 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Graph Neural Architecture Search Approach for Identifying Bots in Social Media
Nov 25, 2024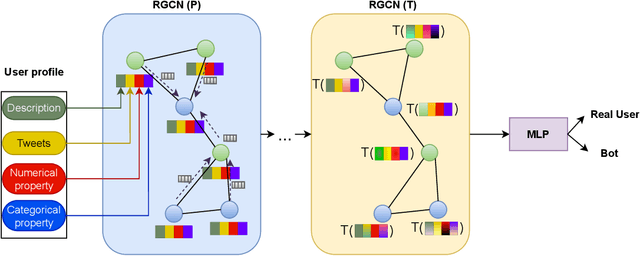
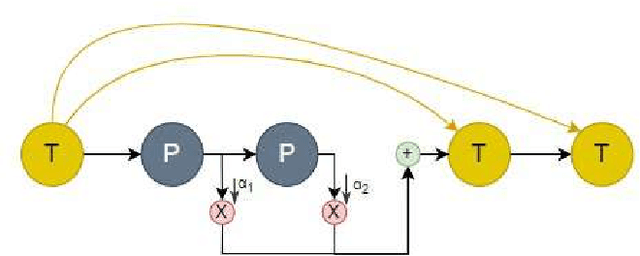
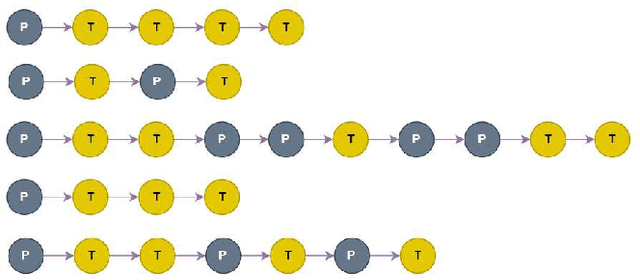

Social media platforms, including X, Facebook, and Instagram, host millions of daily users, giving rise to bots-automated programs disseminating misinformation and ideologies with tangible real-world consequences. While bot detection in platform X has been the area of many deep learning models with adequate results, most approaches neglect the graph structure of social media relationships and often rely on hand-engineered architectures. Our work introduces the implementation of a Neural Architecture Search (NAS) technique, namely Deep and Flexible Graph Neural Architecture Search (DFG-NAS), tailored to Relational Graph Convolutional Neural Networks (RGCNs) in the task of bot detection in platform X. Our model constructs a graph that incorporates both the user relationships and their metadata. Then, DFG-NAS is adapted to automatically search for the optimal configuration of Propagation and Transformation functions in the RGCNs. Our experiments are conducted on the TwiBot-20 dataset, constructing a graph with 229,580 nodes and 227,979 edges. We study the five architectures with the highest performance during the search and achieve an accuracy of 85.7%, surpassing state-of-the-art models. Our approach not only addresses the bot detection challenge but also advocates for the broader implementation of NAS models in neural network design automation.
Transfer learning for day-ahead load forecasting: a case study on European national electricity demand time series
Oct 24, 2023Short-term load forecasting (STLF) is crucial for the daily operation of power grids. However, the non-linearity, non-stationarity, and randomness characterizing electricity demand time series renders STLF a challenging task. Various forecasting approaches have been proposed for improving STLF, including neural network (NN) models which are trained using data from multiple electricity demand series that may not necessary include the target series. In the present study, we investigate the performance of this special case of STLF, called transfer learning (TL), by considering a set of 27 time series that represent the national day-ahead electricity demand of indicative European countries. We employ a popular and easy-to-implement NN model and perform a clustering analysis to identify similar patterns among the series and assist TL. In this context, two different TL approaches, with and without the clustering step, are compiled and compared against each other as well as a typical NN training setup. Our results demonstrate that TL can outperform the conventional approach, especially when clustering techniques are considered.
In Search of Deep Learning Architectures for Load Forecasting: A Comparative Analysis and the Impact of the Covid-19 Pandemic on Model Performance
Feb 25, 2023In power grids, short-term load forecasting (STLF) is crucial as it contributes to the optimization of their reliability, emissions, and costs, while it enables the participation of energy companies in the energy market. STLF is a challenging task, due to the complex demand of active and reactive power from multiple types of electrical loads and their dependence on numerous exogenous variables. Amongst them, special circumstances, such as the COVID-19 pandemic, can often be the reason behind distribution shifts of load series. This work conducts a comparative study of Deep Learning (DL) architectures, namely Neural Basis Expansion Analysis Time Series Forecasting (N-BEATS), Long Short-Term Memory (LSTM), and Temporal Convolutional Networks (TCN), with respect to forecasting accuracy and training sustainability, meanwhile examining their out-of-distribution generalization capabilities during the COVID-19 pandemic era. A Pattern Sequence Forecasting (PSF) model is used as baseline. The case study focuses on day-ahead forecasts for the Portuguese national 15-minute resolution net load time series. The results can be leveraged by energy companies and network operators (i) to reinforce their forecasting toolkit with state-of-the-art DL models; (ii) to become aware of the serious consequences of crisis events on model performance; (iii) as a high-level model evaluation, deployment, and sustainability guide within a smart grid context.
