investigates the performance of machine learning models in forecasting electricity Day-Ahead Market (DAM) prices using short historical training windows, with a focus on detecting seasonal trends and price spikes. We evaluate four models, namely LSTM with Feed Forward Error Correction (FFEC), XGBoost, LightGBM, and CatBoost, across three European energy markets (Greece, Belgium, Ireland) using feature sets derived from ENTSO-E forecast data. Training window lengths range from 7 to 90 days, allowing assessment of model adaptability under constrained data availability. Results indicate that LightGBM consistently achieves the highest forecasting accuracy and robustness, particularly with 45 and 60 day training windows, which balance temporal relevance and learning depth. Furthermore, LightGBM demonstrates superior detection of seasonal effects and peak price events compared to LSTM and other boosting models. These findings suggest that short-window training approaches, combined with boosting methods, can effectively support DAM forecasting in volatile, data-scarce environments.
Explainable AI for building energy retrofitting under data scarcity
Apr 08, 2025Enhancing energy efficiency in residential buildings is a crucial step toward mitigating climate change and reducing greenhouse gas emissions. Retrofitting existing buildings, which account for a significant portion of energy consumption, is critical particularly in regions with outdated and inefficient building stocks. This study presents an Artificial Intelligence (AI) and Machine Learning (ML)-based framework to recommend energy efficiency measures for residential buildings, leveraging accessible building characteristics to achieve energy class targets. Using Latvia as a case study, the methodology addresses challenges associated with limited datasets, class imbalance and data scarcity. The proposed approach integrates Conditional Tabular Generative Adversarial Networks (CTGAN) to generate synthetic data, enriching and balancing the dataset. A Multi-Layer Perceptron (MLP) model serves as the predictive model performing multi-label classification to predict appropriate retrofit strategies. Explainable Artificial Intelligence (XAI), specifically SHapley Additive exPlanations (SHAP), ensures transparency and trust by identifying key features that influence recommendations and guiding feature engineering choices for improved reliability and performance. The evaluation of the approach shows that it notably overcomes data limitations, achieving improvements up to 54% in precision, recall and F1 score. Although this study focuses on Latvia, the methodology is adaptable to other regions, underscoring the potential of AI in reducing the complexity and cost of building energy retrofitting overcoming data limitations. By facilitating decision-making processes and promoting stakeholders engagement, this work supports the global transition toward sustainable energy use in the residential building sector.
Mixture of Experts for Recognizing Depression from Interview and Reading Tasks
Feb 27, 2025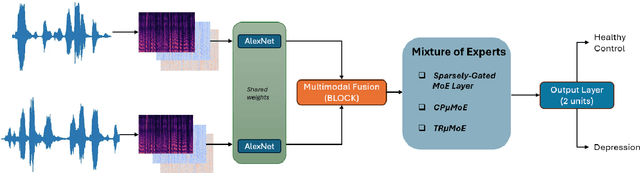
