 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Speech Representation Learning for Parkinson's Disease Detection Using Context-guided Cross-modal Attention
Jun 08, 2026Parkinson's disease (PD) is a progressive neurodegenerative disorder that frequently causes speech impairments associated with hypokinetic dysarthria. As speech production relies on the precise coordination of complex neuromuscular mechanisms, speech analysis has emerged as a promising non-invasive and cost-effective biomarker for early PD detection. Recent deep learning approaches have shown encouraging results; however, most existing methods rely on a single speech representation, potentially overlooking complementary pathological information encoded across different feature spaces. In this work, we propose a multi-branch deep learning framework for automatic PD detection from speech. Each recording is segmented into 5-second chunks and represented using three complementary modalities: Log-Mel spectrograms, MFCCs, and HuBERT embeddings extracted from raw waveforms. The spectrograms are processed using a pre-trained ResNet-18 encoder, MFCC sequences are modeled through a BiLSTM network, and raw speech is encoded using a pre-trained HuBERT model. To effectively integrate these heterogeneous representations, we introduce a context-guided cross-modal attention mechanism that dynamically weights temporal HuBERT embeddings according to the global acoustic context derived from the spectrogram and MFCC branches. Experiments conducted on the publicly available Spanish PC-GITA corpus under strict speaker-independent 5-fold cross-validation demonstrate the effectiveness of the proposed approach. The proposed architecture achieves an accuracy of 91.51%, an F1-score of 91.24%, and an AUC of 95.97%. Furthermore, ablation studies confirm the contribution of both the proposed context-guided cross-modal attention mechanism and the integration of complementary speech representations. These findings highlight the potential of heterogeneous speech modeling for robust and clinically reliable PD detection.
A Multimodal Framework for Dementia Detection via Linguistic and Acoustic Representation Learning
May 25, 2026Alzheimer's disease (AD) is a progressive neurodegenerative disorder and the leading cause of dementia, affecting memory, reasoning, communication, and daily functioning. Early diagnosis is particularly important, as timely intervention may help slow cognitive decline and improve patient care. Recent studies have demonstrated that spontaneous speech contains valuable linguistic and acoustic biomarkers associated with dementia. However, existing approaches often rely on independently trained modality-specific models, feature concatenation strategies, ensemble methods, or attention-based fusion mechanisms that do not explicitly maximize the dependency between speech and transcript representations. In this work, we propose a multimodal deep learning framework for automatic dementia detection that jointly exploits speech and transcript information in an end-to-end trainable manner. Specifically, speech recordings are divided into 10-second segments and passed through a pre-trained HuBERT model to extract contextualized acoustic representations. To better capture informative temporal speech characteristics, attentive statistics pooling is employed to aggregate frame-level acoustic embeddings. For the textual modality, transcripts are encoded using a pre-trained BERT model, where the [CLS] token representation is used as the linguistic embedding. The acoustic and textual representations are subsequently combined using an attention-based Audio-Text Fusion (AT-Fusion) mechanism. In addition, we introduce a MINE objective to maximize the mutual information between modalities and improve multimodal representation alignment. The fused multimodal representation is finally used for dementia classification. Experiments conducted on the publicly available ADReSS Challenge and PROCESS-2 dataset demonstrate the effectiveness and robustness of the proposed approach for speech-based dementia assessment.