A Multimodal Approach for Dementia Detection from Spontaneous Speech with Tensor Fusion Layer
Nov 08, 2022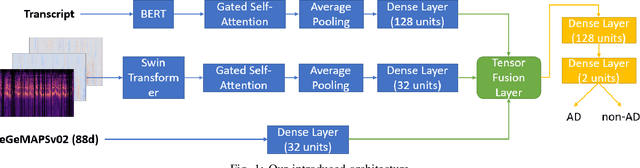
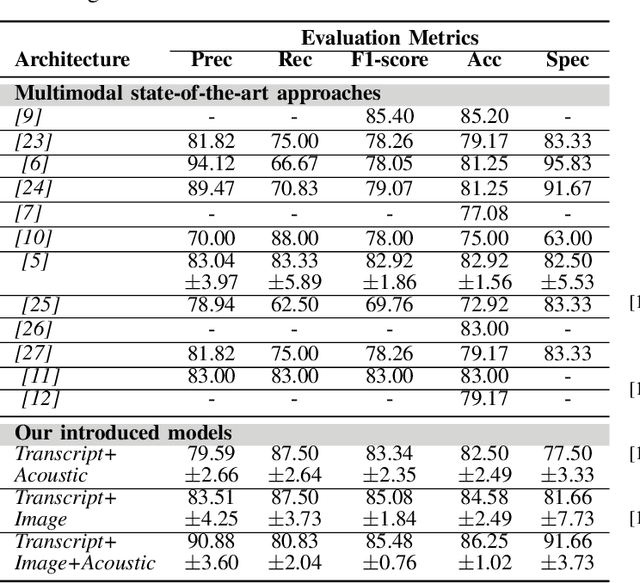
Alzheimer's disease (AD) is a progressive neurological disorder, meaning that the symptoms develop gradually throughout the years. It is also the main cause of dementia, which affects memory, thinking skills, and mental abilities. Nowadays, researchers have moved their interest towards AD detection from spontaneous speech, since it constitutes a time-effective procedure. However, existing state-of-the-art works proposing multimodal approaches do not take into consideration the inter- and intra-modal interactions and propose early and late fusion approaches. To tackle these limitations, we propose deep neural networks, which can be trained in an end-to-end trainable way and capture the inter- and intra-modal interactions. Firstly, each audio file is converted to an image consisting of three channels, i.e., log-Mel spectrogram, delta, and delta-delta. Next, each transcript is passed through a BERT model followed by a gated self-attention layer. Similarly, each image is passed through a Swin Transformer followed by an independent gated self-attention layer. Acoustic features are extracted also from each audio file. Finally, the representation vectors from the different modalities are fed to a tensor fusion layer for capturing the inter-modal interactions. Extensive experiments conducted on the ADReSS Challenge dataset indicate that our introduced approaches obtain valuable advantages over existing research initiatives reaching Accuracy and F1-score up to 86.25% and 85.48% respectively.
Detecting Dementia from Speech and Transcripts using Transformers
Oct 27, 2021

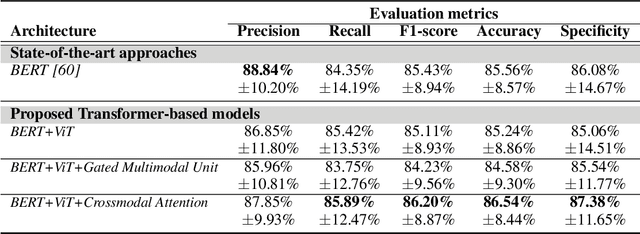
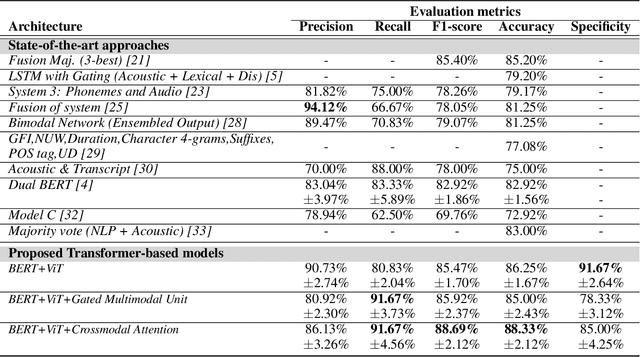
Alzheimer's disease (AD) constitutes a neurodegenerative disease with serious consequences to peoples' everyday lives, if it is not diagnosed early since there is no available cure. Because of the cost of examinations for diagnosing dementia, i.e., Magnetic Resonance Imaging (MRI), electroencephalogram (EEG) signals etc., current work has been focused on diagnosing dementia from spontaneous speech. However, little work has been done regarding the conversion of speech data to Log-Mel spectrograms and Mel-frequency cepstral coefficients (MFCCs) and the usage of pretrained models. Concurrently, little work has been done in terms of both the usage of transformer networks and the way the two modalities, i.e., speech and transcripts, are combined in a single neural network. To address these limitations, first we employ several pretrained models, with Vision Transformer (ViT) achieving the highest evaluation results. Secondly, we propose multimodal models. More specifically, our introduced models include Gated Multimodal Unit in order to control the influence of each modality towards the final classification and crossmodal attention so as to capture in an effective way the relationships between the two modalities. Extensive experiments conducted on the ADReSS Challenge dataset demonstrate the effectiveness of the proposed models and their superiority over state-of-the-art approaches.