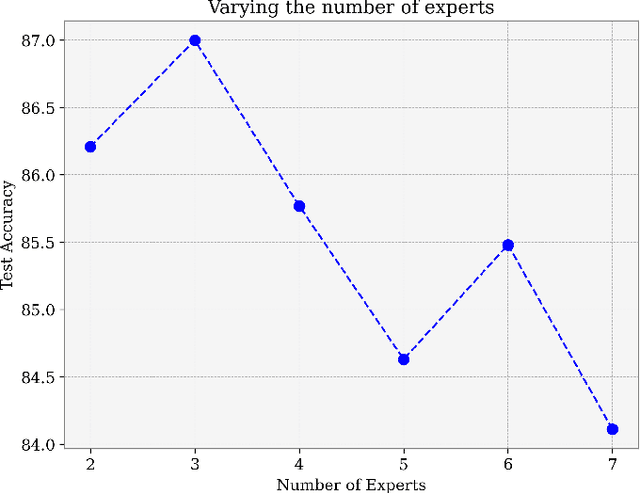
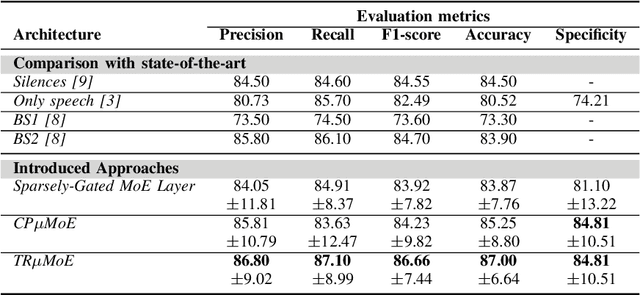
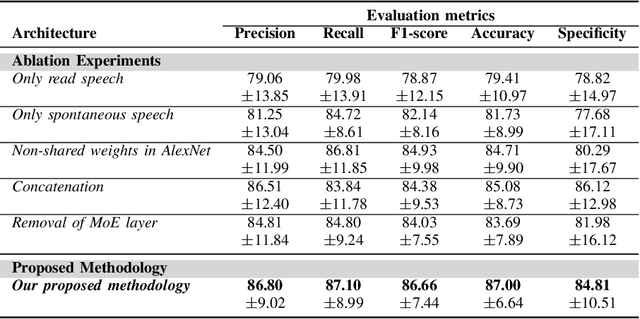
Depression is a mental disorder and can cause a variety of symptoms, including psychological, physical, and social. Speech has been proved an objective marker for the early recognition of depression. For this reason, many studies have been developed aiming to recognize depression through speech. However, existing methods rely on the usage of only the spontaneous speech neglecting information obtained via read speech, use transcripts which are often difficult to obtain (manual) or come with high word-error rates (automatic), and do not focus on input-conditional computation methods. To resolve these limitations, this is the first study in depression recognition task obtaining representations of both spontaneous and read speech, utilizing multimodal fusion methods, and employing Mixture of Experts (MoE) models in a single deep neural network. Specifically, we use audio files corresponding to both interview and reading tasks and convert each audio file into log-Mel spectrogram, delta, and delta-delta. Next, the image representations of the two tasks pass through shared AlexNet models. The outputs of the AlexNet models are given as input to a multimodal fusion method. The resulting vector is passed through a MoE module. In this study, we employ three variants of MoE, namely sparsely-gated MoE and multilinear MoE based on factorization. Findings suggest that our proposed approach yields an Accuracy and F1-score of 87.00% and 86.66% respectively on the Androids corpus.
AI4EF: Artificial Intelligence for Energy Efficiency in the Building Sector
Dec 05, 2024AI4EF, Artificial Intelligence for Energy Efficiency, is an advanced, user-centric tool designed to support decision-making in building energy retrofitting and efficiency optimization. Leveraging machine learning (ML) and data-driven insights, AI4EF enables stakeholders such as public sector representatives, energy consultants, and building owners to model, analyze, and predict energy consumption, retrofit costs, and environmental impacts of building upgrades. Featuring a modular framework, AI4EF includes customizable building retrofitting, photovoltaic installation assessment, and predictive modeling tools that allow users to input building parameters and receive tailored recommendations for achieving energy savings and carbon reduction goals. Additionally, the platform incorporates a Training Playground for data scientists to refine ML models used by said framework. Finally, AI4EF provides access to the Enershare Data Space to facilitate seamless data sharing and access within the ecosystem. Its compatibility with open-source identity management, Keycloak, enhances security and accessibility, making it adaptable for various regulatory and organizational contexts. This paper presents an architectural overview of AI4EF, its application in energy efficiency scenarios, and its potential for advancing sustainable energy practices through artificial intelligence (AI).