Mixture of Experts for Recognizing Depression from Interview and Reading Tasks
Feb 27, 2025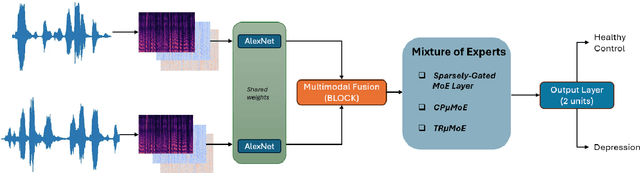
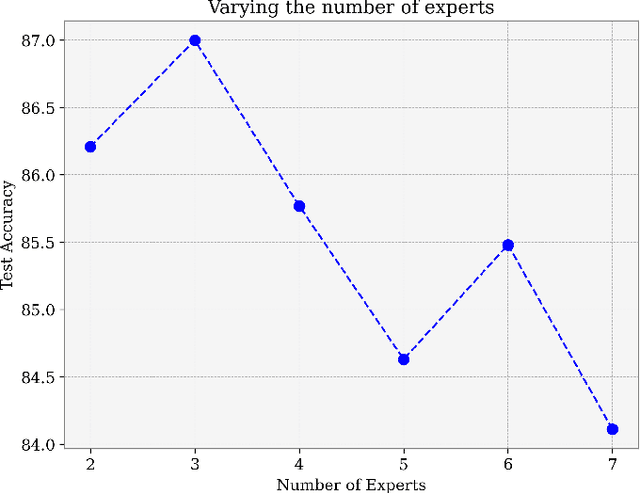
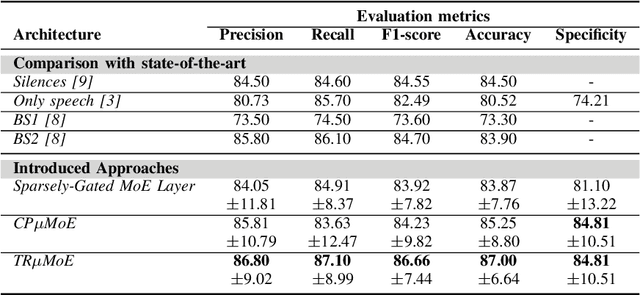
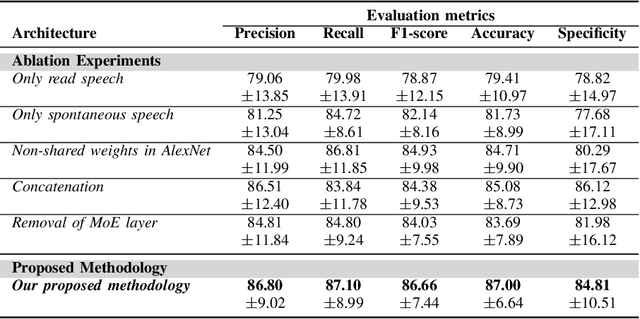
Depression is a mental disorder and can cause a variety of symptoms, including psychological, physical, and social. Speech has been proved an objective marker for the early recognition of depression. For this reason, many studies have been developed aiming to recognize depression through speech. However, existing methods rely on the usage of only the spontaneous speech neglecting information obtained via read speech, use transcripts which are often difficult to obtain (manual) or come with high word-error rates (automatic), and do not focus on input-conditional computation methods. To resolve these limitations, this is the first study in depression recognition task obtaining representations of both spontaneous and read speech, utilizing multimodal fusion methods, and employing Mixture of Experts (MoE) models in a single deep neural network. Specifically, we use audio files corresponding to both interview and reading tasks and convert each audio file into log-Mel spectrogram, delta, and delta-delta. Next, the image representations of the two tasks pass through shared AlexNet models. The outputs of the AlexNet models are given as input to a multimodal fusion method. The resulting vector is passed through a MoE module. In this study, we employ three variants of MoE, namely sparsely-gated MoE and multilinear MoE based on factorization. Findings suggest that our proposed approach yields an Accuracy and F1-score of 87.00% and 86.66% respectively on the Androids corpus.
