 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Approach for Dementia Detection from Spontaneous Speech with Tensor Fusion Layer
Paper and Code
Nov 08, 2022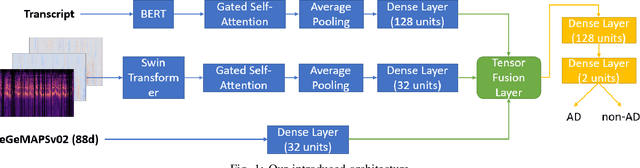
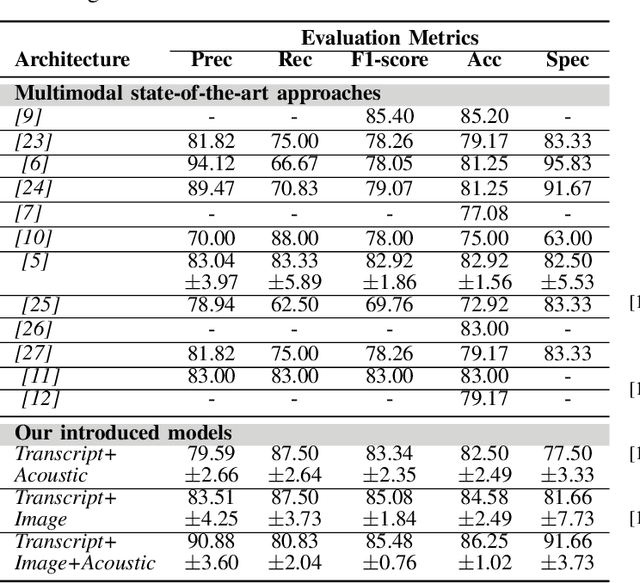
Alzheimer's disease (AD) is a progressive neurological disorder, meaning that the symptoms develop gradually throughout the years. It is also the main cause of dementia, which affects memory, thinking skills, and mental abilities. Nowadays, researchers have moved their interest towards AD detection from spontaneous speech, since it constitutes a time-effective procedure. However, existing state-of-the-art works proposing multimodal approaches do not take into consideration the inter- and intra-modal interactions and propose early and late fusion approaches. To tackle these limitations, we propose deep neural networks, which can be trained in an end-to-end trainable way and capture the inter- and intra-modal interactions. Firstly, each audio file is converted to an image consisting of three channels, i.e., log-Mel spectrogram, delta, and delta-delta. Next, each transcript is passed through a BERT model followed by a gated self-attention layer. Similarly, each image is passed through a Swin Transformer followed by an independent gated self-attention layer. Acoustic features are extracted also from each audio file. Finally, the representation vectors from the different modalities are fed to a tensor fusion layer for capturing the inter-modal interactions. Extensive experiments conducted on the ADReSS Challenge dataset indicate that our introduced approaches obtain valuable advantages over existing research initiatives reaching Accuracy and F1-score up to 86.25% and 85.48% respectively.