Convolutional Neural Networks and Mixture of Experts for Intrusion Detection in 5G Networks and beyond
Dec 04, 2024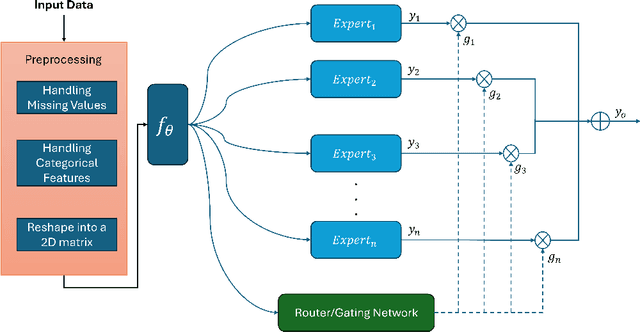
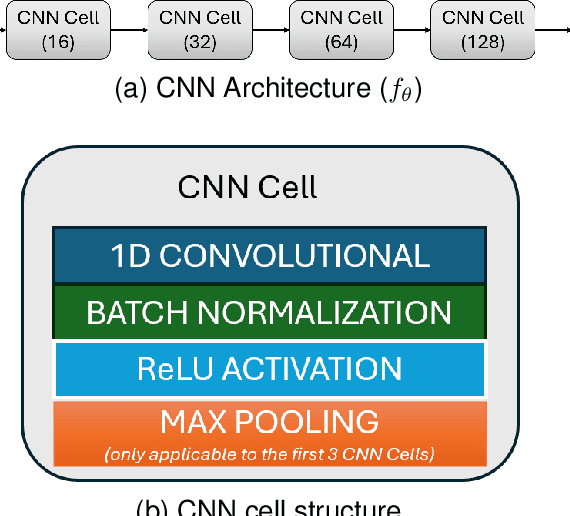
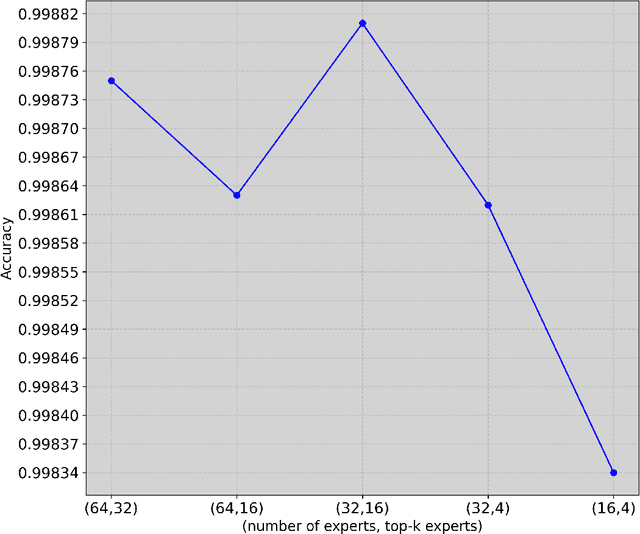
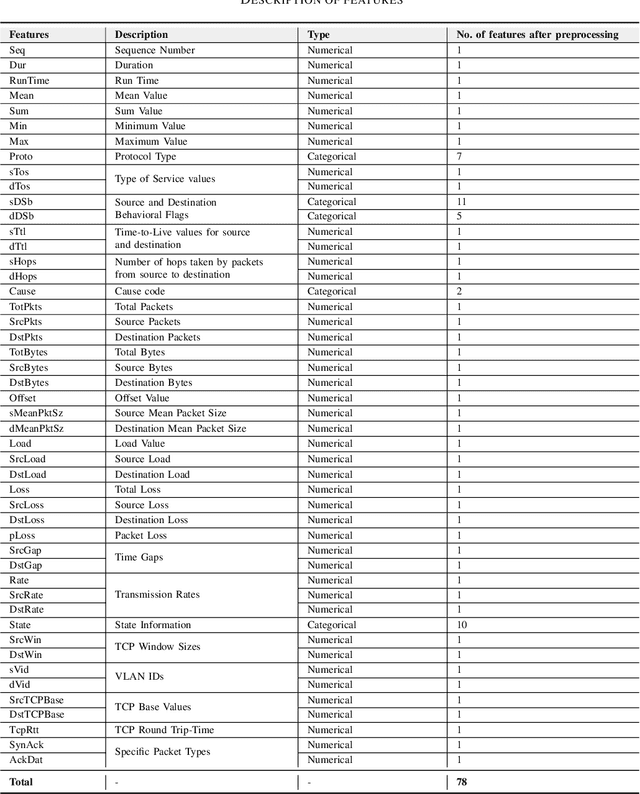
The advent of 6G/NextG networks comes along with a series of benefits, including extreme capacity, reliability, and efficiency. However, these networks may become vulnerable to new security threats. Therefore, 6G/NextG networks must be equipped with advanced Artificial Intelligence algorithms, in order to evade these attacks. Existing studies on the intrusion detection task rely on the train of shallow machine learning classifiers, including Logistic Regression, Decision Trees, and so on, yielding suboptimal performance. Others are based on deep neural networks consisting of static components, which are not conditional on the input. This limits their representation power and efficiency. To resolve these issues, we present the first study integrating Mixture of Experts (MoE) for identifying malicious traffic. Specifically, we use network traffic data and convert the 1D array of features into a 2D matrix. Next, we pass this matrix through convolutional neural network (CNN) layers followed by batch normalization and max pooling layers. After obtaining the representation vector via the CNN layers, a sparsely gated MoE layer is used. This layer consists of a set of experts (dense layers) and a router, where the router assigns weights to the output of each expert. Sparsity is achieved by choosing the most relevant experts of the total ones. Finally, we perform a series of ablation experiments to prove the effectiveness of our proposed model. Experiments are conducted on the 5G-NIDD dataset, a network intrusion detection dataset generated from a real 5G test network. Results show that our introduced approach reaches weighted F1-score up to 99.95% achieving comparable performance to existing approaches. Findings also show that our proposed model achieves multiple advantages over state-of-the-art approaches.