Convolutional Neural Networks and Mixture of Experts for Intrusion Detection in 5G Networks and beyond
Dec 04, 2024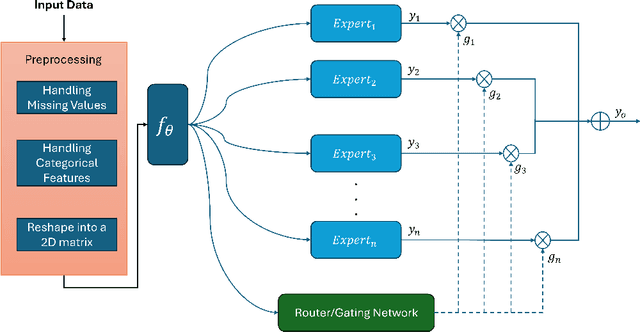
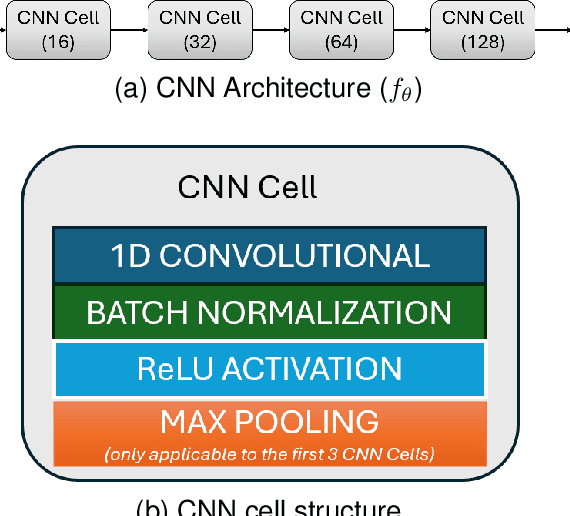
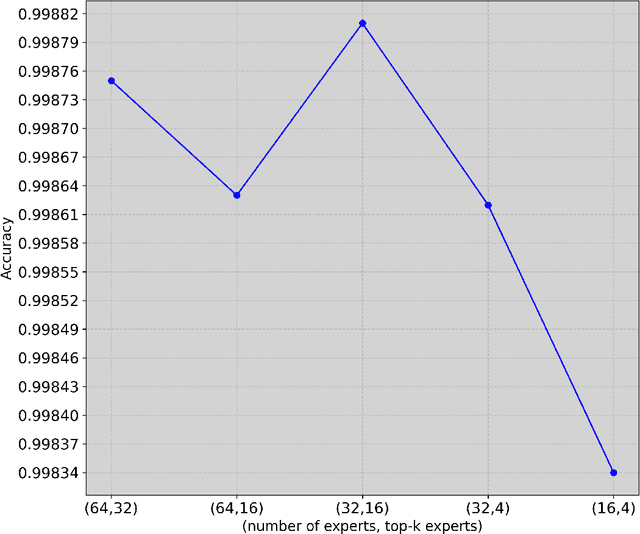
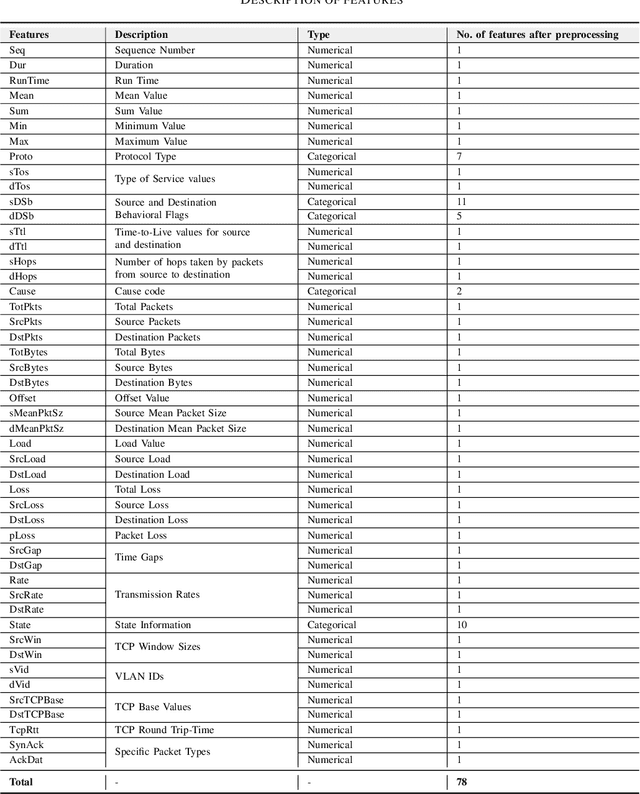
The advent of 6G/NextG networks comes along with a series of benefits, including extreme capacity, reliability, and efficiency. However, these networks may become vulnerable to new security threats. Therefore, 6G/NextG networks must be equipped with advanced Artificial Intelligence algorithms, in order to evade these attacks. Existing studies on the intrusion detection task rely on the train of shallow machine learning classifiers, including Logistic Regression, Decision Trees, and so on, yielding suboptimal performance. Others are based on deep neural networks consisting of static components, which are not conditional on the input. This limits their representation power and efficiency. To resolve these issues, we present the first study integrating Mixture of Experts (MoE) for identifying malicious traffic. Specifically, we use network traffic data and convert the 1D array of features into a 2D matrix. Next, we pass this matrix through convolutional neural network (CNN) layers followed by batch normalization and max pooling layers. After obtaining the representation vector via the CNN layers, a sparsely gated MoE layer is used. This layer consists of a set of experts (dense layers) and a router, where the router assigns weights to the output of each expert. Sparsity is achieved by choosing the most relevant experts of the total ones. Finally, we perform a series of ablation experiments to prove the effectiveness of our proposed model. Experiments are conducted on the 5G-NIDD dataset, a network intrusion detection dataset generated from a real 5G test network. Results show that our introduced approach reaches weighted F1-score up to 99.95% achieving comparable performance to existing approaches. Findings also show that our proposed model achieves multiple advantages over state-of-the-art approaches.