A Graph Neural Architecture Search Approach for Identifying Bots in Social Media
Nov 25, 2024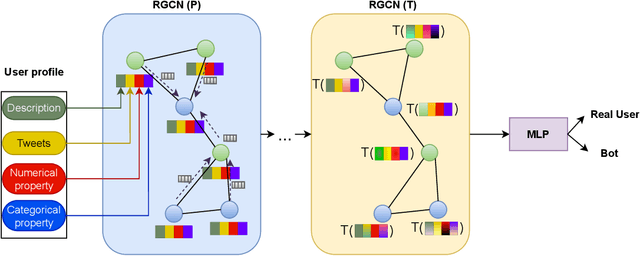
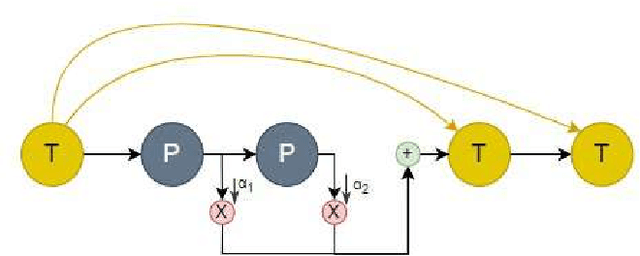
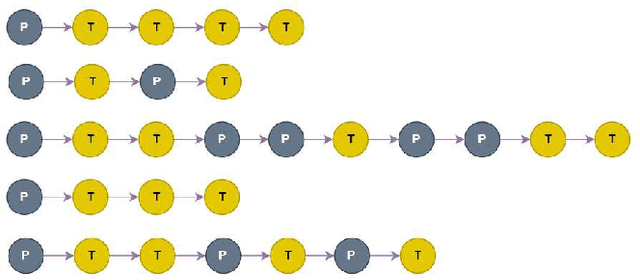

Social media platforms, including X, Facebook, and Instagram, host millions of daily users, giving rise to bots-automated programs disseminating misinformation and ideologies with tangible real-world consequences. While bot detection in platform X has been the area of many deep learning models with adequate results, most approaches neglect the graph structure of social media relationships and often rely on hand-engineered architectures. Our work introduces the implementation of a Neural Architecture Search (NAS) technique, namely Deep and Flexible Graph Neural Architecture Search (DFG-NAS), tailored to Relational Graph Convolutional Neural Networks (RGCNs) in the task of bot detection in platform X. Our model constructs a graph that incorporates both the user relationships and their metadata. Then, DFG-NAS is adapted to automatically search for the optimal configuration of Propagation and Transformation functions in the RGCNs. Our experiments are conducted on the TwiBot-20 dataset, constructing a graph with 229,580 nodes and 227,979 edges. We study the five architectures with the highest performance during the search and achieve an accuracy of 85.7%, surpassing state-of-the-art models. Our approach not only addresses the bot detection challenge but also advocates for the broader implementation of NAS models in neural network design automation.