A Graph Neural Architecture Search Approach for Identifying Bots in Social Media
Nov 25, 2024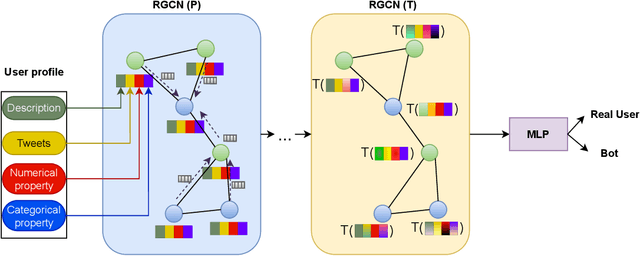
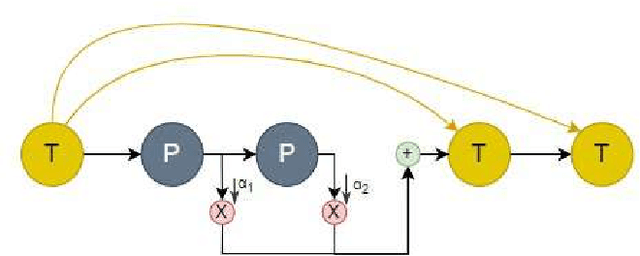
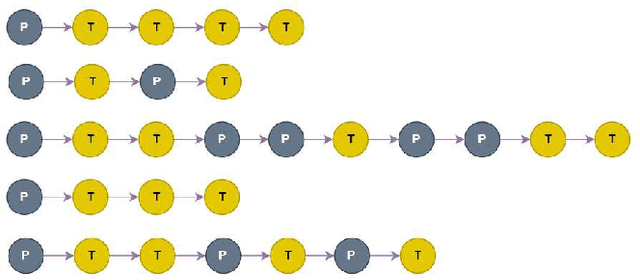

Social media platforms, including X, Facebook, and Instagram, host millions of daily users, giving rise to bots-automated programs disseminating misinformation and ideologies with tangible real-world consequences. While bot detection in platform X has been the area of many deep learning models with adequate results, most approaches neglect the graph structure of social media relationships and often rely on hand-engineered architectures. Our work introduces the implementation of a Neural Architecture Search (NAS) technique, namely Deep and Flexible Graph Neural Architecture Search (DFG-NAS), tailored to Relational Graph Convolutional Neural Networks (RGCNs) in the task of bot detection in platform X. Our model constructs a graph that incorporates both the user relationships and their metadata. Then, DFG-NAS is adapted to automatically search for the optimal configuration of Propagation and Transformation functions in the RGCNs. Our experiments are conducted on the TwiBot-20 dataset, constructing a graph with 229,580 nodes and 227,979 edges. We study the five architectures with the highest performance during the search and achieve an accuracy of 85.7%, surpassing state-of-the-art models. Our approach not only addresses the bot detection challenge but also advocates for the broader implementation of NAS models in neural network design automation.