A multi-dimensional unsupervised machine learning framework for clustering residential heat load profiles
Nov 11, 2024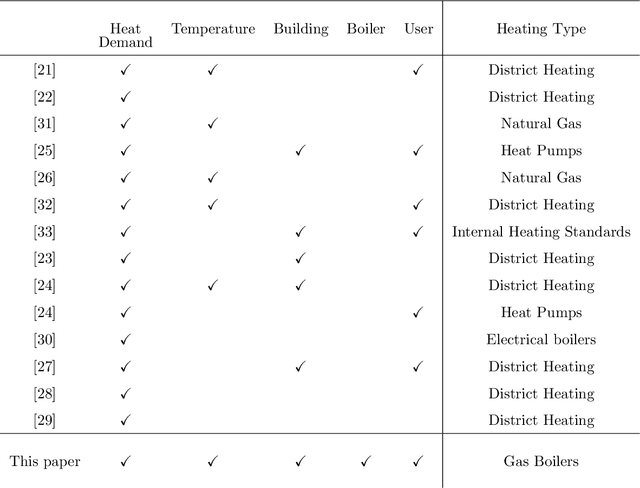


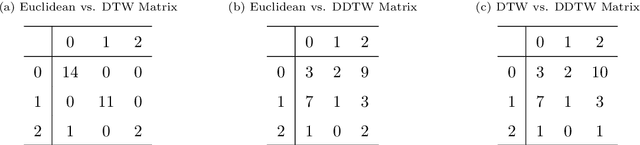
Central to achieving the energy transition, heating systems provide essential space heating and hot water in residential and industrial environments. A major challenge lies in effectively profiling large clusters of buildings to improve demand estimation and enable efficient Demand Response (DR) schemes. This paper addresses this challenge by introducing an unsupervised machine learning framework for clustering residential heating load profiles, focusing on natural gas space heating and hot water preparation boilers. The profiles are analyzed across five dimensions: boiler usage, heating demand, weather conditions, building characteristics, and user behavior. We apply three distance metrics: Euclidean Distance (ED), Dynamic Time Warping (DTW), and Derivative Dynamic Time Warping (DDTW), and evaluate their performance using established clustering indices. The proposed method is assessed considering 29 residential buildings in Greece equipped with smart meters throughout a calendar heating season (i.e., 210 days). Results indicate that DTW is the most suitable metric, uncovering strong correlations between boiler usage, heat demand, and temperature, while ED highlights broader interrelations across dimensions and DDTW proves less effective, resulting in weaker clusters. These findings offer key insights into heating load behavior, establishing a solid foundation for developing more targeted and effective DR programs.
Data-driven building energy efficiency prediction based on envelope heat losses using physics-informed neural networks
Nov 14, 2023The analytical prediction of building energy performance in residential buildings based on the heat losses of its individual envelope components is a challenging task. It is worth noting that this field is still in its infancy, with relatively limited research conducted in this specific area to date, especially when it comes for data-driven approaches. In this paper we introduce a novel physics-informed neural network model for addressing this problem. Through the employment of unexposed datasets that encompass general building information, audited characteristics, and heating energy consumption, we feed the deep learning model with general building information, while the model's output consists of the structural components and several thermal properties that are in fact the basic elements of an energy performance certificate (EPC). On top of this neural network, a function, based on physics equations, calculates the energy consumption of the building based on heat losses and enhances the loss function of the deep learning model. This methodology is tested on a real case study for 256 buildings located in Riga, Latvia. Our investigation comes up with promising results in terms of prediction accuracy, paving the way for automated, and data-driven energy efficiency performance prediction based on basic properties of the building, contrary to exhaustive energy efficiency audits led by humans, which are the current status quo.
Transfer learning for day-ahead load forecasting: a case study on European national electricity demand time series
Oct 24, 2023Short-term load forecasting (STLF) is crucial for the daily operation of power grids. However, the non-linearity, non-stationarity, and randomness characterizing electricity demand time series renders STLF a challenging task. Various forecasting approaches have been proposed for improving STLF, including neural network (NN) models which are trained using data from multiple electricity demand series that may not necessary include the target series. In the present study, we investigate the performance of this special case of STLF, called transfer learning (TL), by considering a set of 27 time series that represent the national day-ahead electricity demand of indicative European countries. We employ a popular and easy-to-implement NN model and perform a clustering analysis to identify similar patterns among the series and assist TL. In this context, two different TL approaches, with and without the clustering step, are compiled and compared against each other as well as a typical NN training setup. Our results demonstrate that TL can outperform the conventional approach, especially when clustering techniques are considered.