Multimodal Detection of Social Spambots in Twitter using Transformers
Aug 28, 2023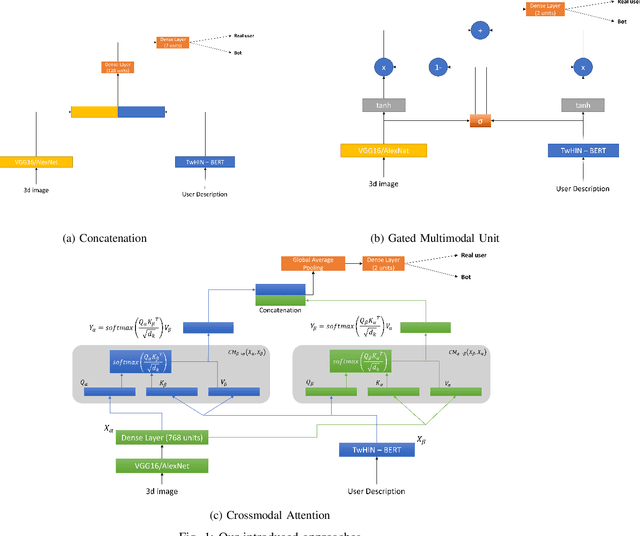
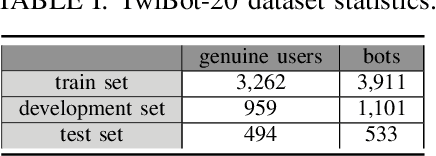
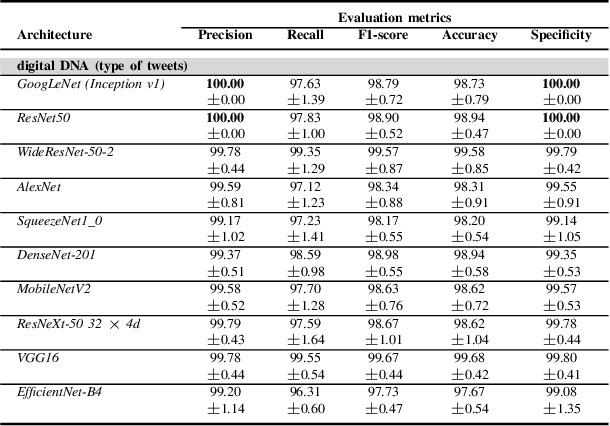
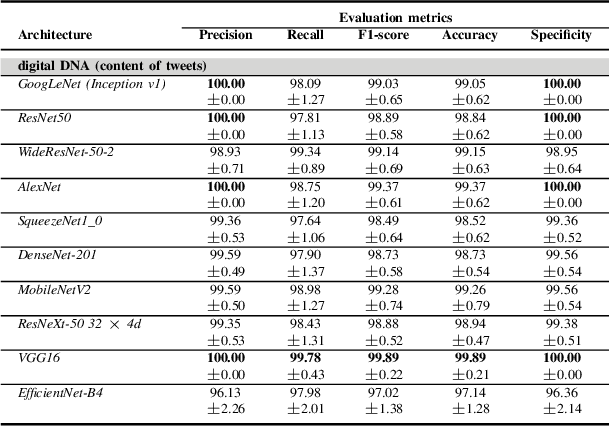
Although not all bots are malicious, the vast majority of them are responsible for spreading misinformation and manipulating the public opinion about several issues, i.e., elections and many more. Therefore, the early detection of social spambots is crucial. Although there have been proposed methods for detecting bots in social media, there are still substantial limitations. For instance, existing research initiatives still extract a large number of features and train traditional machine learning algorithms or use GloVe embeddings and train LSTMs. However, feature extraction is a tedious procedure demanding domain expertise. Also, language models based on transformers have been proved to be better than LSTMs. Other approaches create large graphs and train graph neural networks requiring in this way many hours for training and access to computational resources. To tackle these limitations, this is the first study employing only the user description field and images of three channels denoting the type and content of tweets posted by the users. Firstly, we create digital DNA sequences, transform them to 3d images, and apply pretrained models of the vision domain, including EfficientNet, AlexNet, VGG16, etc. Next, we propose a multimodal approach, where we use TwHIN-BERT for getting the textual representation of the user description field and employ VGG16 for acquiring the visual representation for the image modality. We propose three different fusion methods, namely concatenation, gated multimodal unit, and crossmodal attention, for fusing the different modalities and compare their performances. Extensive experiments conducted on the Cresci '17 dataset demonstrate valuable advantages of our introduced approaches over state-of-the-art ones reaching Accuracy up to 99.98%.