Multimodal Detection of Social Spambots in Twitter using Transformers
Aug 28, 2023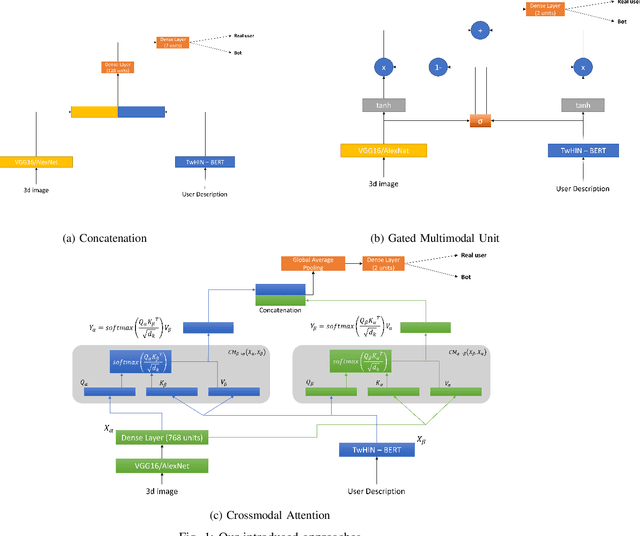
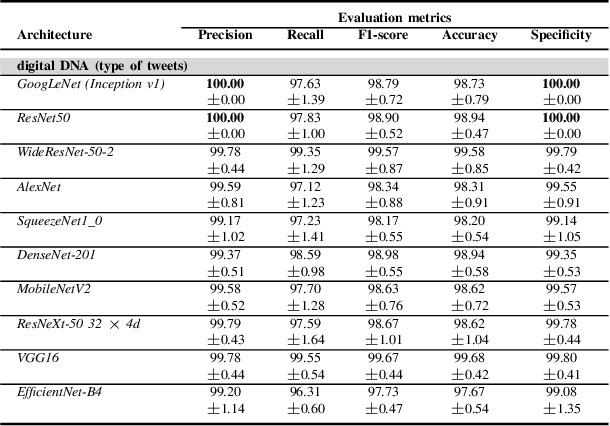
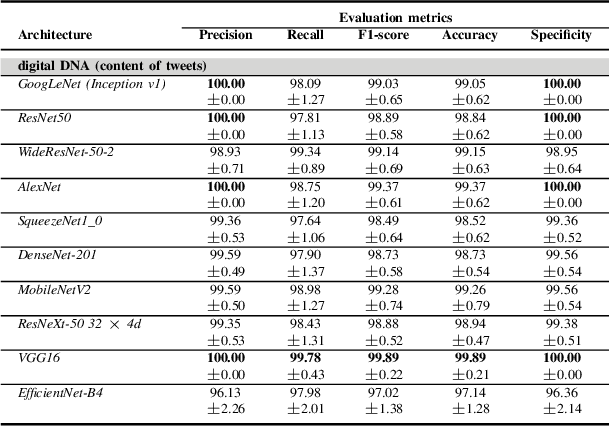
Although not all bots are malicious, the vast majority of them are responsible for spreading misinformation and manipulating the public opinion about several issues, i.e., elections and many more. Therefore, the early detection of social spambots is crucial. Although there have been proposed methods for detecting bots in social media, there are still substantial limitations. For instance, existing research initiatives still extract a large number of features and train traditional machine learning algorithms or use GloVe embeddings and train LSTMs. However, feature extraction is a tedious procedure demanding domain expertise. Also, language models based on transformers have been proved to be better than LSTMs. Other approaches create large graphs and train graph neural networks requiring in this way many hours for training and access to computational resources. To tackle these limitations, this is the first study employing only the user description field and images of three channels denoting the type and content of tweets posted by the users. Firstly, we create digital DNA sequences, transform them to 3d images, and apply pretrained models of the vision domain, including EfficientNet, AlexNet, VGG16, etc. Next, we propose a multimodal approach, where we use TwHIN-BERT for getting the textual representation of the user description field and employ VGG16 for acquiring the visual representation for the image modality. We propose three different fusion methods, namely concatenation, gated multimodal unit, and crossmodal attention, for fusing the different modalities and compare their performances. Extensive experiments conducted on the Cresci '17 dataset demonstrate valuable advantages of our introduced approaches over state-of-the-art ones reaching Accuracy up to 99.98%.