Multitask learning for recognizing stress and depression in social media
May 30, 2023



Stress and depression are prevalent nowadays across people of all ages due to the quick paces of life. People use social media to express their feelings. Thus, social media constitute a valuable form of information for the early detection of stress and depression. Although many research works have been introduced targeting the early recognition of stress and depression, there are still limitations. There have been proposed multi-task learning settings, which use depression and emotion (or figurative language) as the primary and auxiliary tasks respectively. However, although stress is inextricably linked with depression, researchers face these two tasks as two separate tasks. To address these limitations, we present the first study, which exploits two different datasets collected under different conditions, and introduce two multitask learning frameworks, which use depression and stress as the main and auxiliary tasks respectively. Specifically, we use a depression dataset and a stressful dataset including stressful posts from ten subreddits of five domains. In terms of the first approach, each post passes through a shared BERT layer, which is updated by both tasks. Next, two separate BERT encoder layers are exploited, which are updated by each task separately. Regarding the second approach, it consists of shared and task-specific layers weighted by attention fusion networks. We conduct a series of experiments and compare our approaches with existing research initiatives, single-task learning, and transfer learning. Experiments show multiple advantages of our approaches over state-of-the-art ones.
Calibration of Transformer-based Models for Identifying Stress and Depression in Social Media
May 26, 2023
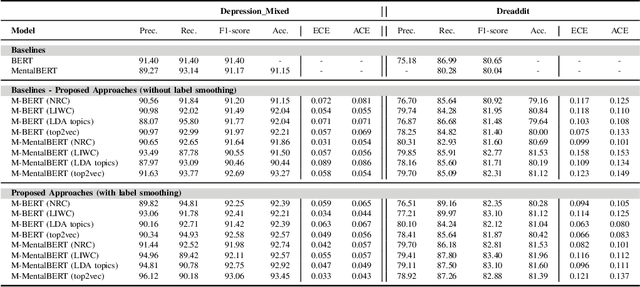
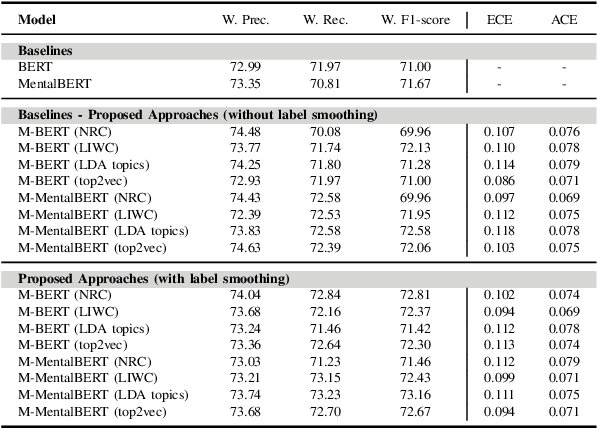
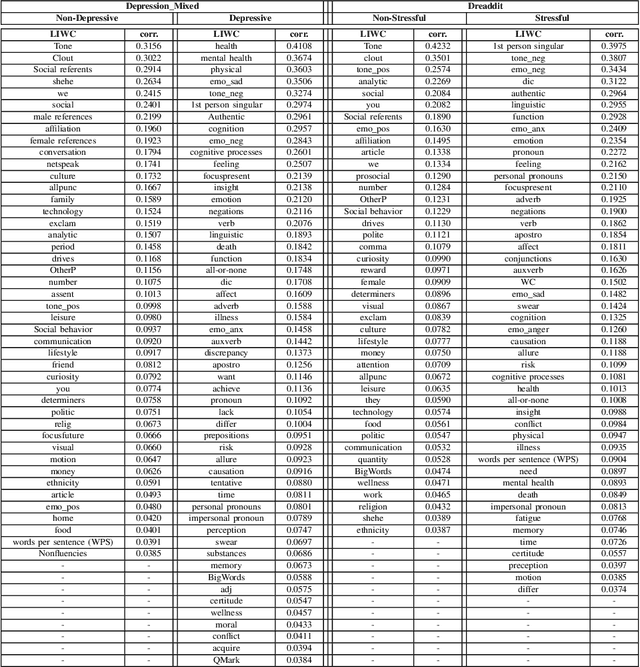
In today's fast-paced world, the rates of stress and depression present a surge. Social media provide assistance for the early detection of mental health conditions. Existing methods mainly introduce feature extraction approaches and train shallow machine learning classifiers. Other researches use deep neural networks or transformers. Despite the fact that transformer-based models achieve noticeable improvements, they cannot often capture rich factual knowledge. Although there have been proposed a number of studies aiming to enhance the pretrained transformer-based models with extra information or additional modalities, no prior work has exploited these modifications for detecting stress and depression through social media. In addition, although the reliability of a machine learning model's confidence in its predictions is critical for high-risk applications, there is no prior work taken into consideration the model calibration. To resolve the above issues, we present the first study in the task of depression and stress detection in social media, which injects extra linguistic information in transformer-based models, namely BERT and MentalBERT. Specifically, the proposed approach employs a Multimodal Adaptation Gate for creating the combined embeddings, which are given as input to a BERT (or MentalBERT) model. For taking into account the model calibration, we apply label smoothing. We test our proposed approaches in three publicly available datasets and demonstrate that the integration of linguistic features into transformer-based models presents a surge in the performance. Also, the usage of label smoothing contributes to both the improvement of the model's performance and the calibration of the model. We finally perform a linguistic analysis of the posts and show differences in language between stressful and non-stressful texts, as well as depressive and non-depressive posts.
Context-Aware Attention Layers coupled with Optimal Transport Domain Adaptation methods for recognizing dementia from spontaneous speech
May 25, 2023



Alzheimer's disease (AD) constitutes a complex neurocognitive disease and is the main cause of dementia. Although many studies have been proposed targeting at diagnosing dementia through spontaneous speech, there are still limitations. Existing state-of-the-art approaches, which propose multimodal methods, train separately language and acoustic models, employ majority-vote approaches, and concatenate the representations of the different modalities either at the input level, i.e., early fusion, or during training. Also, some of them employ self-attention layers, which calculate the dependencies between representations without considering the contextual information. In addition, no prior work has taken into consideration the model calibration. To address these limitations, we propose some new methods for detecting AD patients, which capture the intra- and cross-modal interactions. First, we convert the audio files into log-Mel spectrograms, their delta, and delta-delta and create in this way an image per audio file consisting of three channels. Next, we pass each transcript and image through BERT and DeiT models respectively. After that, context-based self-attention layers, self-attention layers with a gate model, and optimal transport domain adaptation methods are employed for capturing the intra- and inter-modal interactions. Finally, we exploit two methods for fusing the self and cross-attended features. For taking into account the model calibration, we apply label smoothing. We use both performance and calibration metrics. Experiments conducted on the ADReSS Challenge dataset indicate the efficacy of our introduced approaches over existing research initiatives with our best performing model reaching Accuracy and F1-score up to 91.25% and 91.06% respectively.
Neural Architecture Search with Multimodal Fusion Methods for Diagnosing Dementia
Feb 12, 2023


Alzheimer's dementia (AD) affects memory, thinking, and language, deteriorating person's life. An early diagnosis is very important as it enables the person to receive medical help and ensure quality of life. Therefore, leveraging spontaneous speech in conjunction with machine learning methods for recognizing AD patients has emerged into a hot topic. Most of the previous works employ Convolutional Neural Networks (CNNs), to process the input signal. However, finding a CNN architecture is a time-consuming process and requires domain expertise. Moreover, the researchers introduce early and late fusion approaches for fusing different modalities or concatenate the representations of the different modalities during training, thus the inter-modal interactions are not captured. To tackle these limitations, first we exploit a Neural Architecture Search (NAS) method to automatically find a high performing CNN architecture. Next, we exploit several fusion methods, including Multimodal Factorized Bilinear Pooling and Tucker Decomposition, to combine both speech and text modalities. To the best of our knowledge, there is no prior work exploiting a NAS approach and these fusion methods in the task of dementia detection from spontaneous speech. We perform extensive experiments on the ADReSS Challenge dataset and show the effectiveness of our approach over state-of-the-art methods.